 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking with Comics: Enhancing Multimodal Reasoning through Structured Visual Storytelling
Feb 03, 2026Chain-of-Thought reasoning has driven large language models to extend from thinking with text to thinking with images and videos. However, different modalities still have clear limitations: static images struggle to represent temporal structure, while videos introduce substantial redundancy and computational cost. In this work, we propose Thinking with Comics, a visual reasoning paradigm that uses comics as a high information-density medium positioned between images and videos. Comics preserve temporal structure, embedded text, and narrative coherence while requiring significantly lower reasoning cost. We systematically study two reasoning paths based on comics and evaluate them on a range of reasoning tasks and long-context understanding tasks. Experimental results show that Thinking with Comics outperforms Thinking with Images on multi-step temporal and causal reasoning tasks, while remaining substantially more efficient than Thinking with Video. Further analysis indicates that different comic narrative structures and styles consistently affect performance across tasks, suggesting that comics serve as an effective intermediate visual representation for improving multimodal reasoning.
From Perception to Reasoning: Deep Thinking Empowers Multimodal Large Language Models
Nov 18, 2025With the remarkable success of Multimodal Large Language Models (MLLMs) in perception tasks, enhancing their complex reasoning capabilities has emerged as a critical research focus. Existing models still suffer from challenges such as opaque reasoning paths and insufficient generalization ability. Chain-of-Thought (CoT) reasoning, which has demonstrated significant efficacy in language models by enhancing reasoning transparency and output interpretability, holds promise for improving model reasoning capabilities when extended to the multimodal domain. This paper provides a systematic review centered on "Multimodal Chain-of-Thought" (MCoT). First, it analyzes the background and theoretical motivations for its inception from the perspectives of technical evolution and task demands. Then, it introduces mainstream MCoT methods from three aspects: CoT paradigms, the post-training stage, and the inference stage, while also analyzing their underlying mechanisms. Furthermore, the paper summarizes existing evaluation benchmarks and metrics, and discusses the application scenarios of MCoT. Finally, it analyzes the challenges currently facing MCoT and provides an outlook on its future research directions.
Adaptive Inner Speech-Text Alignment for LLM-based Speech Translation
Mar 13, 2025Recent advancement of large language models (LLMs) has led to significant breakthroughs across various tasks, laying the foundation for the development of LLM-based speech translation systems. Existing methods primarily focus on aligning inputs and outputs across modalities while overlooking deeper semantic alignment within model representations. To address this limitation, we propose an Adaptive Inner Speech-Text Alignment (AI-STA) method to bridge the modality gap by explicitly aligning speech and text representations at selected layers within LLMs. To achieve this, we leverage the optimal transport (OT) theory to quantify fine-grained representation discrepancies between speech and text. Furthermore, we utilize the cross-modal retrieval technique to identify the layers that are best suited for alignment and perform joint training on these layers. Experimental results on speech translation (ST) tasks demonstrate that AI-STA significantly improves the translation performance of large speech-text models (LSMs), outperforming previous state-of-the-art approaches. Our findings highlight the importance of inner-layer speech-text alignment in LLMs and provide new insights into enhancing cross-modal learning.
Evaluating o1-Like LLMs: Unlocking Reasoning for Translation through Comprehensive Analysis
Feb 17, 2025
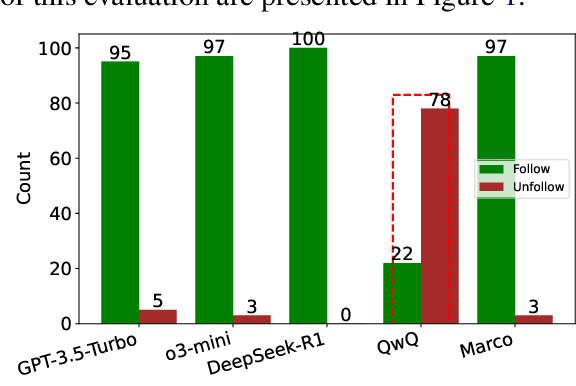


The o1-Like LLMs are transforming AI by simulating human cognitive processes, but their performance in multilingual machine translation (MMT) remains underexplored. This study examines: (1) how o1-Like LLMs perform in MMT tasks and (2) what factors influence their translation quality. We evaluate multiple o1-Like LLMs and compare them with traditional models like ChatGPT and GPT-4o. Results show that o1-Like LLMs establish new multilingual translation benchmarks, with DeepSeek-R1 surpassing GPT-4o in contextless tasks. They demonstrate strengths in historical and cultural translation but exhibit a tendency for rambling issues in Chinese-centric outputs. Further analysis reveals three key insights: (1) High inference costs and slower processing speeds make complex translation tasks more resource-intensive. (2) Translation quality improves with model size, enhancing commonsense reasoning and cultural translation. (3) The temperature parameter significantly impacts output quality-lower temperatures yield more stable and accurate translations, while higher temperatures reduce coherence and precision.
Make Imagination Clearer! Stable Diffusion-based Visual Imagination for Multimodal Machine Translation
Dec 17, 2024



Visual information has been introduced for enhancing machine translation (MT), and its effectiveness heavily relies on the availability of large amounts of bilingual parallel sentence pairs with manual image annotations. In this paper, we introduce a stable diffusion-based imagination network into a multimodal large language model (MLLM) to explicitly generate an image for each source sentence, thereby advancing the multimodel MT. Particularly, we build heuristic human feedback with reinforcement learning to ensure the consistency of the generated image with the source sentence without the supervision of image annotation, which breaks the bottleneck of using visual information in MT. Furthermore, the proposed method enables imaginative visual information to be integrated into large-scale text-only MT in addition to multimodal MT. Experimental results show that our model significantly outperforms existing multimodal MT and text-only MT, especially achieving an average improvement of more than 14 BLEU points on Multi30K multimodal MT benchmarks.
LLM-based Translation Inference with Iterative Bilingual Understanding
Oct 17, 2024



The remarkable understanding and generation capabilities of large language models (LLMs) have greatly improved translation performance. However, incorrect understanding of the sentence to be translated can degrade translation quality. To address this issue, we proposed a novel Iterative Bilingual Understanding Translation (IBUT) method based on the cross-lingual capabilities of LLMs and the dual characteristics of translation tasks. The cross-lingual capability of LLMs enables the generation of contextual understanding for both the source and target languages separately. Furthermore, the dual characteristics allow IBUT to generate effective cross-lingual feedback, iteratively refining contextual understanding, thereby reducing errors and improving translation performance. Experimental results showed that the proposed IBUT outperforms several strong comparison methods, especially being generalized to multiple domains (e.g., news, commonsense, and cultural translation benchmarks).
Benchmarking LLMs for Translating Classical Chinese Poetry:Evaluating Adequacy, Fluency, and Elegance
Aug 19, 2024Large language models (LLMs) have shown remarkable performance in general translation tasks. However, the increasing demand for high-quality translations that are not only adequate but also fluent and elegant. To assess the extent to which current LLMs can meet these demands, we introduce a suitable benchmark for translating classical Chinese poetry into English. This task requires not only adequacy in translating culturally and historically significant content but also a strict adherence to linguistic fluency and poetic elegance. Our study reveals that existing LLMs fall short of this task. To address these issues, we propose RAT, a \textbf{R}etrieval-\textbf{A}ugmented machine \textbf{T}ranslation method that enhances the translation process by incorporating knowledge related to classical poetry. Additionally, we propose an automatic evaluation metric based on GPT-4, which better assesses translation quality in terms of adequacy, fluency, and elegance, overcoming the limitations of traditional metrics. Our dataset and code will be made available.
DUAL-REFLECT: Enhancing Large Language Models for Reflective Translation through Dual Learning Feedback Mechanisms
Jun 11, 2024Recently, large language models (LLMs) enhanced by self-reflection have achieved promising performance on machine translation. The key idea is guiding LLMs to generate translation with human-like feedback. However, existing self-reflection methods lack effective feedback information, limiting the translation performance. To address this, we introduce a DUAL-REFLECT framework, leveraging the dual learning of translation tasks to provide effective feedback, thereby enhancing the models' self-reflective abilities and improving translation performance. The application of this method across various translation tasks has proven its effectiveness in improving translation accuracy and eliminating ambiguities, especially in translation tasks with low-resource language pairs.