 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking with Comics: Enhancing Multimodal Reasoning through Structured Visual Storytelling
Feb 03, 2026Chain-of-Thought reasoning has driven large language models to extend from thinking with text to thinking with images and videos. However, different modalities still have clear limitations: static images struggle to represent temporal structure, while videos introduce substantial redundancy and computational cost. In this work, we propose Thinking with Comics, a visual reasoning paradigm that uses comics as a high information-density medium positioned between images and videos. Comics preserve temporal structure, embedded text, and narrative coherence while requiring significantly lower reasoning cost. We systematically study two reasoning paths based on comics and evaluate them on a range of reasoning tasks and long-context understanding tasks. Experimental results show that Thinking with Comics outperforms Thinking with Images on multi-step temporal and causal reasoning tasks, while remaining substantially more efficient than Thinking with Video. Further analysis indicates that different comic narrative structures and styles consistently affect performance across tasks, suggesting that comics serve as an effective intermediate visual representation for improving multimodal reasoning.
From Perception to Reasoning: Deep Thinking Empowers Multimodal Large Language Models
Nov 18, 2025With the remarkable success of Multimodal Large Language Models (MLLMs) in perception tasks, enhancing their complex reasoning capabilities has emerged as a critical research focus. Existing models still suffer from challenges such as opaque reasoning paths and insufficient generalization ability. Chain-of-Thought (CoT) reasoning, which has demonstrated significant efficacy in language models by enhancing reasoning transparency and output interpretability, holds promise for improving model reasoning capabilities when extended to the multimodal domain. This paper provides a systematic review centered on "Multimodal Chain-of-Thought" (MCoT). First, it analyzes the background and theoretical motivations for its inception from the perspectives of technical evolution and task demands. Then, it introduces mainstream MCoT methods from three aspects: CoT paradigms, the post-training stage, and the inference stage, while also analyzing their underlying mechanisms. Furthermore, the paper summarizes existing evaluation benchmarks and metrics, and discusses the application scenarios of MCoT. Finally, it analyzes the challenges currently facing MCoT and provides an outlook on its future research directions.
M3: 3D-Spatial MultiModal Memory
Mar 20, 2025We present 3D Spatial MultiModal Memory (M3), a multimodal memory system designed to retain information about medium-sized static scenes through video sources for visual perception. By integrating 3D Gaussian Splatting techniques with foundation models, M3 builds a multimodal memory capable of rendering feature representations across granularities, encompassing a wide range of knowledge. In our exploration, we identify two key challenges in previous works on feature splatting: (1) computational constraints in storing high-dimensional features for each Gaussian primitive, and (2) misalignment or information loss between distilled features and foundation model features. To address these challenges, we propose M3 with key components of principal scene components and Gaussian memory attention, enabling efficient training and inference. To validate M3, we conduct comprehensive quantitative evaluations of feature similarity and downstream tasks, as well as qualitative visualizations to highlight the pixel trace of Gaussian memory attention. Our approach encompasses a diverse range of foundation models, including vision-language models (VLMs), perception models, and large multimodal and language models (LMMs/LLMs). Furthermore, to demonstrate real-world applicability, we deploy M3's feature field in indoor scenes on a quadruped robot. Notably, we claim that M3 is the first work to address the core compression challenges in 3D feature distillation.
Evaluating o1-Like LLMs: Unlocking Reasoning for Translation through Comprehensive Analysis
Feb 17, 2025
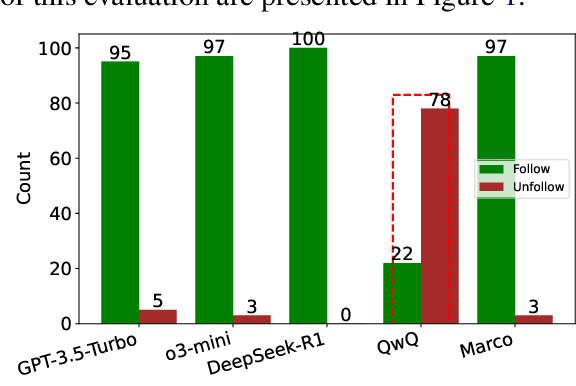


The o1-Like LLMs are transforming AI by simulating human cognitive processes, but their performance in multilingual machine translation (MMT) remains underexplored. This study examines: (1) how o1-Like LLMs perform in MMT tasks and (2) what factors influence their translation quality. We evaluate multiple o1-Like LLMs and compare them with traditional models like ChatGPT and GPT-4o. Results show that o1-Like LLMs establish new multilingual translation benchmarks, with DeepSeek-R1 surpassing GPT-4o in contextless tasks. They demonstrate strengths in historical and cultural translation but exhibit a tendency for rambling issues in Chinese-centric outputs. Further analysis reveals three key insights: (1) High inference costs and slower processing speeds make complex translation tasks more resource-intensive. (2) Translation quality improves with model size, enhancing commonsense reasoning and cultural translation. (3) The temperature parameter significantly impacts output quality-lower temperatures yield more stable and accurate translations, while higher temperatures reduce coherence and precision.
Make Imagination Clearer! Stable Diffusion-based Visual Imagination for Multimodal Machine Translation
Dec 17, 2024



Visual information has been introduced for enhancing machine translation (MT), and its effectiveness heavily relies on the availability of large amounts of bilingual parallel sentence pairs with manual image annotations. In this paper, we introduce a stable diffusion-based imagination network into a multimodal large language model (MLLM) to explicitly generate an image for each source sentence, thereby advancing the multimodel MT. Particularly, we build heuristic human feedback with reinforcement learning to ensure the consistency of the generated image with the source sentence without the supervision of image annotation, which breaks the bottleneck of using visual information in MT. Furthermore, the proposed method enables imaginative visual information to be integrated into large-scale text-only MT in addition to multimodal MT. Experimental results show that our model significantly outperforms existing multimodal MT and text-only MT, especially achieving an average improvement of more than 14 BLEU points on Multi30K multimodal MT benchmarks.
Noro: A Noise-Robust One-shot Voice Conversion System with Hidden Speaker Representation Capabilities
Nov 29, 2024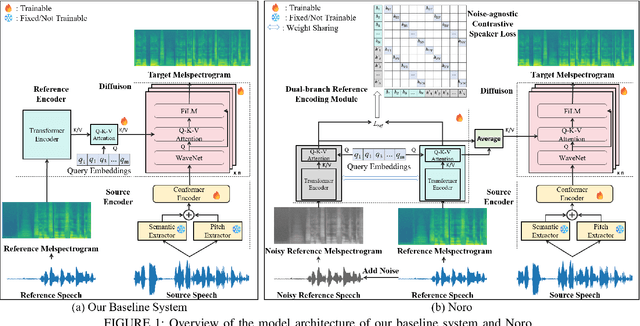
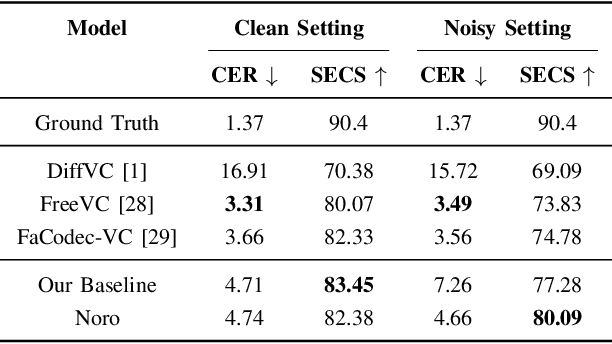

One-shot voice conversion (VC) aims to alter the timbre of speech from a source speaker to match that of a target speaker using just a single reference speech from the target, while preserving the semantic content of the original source speech. Despite advancements in one-shot VC, its effectiveness decreases in real-world scenarios where reference speeches, often sourced from the internet, contain various disturbances like background noise. To address this issue, we introduce Noro, a Noise Robust One-shot VC system. Noro features innovative components tailored for VC using noisy reference speeches, including a dual-branch reference encoding module and a noise-agnostic contrastive speaker loss. Experimental results demonstrate that Noro outperforms our baseline system in both clean and noisy scenarios, highlighting its efficacy for real-world applications. Additionally, we investigate the hidden speaker representation capabilities of our baseline system by repurposing its reference encoder as a speaker encoder. The results shows that it is competitive with several advanced self-supervised learning models for speaker representation under the SUPERB settings, highlighting the potential for advancing speaker representation learning through one-shot VC task.
WildLMa: Long Horizon Loco-Manipulation in the Wild
Nov 22, 2024



`In-the-wild' mobile manipulation aims to deploy robots in diverse real-world environments, which requires the robot to (1) have skills that generalize across object configurations; (2) be capable of long-horizon task execution in diverse environments; and (3) perform complex manipulation beyond pick-and-place. Quadruped robots with manipulators hold promise for extending the workspace and enabling robust locomotion, but existing results do not investigate such a capability. This paper proposes WildLMa with three components to address these issues: (1) adaptation of learned low-level controller for VR-enabled whole-body teleoperation and traversability; (2) WildLMa-Skill -- a library of generalizable visuomotor skills acquired via imitation learning or heuristics and (3) WildLMa-Planner -- an interface of learned skills that allow LLM planners to coordinate skills for long-horizon tasks. We demonstrate the importance of high-quality training data by achieving higher grasping success rate over existing RL baselines using only tens of demonstrations. WildLMa exploits CLIP for language-conditioned imitation learning that empirically generalizes to objects unseen in training demonstrations. Besides extensive quantitative evaluation, we qualitatively demonstrate practical robot applications, such as cleaning up trash in university hallways or outdoor terrains, operating articulated objects, and rearranging items on a bookshelf.
Optimal camera-robot pose estimation in linear time from points and lines
Jul 23, 2024Camera pose estimation is a fundamental problem in robotics. This paper focuses on two issues of interest: First, point and line features have complementary advantages, and it is of great value to design a uniform algorithm that can fuse them effectively; Second, with the development of modern front-end techniques, a large number of features can exist in a single image, which presents a potential for highly accurate robot pose estimation. With these observations, we propose AOPnP(L), an optimal linear-time camera-robot pose estimation algorithm from points and lines. Specifically, we represent a line with two distinct points on it and unify the noise model for point and line measurements where noises are added to 2D points in the image. By utilizing Plucker coordinates for line parameterization, we formulate a maximum likelihood (ML) problem for combined point and line measurements. To optimally solve the ML problem, AOPnP(L) adopts a two-step estimation scheme. In the first step, a consistent estimate that can converge to the true pose is devised by virtue of bias elimination. In the second step, a single Gauss-Newton iteration is executed to refine the initial estimate. AOPnP(L) features theoretical optimality in the sense that its mean squared error converges to the Cramer-Rao lower bound. Moreover, it owns a linear time complexity. These properties make it well-suited for precision-demanding and real-time robot pose estimation. Extensive experiments are conducted to validate our theoretical developments and demonstrate the superiority of AOPnP(L) in both static localization and dynamic odometry systems.
Learning Generalizable Feature Fields for Mobile Manipulation
Mar 12, 2024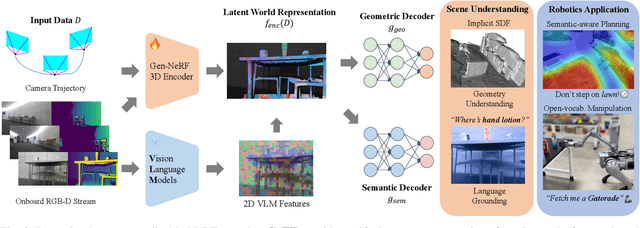


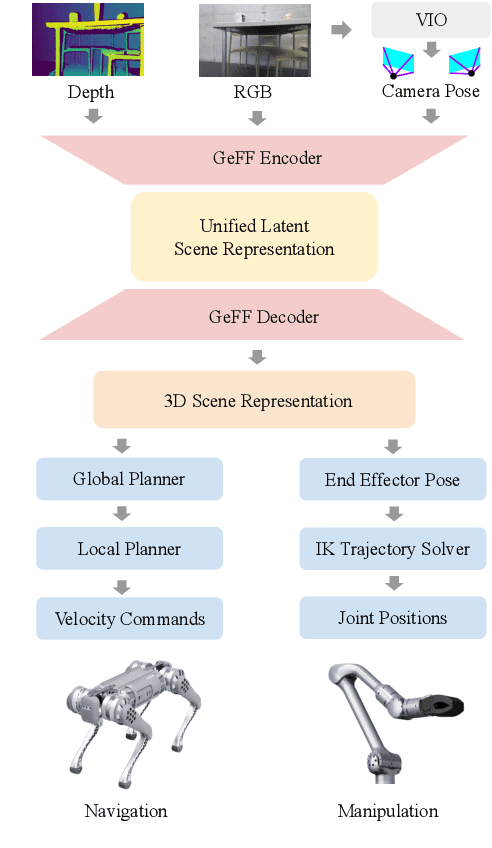
An open problem in mobile manipulation is how to represent objects and scenes in a unified manner, so that robots can use it both for navigating in the environment and manipulating objects. The latter requires capturing intricate geometry while understanding fine-grained semantics, whereas the former involves capturing the complexity inherit to an expansive physical scale. In this work, we present GeFF (Generalizable Feature Fields), a scene-level generalizable neural feature field that acts as a unified representation for both navigation and manipulation that performs in real-time. To do so, we treat generative novel view synthesis as a pre-training task, and then align the resulting rich scene priors with natural language via CLIP feature distillation. We demonstrate the effectiveness of this approach by deploying GeFF on a quadrupedal robot equipped with a manipulator. We evaluate GeFF's ability to generalize to open-set objects as well as running time, when performing open-vocabulary mobile manipulation in dynamic scenes.
Implementing Digital Twin in Field-Deployed Optical Networks: Uncertain Factors, Operational Guidance, and Field-Trial Demonstration
Dec 06, 2023Digital twin has revolutionized optical communication networks by enabling their full life-cycle management, including design, troubleshooting, optimization, upgrade, and prediction. While extensive literature exists on frameworks, standards, and applications of digital twin, there is a pressing need in implementing digital twin in field-deployed optical networks operating in real-world environments, as opposed to controlled laboratory settings. This paper addresses this challenge by examining the uncertain factors behind the inaccuracy of digital twin in field-deployed optical networks from three main challenges and proposing operational guidance for implementing accurate digital twin in field-deployed optical networks. Through the proposed guidance, we demonstrate the effective implementation of digital twin in a field-trial C+L-band optical transmission link, showcasing its capabilities in performance recovery in a fiber cut scenario.