 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive and Clinically Accurate Head and Neck Organs at Risk Delineation via Stratified Deep Learning: A Large-scale Multi-Institutional Study
Nov 01, 2021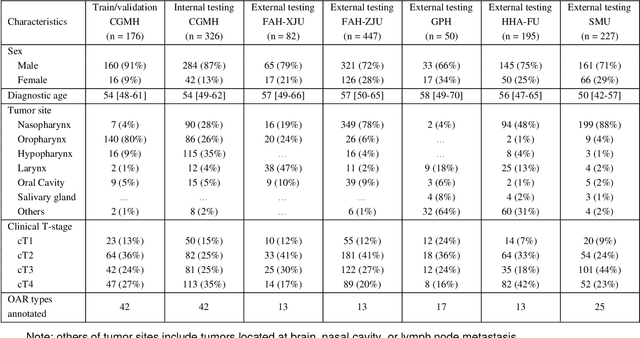
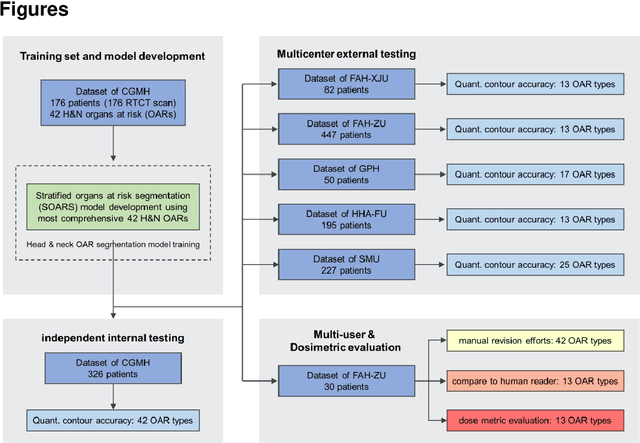
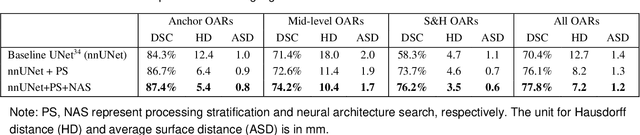
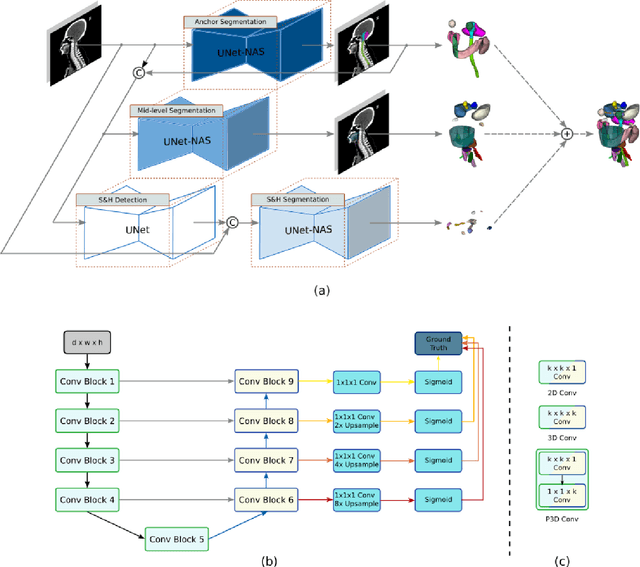
Accurate organ at risk (OAR) segmentation is critical to reduce the radiotherapy post-treatment complications. Consensus guidelines recommend a set of more than 40 OARs in the head and neck (H&N) region, however, due to the predictable prohibitive labor-cost of this task, most institutions choose a substantially simplified protocol by delineating a smaller subset of OARs and neglecting the dose distributions associated with other OARs. In this work we propose a novel, automated and highly effective stratified OAR segmentation (SOARS) system using deep learning to precisely delineate a comprehensive set of 42 H&N OARs. SOARS stratifies 42 OARs into anchor, mid-level, and small & hard subcategories, with specifically derived neural network architectures for each category by neural architecture search (NAS) principles. We built SOARS models using 176 training patients in an internal institution and independently evaluated on 1327 external patients across six different institutions. It consistently outperformed other state-of-the-art methods by at least 3-5% in Dice score for each institutional evaluation (up to 36% relative error reduction in other metrics). More importantly, extensive multi-user studies evidently demonstrated that 98% of the SOARS predictions need only very minor or no revisions for direct clinical acceptance (saving 90% radiation oncologists workload), and their segmentation and dosimetric accuracy are within or smaller than the inter-user variation. These findings confirmed the strong clinical applicability of SOARS for the OAR delineation process in H&N cancer radiotherapy workflows, with improved efficiency, comprehensiveness, and quality.
Volumetric Medical Image Segmentation: A 3D Deep Coarse-to-fine Framework and Its Adversarial Examples
Oct 29, 2020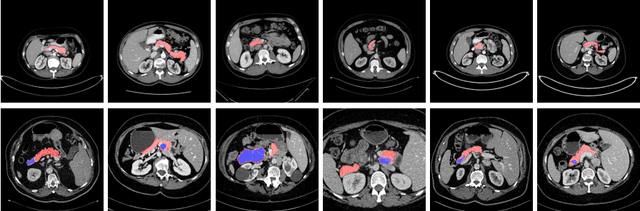
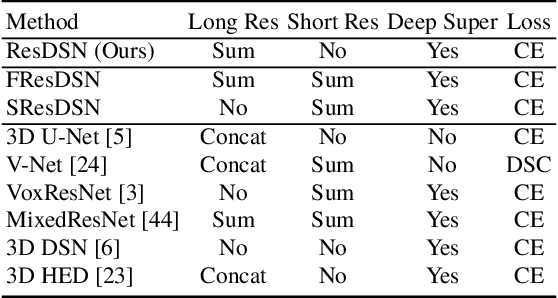

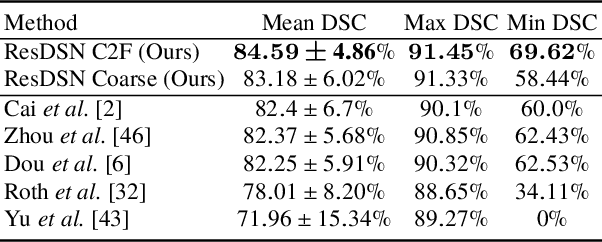
Although deep neural networks have been a dominant method for many 2D vision tasks, it is still challenging to apply them to 3D tasks, such as medical image segmentation, due to the limited amount of annotated 3D data and limited computational resources. In this chapter, by rethinking the strategy to apply 3D Convolutional Neural Networks to segment medical images, we propose a novel 3D-based coarse-to-fine framework to efficiently tackle these challenges. The proposed 3D-based framework outperforms their 2D counterparts by a large margin since it can leverage the rich spatial information along all three axes. We further analyze the threat of adversarial attacks on the proposed framework and show how to defense against the attack. We conduct experiments on three datasets, the NIH pancreas dataset, the JHMI pancreas dataset and the JHMI pathological cyst dataset, where the first two and the last one contain healthy and pathological pancreases respectively, and achieve the current state-of-the-art in terms of Dice-Sorensen Coefficient (DSC) on all of them. Especially, on the NIH pancreas segmentation dataset, we outperform the previous best by an average of over $2\%$, and the worst case is improved by $7\%$ to reach almost $70\%$, which indicates the reliability of our framework in clinical applications.
Lymph Node Gross Tumor Volume Detection in Oncology Imaging via Relationship Learning Using Graph Neural Network
Aug 29, 2020
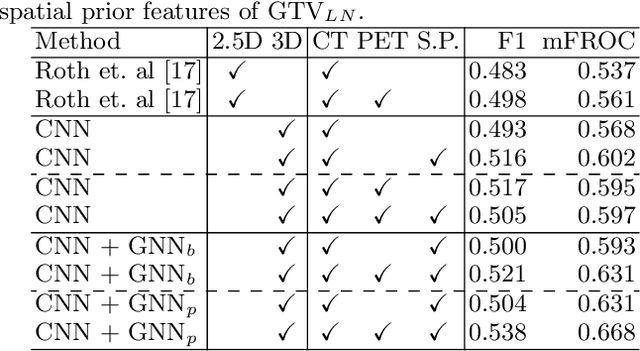
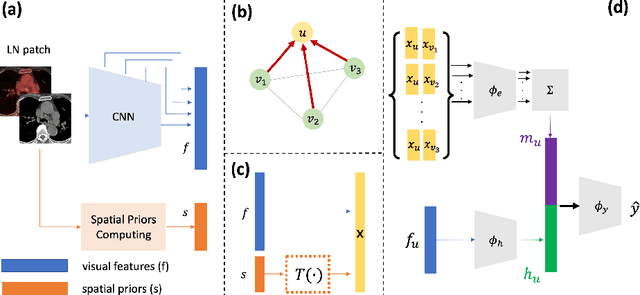
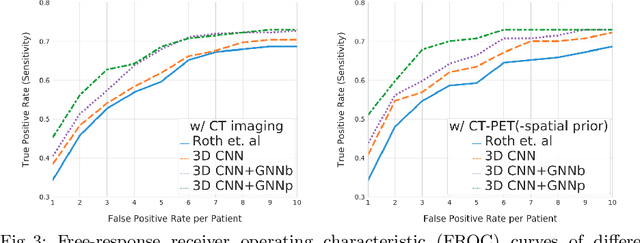
Determining the spread of GTV$_{LN}$ is essential in defining the respective resection or irradiating regions for the downstream workflows of surgical resection and radiotherapy for many cancers. Different from the more common enlarged lymph node (LN), GTV$_{LN}$ also includes smaller ones if associated with high positron emission tomography signals and/or any metastasis signs in CT. This is a daunting task. In this work, we propose a unified LN appearance and inter-LN relationship learning framework to detect the true GTV$_{LN}$. This is motivated by the prior clinical knowledge that LNs form a connected lymphatic system, and the spread of cancer cells among LNs often follows certain pathways. Specifically, we first utilize a 3D convolutional neural network with ROI-pooling to extract the GTV$_{LN}$'s instance-wise appearance features. Next, we introduce a graph neural network to further model the inter-LN relationships where the global LN-tumor spatial priors are included in the learning process. This leads to an end-to-end trainable network to detect by classifying GTV$_{LN}$. We operate our model on a set of GTV$_{LN}$ candidates generated by a preliminary 1st-stage method, which has a sensitivity of $>85\%$ at the cost of high false positive (FP) ($>15$ FPs per patient). We validate our approach on a radiotherapy dataset with 142 paired PET/RTCT scans containing the chest and upper abdominal body parts. The proposed method significantly improves over the state-of-the-art (SOTA) LN classification method by $5.5\%$ and $13.1\%$ in F1 score and the averaged sensitivity value at $2, 3, 4, 6$ FPs per patient, respectively.
Lymph Node Gross Tumor Volume Detection and Segmentation via Distance-based Gating using 3D CT/PET Imaging in Radiotherapy
Aug 27, 2020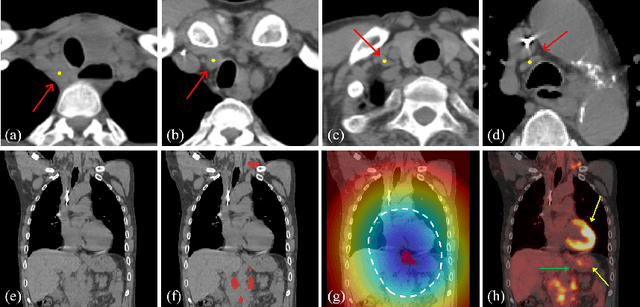
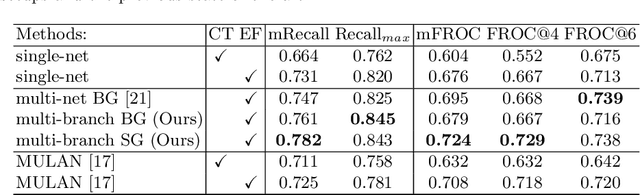
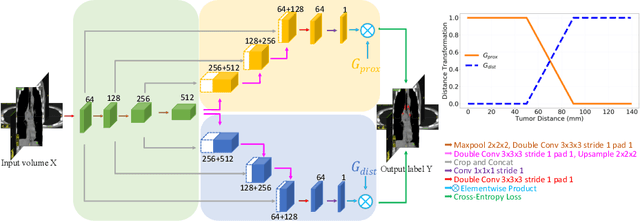
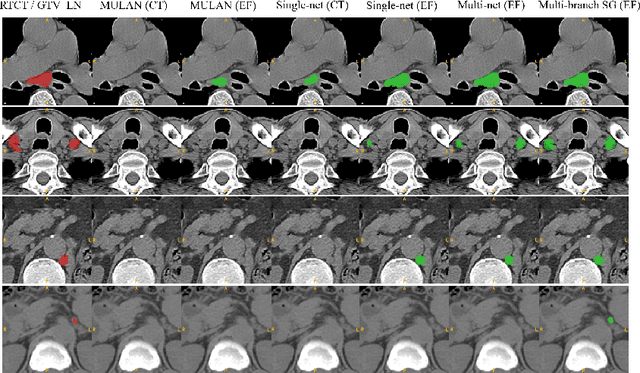
Finding, identifying and segmenting suspicious cancer metastasized lymph nodes from 3D multi-modality imaging is a clinical task of paramount importance. In radiotherapy, they are referred to as Lymph Node Gross Tumor Volume (GTVLN). Determining and delineating the spread of GTVLN is essential in defining the corresponding resection and irradiating regions for the downstream workflows of surgical resection and radiotherapy of various cancers. In this work, we propose an effective distance-based gating approach to simulate and simplify the high-level reasoning protocols conducted by radiation oncologists, in a divide-and-conquer manner. GTVLN is divided into two subgroups of tumor-proximal and tumor-distal, respectively, by means of binary or soft distance gating. This is motivated by the observation that each category can have distinct though overlapping distributions of appearance, size and other LN characteristics. A novel multi-branch detection-by-segmentation network is trained with each branch specializing on learning one GTVLN category features, and outputs from multi-branch are fused in inference. The proposed method is evaluated on an in-house dataset of $141$ esophageal cancer patients with both PET and CT imaging modalities. Our results validate significant improvements on the mean recall from $72.5\%$ to $78.2\%$, as compared to previous state-of-the-art work. The highest achieved GTVLN recall of $82.5\%$ at $20\%$ precision is clinically relevant and valuable since human observers tend to have low sensitivity (around $80\%$ for the most experienced radiation oncologists, as reported by literature).
Uncertainty-aware multi-view co-training for semi-supervised medical image segmentation and domain adaptation
Jun 28, 2020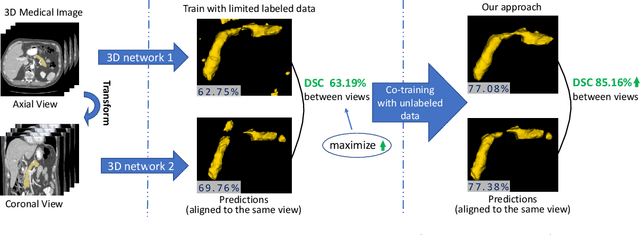
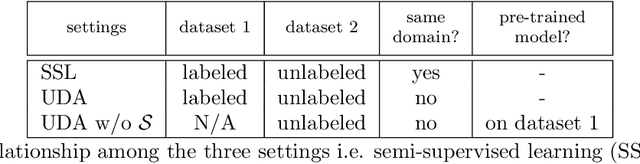
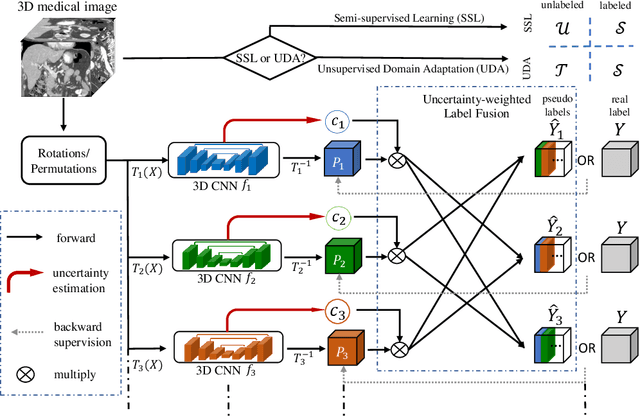
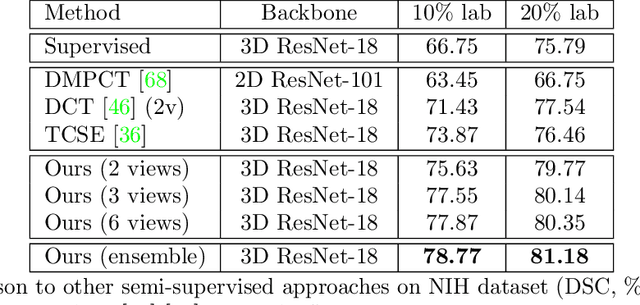
Although having achieved great success in medical image segmentation, deep learning-based approaches usually require large amounts of well-annotated data, which can be extremely expensive in the field of medical image analysis. Unlabeled data, on the other hand, is much easier to acquire. Semi-supervised learning and unsupervised domain adaptation both take the advantage of unlabeled data, and they are closely related to each other. In this paper, we propose uncertainty-aware multi-view co-training (UMCT), a unified framework that addresses these two tasks for volumetric medical image segmentation. Our framework is capable of efficiently utilizing unlabeled data for better performance. We firstly rotate and permute the 3D volumes into multiple views and train a 3D deep network on each view. We then apply co-training by enforcing multi-view consistency on unlabeled data, where an uncertainty estimation of each view is utilized to achieve accurate labeling. Experiments on the NIH pancreas segmentation dataset and a multi-organ segmentation dataset show state-of-the-art performance of the proposed framework on semi-supervised medical image segmentation. Under unsupervised domain adaptation settings, we validate the effectiveness of this work by adapting our multi-organ segmentation model to two pathological organs from the Medical Segmentation Decathlon Datasets. Additionally, we show that our UMCT-DA model can even effectively handle the challenging situation where labeled source data is inaccessible, demonstrating strong potentials for real-world applications.
* 19 pages, 6 figures, to appear in Medical Image Analysis. This article is an extension of the conference paper arXiv:1811.12506
Detecting Scatteredly-Distributed, Small, andCritically Important Objects in 3D OncologyImaging via Decision Stratification
May 27, 2020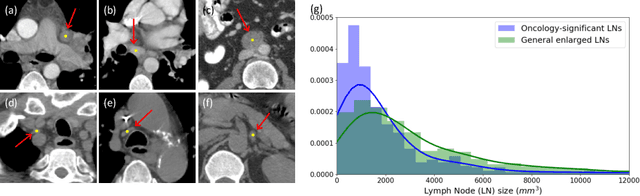
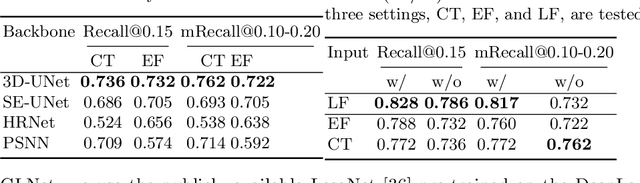
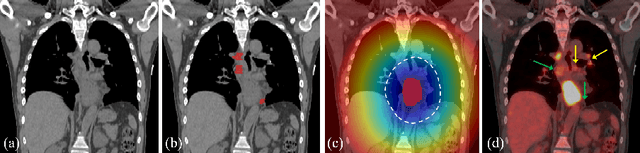
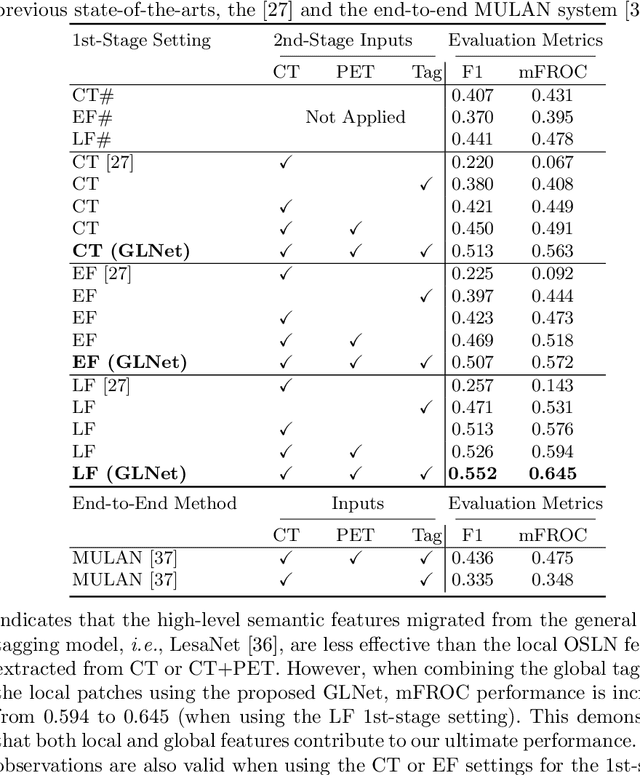
Finding and identifying scatteredly-distributed, small, and critically important objects in 3D oncology images is very challenging. We focus on the detection and segmentation of oncology-significant (or suspicious cancer metastasized) lymph nodes (OSLNs), which has not been studied before as a computational task. Determining and delineating the spread of OSLNs is essential in defining the corresponding resection/irradiating regions for the downstream workflows of surgical resection and radiotherapy of various cancers. For patients who are treated with radiotherapy, this task is performed by experienced radiation oncologists that involves high-level reasoning on whether LNs are metastasized, which is subject to high inter-observer variations. In this work, we propose a divide-and-conquer decision stratification approach that divides OSLNs into tumor-proximal and tumor-distal categories. This is motivated by the observation that each category has its own different underlying distributions in appearance, size and other characteristics. Two separate detection-by-segmentation networks are trained per category and fused. To further reduce false positives (FP), we present a novel global-local network (GLNet) that combines high-level lesion characteristics with features learned from localized 3D image patches. Our method is evaluated on a dataset of 141 esophageal cancer patients with PET and CT modalities (the largest to-date). Our results significantly improve the recall from $45\%$ to $67\%$ at $3$ FPs per patient as compared to previous state-of-the-art methods. The highest achieved OSLN recall of $0.828$ is clinically relevant and valuable.
Organ at Risk Segmentation for Head and Neck Cancer using Stratified Learning and Neural Architecture Search
Apr 17, 2020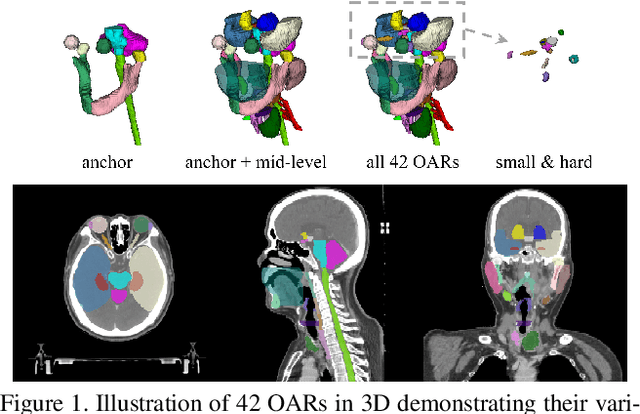

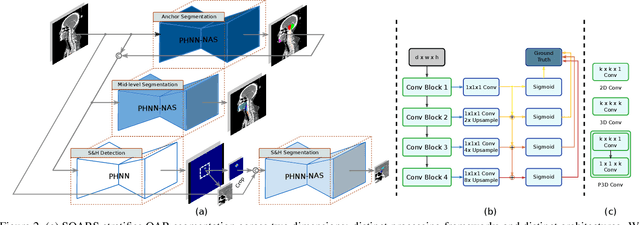
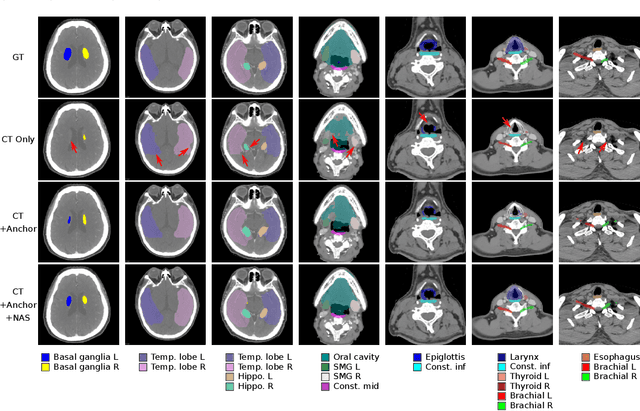
OAR segmentation is a critical step in radiotherapy of head and neck (H&N) cancer, where inconsistencies across radiation oncologists and prohibitive labor costs motivate automated approaches. However, leading methods using standard fully convolutional network workflows that are challenged when the number of OARs becomes large, e.g. > 40. For such scenarios, insights can be gained from the stratification approaches seen in manual clinical OAR delineation. This is the goal of our work, where we introduce stratified organ at risk segmentation (SOARS), an approach that stratifies OARs into anchor, mid-level, and small & hard (S&H) categories. SOARS stratifies across two dimensions. The first dimension is that distinct processing pipelines are used for each OAR category. In particular, inspired by clinical practices, anchor OARs are used to guide the mid-level and S&H categories. The second dimension is that distinct network architectures are used to manage the significant contrast, size, and anatomy variations between different OARs. We use differentiable neural architecture search (NAS), allowing the network to choose among 2D, 3D or Pseudo-3D convolutions. Extensive 4-fold cross-validation on 142 H&N cancer patients with 42 manually labeled OARs, the most comprehensive OAR dataset to date, demonstrates that both pipeline- and NAS-stratification significantly improves quantitative performance over the state-of-the-art (from 69.52% to 73.68% in absolute Dice scores). Thus, SOARS provides a powerful and principled means to manage the highly complex segmentation space of OARs.
Segmentation for Classification of Screening Pancreatic Neuroendocrine Tumors
Apr 04, 2020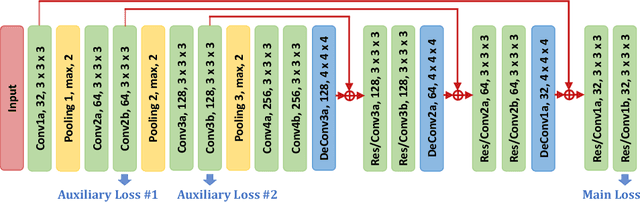
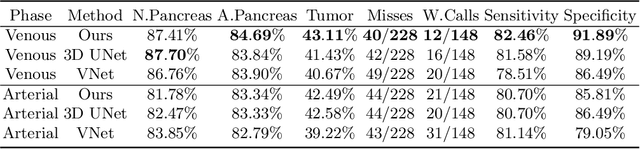
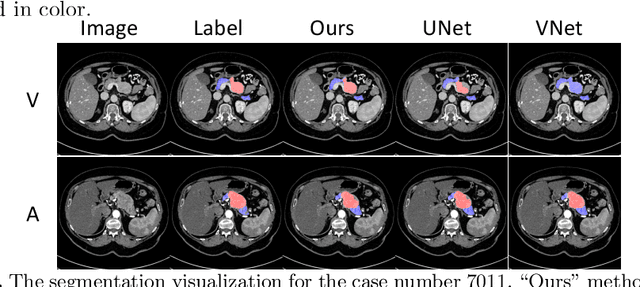
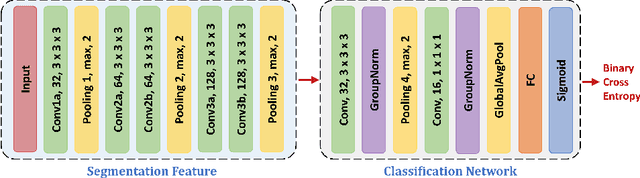
This work presents comprehensive results to detect in the early stage the pancreatic neuroendocrine tumors (PNETs), a group of endocrine tumors arising in the pancreas, which are the second common type of pancreatic cancer, by checking the abdominal CT scans. To the best of our knowledge, this task has not been studied before as a computational task. To provide radiologists with tumor locations, we adopt a segmentation framework to classify CT volumes by checking if at least a sufficient number of voxels is segmented as tumors. To quantitatively analyze our method, we collect and voxelwisely label a new abdominal CT dataset containing $376$ cases with both arterial and venous phases available for each case, in which $228$ cases were diagnosed with PNETs while the remaining $148$ cases are normal, which is currently the largest dataset for PNETs to the best of our knowledge. In order to incorporate rich knowledge of radiologists to our framework, we annotate dilated pancreatic duct as well, which is regarded as the sign of high risk for pancreatic cancer. Quantitatively, our approach outperforms state-of-the-art segmentation networks and achieves a sensitivity of $89.47\%$ at a specificity of $81.08\%$, which indicates a potential direction to achieve a clinical impact related to cancer diagnosis by earlier tumor detection.
V-NAS: Neural Architecture Search for Volumetric Medical Image Segmentation
Jun 06, 2019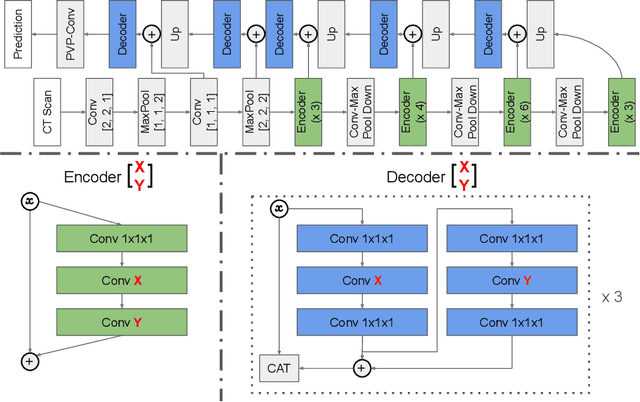


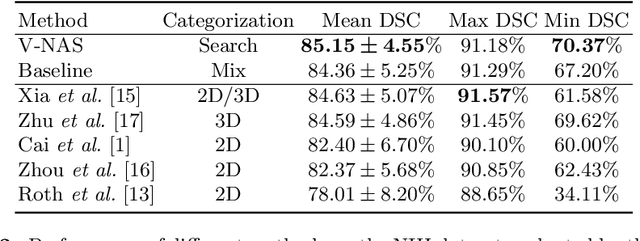
Deep learning algorithms, in particular 2D and 3D fully convolutional neural networks (FCNs), have rapidly become the mainstream methodology for volumetric medical image segmentation. However, 2D convolutions cannot fully leverage the rich spatial information along the third axis, while 3D convolutions suffer from the demanding computation and high GPU memory consumption. In this paper, we propose to automatically search the network architecture tailoring to volumetric medical image segmentation problem. Concretely, we formulate the structure learning as differentiable neural architecture search, and let the network itself choose between 2D, 3D or Pseudo-3D (P3D) convolutions at each layer. We evaluate our method on 3 public datasets, i.e., the NIH Pancreas dataset, the Lung and Pancreas dataset from the Medical Segmentation Decathlon (MSD) Challenge. Our method, named V-NAS, consistently outperforms other state-of-the-arts on the segmentation task of both normal organ (NIH Pancreas) and abnormal organs (MSD Lung tumors and MSD Pancreas tumors), which shows the power of chosen architecture. Moreover, the searched architecture on one dataset can be well generalized to other datasets, which demonstrates the robustness and practical use of our proposed method.
3D Semi-Supervised Learning with Uncertainty-Aware Multi-View Co-Training
Nov 29, 2018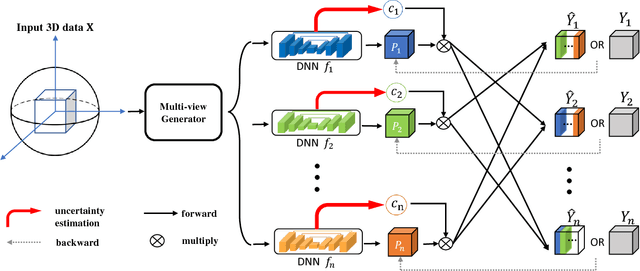
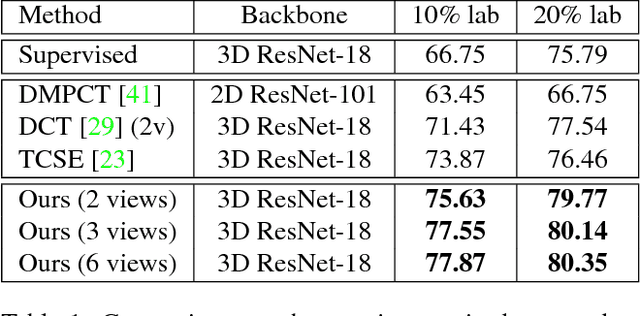
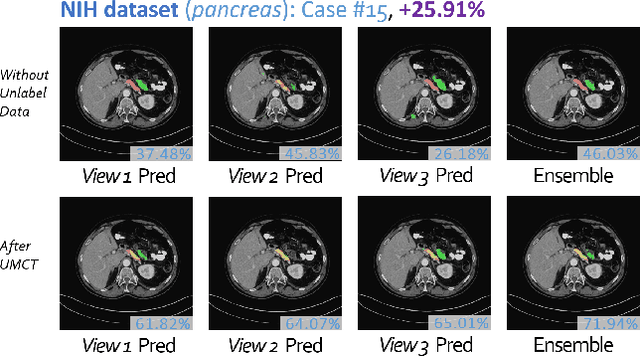
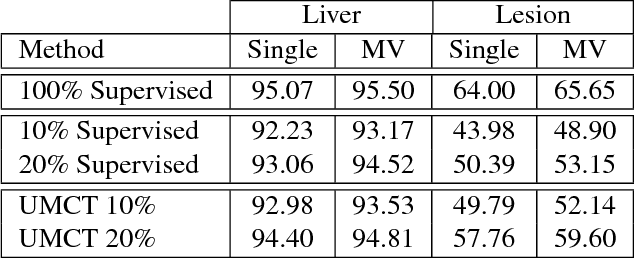
We propose a novel framework, uncertainty-aware multi-view co-training (UMCT), to address semi-supervised learning on 3D data, such as volumetric data in medical imaging. The original co-training method was applied to non-visual data. It requires different sources, or representations, of the data, which are called different views and differ from viewpoint in computer vision. Co-training was recently applied to visual tasks where the views were deep networks learnt by adversarial training. In our work, targeted at 3D data, co-training is achieved by exploiting multi-viewpoint consistency. We generate different views by rotating the 3D data and utilize asymmetrical 3D kernels to further encourage diversified features of each sub-net. In addition, we propose an uncertainty-aware attention mechanism to estimate the reliability of each view prediction with Bayesian deep learning. As one view requires the supervision from other views in co-training, our self-adaptive approach computes a confidence score for the prediction of each unlabeled sample, in order to assign a reliable pseudo label and thus achieve better performance. We show the effectiveness of our proposed method on several open datasets from medical image segmentation tasks (NIH pancreas & LiTS liver tumor dataset). A method based on our approach achieved the state-of-the-art performances on both the LiTS liver tumor segmentation and the Medical Segmentation Decathlon (MSD) challenge, demonstrating the robustness and value of our framework even when fully supervised training is feasible.