 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Flexible Three-Dimensional Hetero-phase Computed Tomography Hepatocellular Carcinoma (HCC) Detection Algorithm for Generalizable and Practical HCC Screening
Aug 17, 2021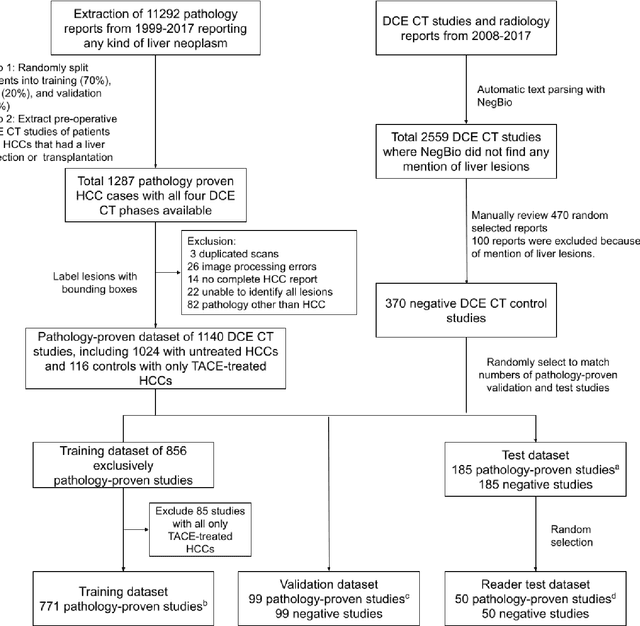
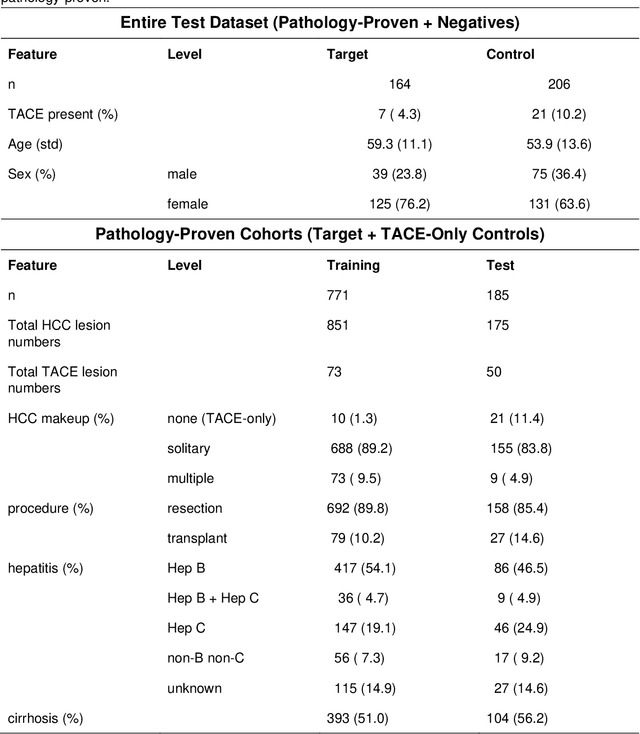
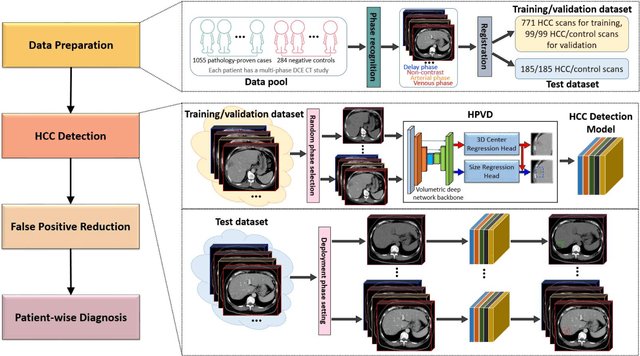
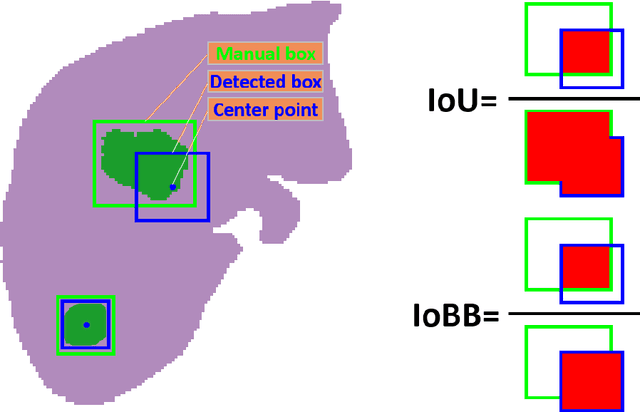
Hepatocellular carcinoma (HCC) can be potentially discovered from abdominal computed tomography (CT) studies under varied clinical scenarios, e.g., fully dynamic contrast enhanced (DCE) studies, non-contrast (NC) plus venous phase (VP) abdominal studies, or NC-only studies. We develop a flexible three-dimensional deep algorithm, called hetero-phase volumetric detection (HPVD), that can accept any combination of contrast-phase inputs and with adjustable sensitivity depending on the clinical purpose. We trained HPVD on 771 DCE CT scans to detect HCCs and tested on external 164 positives and 206 controls, respectively. We compare performance against six clinical readers, including two radiologists, two hepato-pancreatico-biliary (HPB) surgeons, and two hepatologists. The area under curve (AUC) of the localization receiver operating characteristic (LROC) for NC-only, NC plus VP, and full DCE CT yielded 0.71, 0.81, 0.89 respectively. At a high sensitivity operating point of 80% on DCE CT, HPVD achieved 97% specificity, which is comparable to measured physician performance. We also demonstrate performance improvements over more typical and less flexible non hetero-phase detectors. Thus, we demonstrate that a single deep learning algorithm can be effectively applied to diverse HCC detection clinical scenarios.
Lesion Segmentation and RECIST Diameter Prediction via Click-driven Attention and Dual-path Connection
May 05, 2021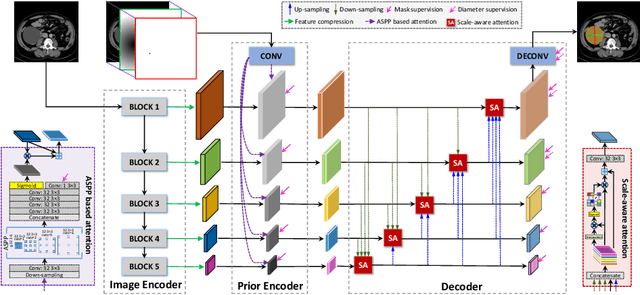
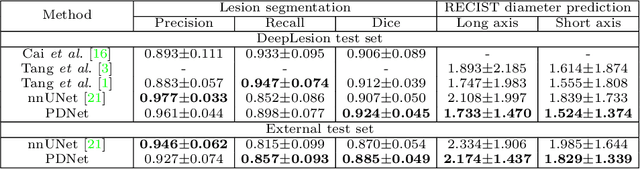
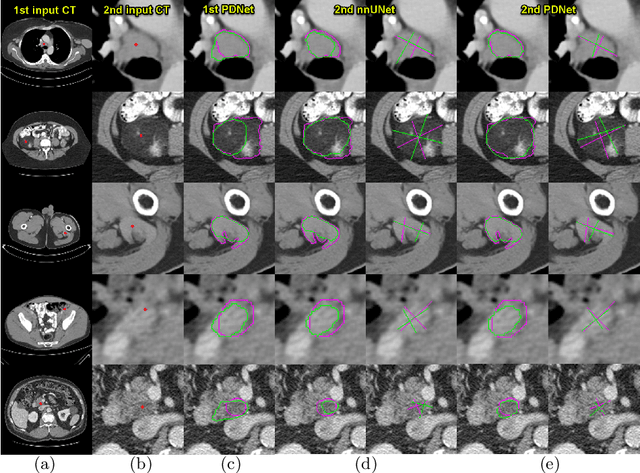
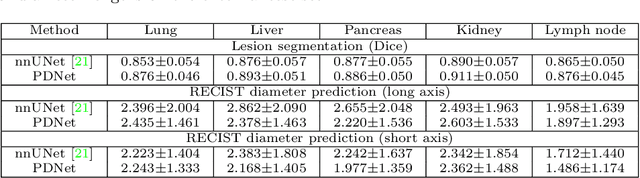
Measuring lesion size is an important step to assess tumor growth and monitor disease progression and therapy response in oncology image analysis. Although it is tedious and highly time-consuming, radiologists have to work on this task by using RECIST criteria (Response Evaluation Criteria In Solid Tumors) routinely and manually. Even though lesion segmentation may be the more accurate and clinically more valuable means, physicians can not manually segment lesions as now since much more heavy laboring will be required. In this paper, we present a prior-guided dual-path network (PDNet) to segment common types of lesions throughout the whole body and predict their RECIST diameters accurately and automatically. Similar to [1], a click guidance from radiologists is the only requirement. There are two key characteristics in PDNet: 1) Learning lesion-specific attention matrices in parallel from the click prior information by the proposed prior encoder, named click-driven attention; 2) Aggregating the extracted multi-scale features comprehensively by introducing top-down and bottom-up connections in the proposed decoder, named dual-path connection. Experiments show the superiority of our proposed PDNet in lesion segmentation and RECIST diameter prediction using the DeepLesion dataset and an external test set. PDNet learns comprehensive and representative deep image features for our tasks and produces more accurate results on both lesion segmentation and RECIST diameter prediction.
Weakly-Supervised Universal Lesion Segmentation with Regional Level Set Loss
May 03, 2021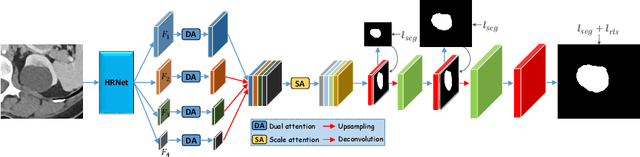
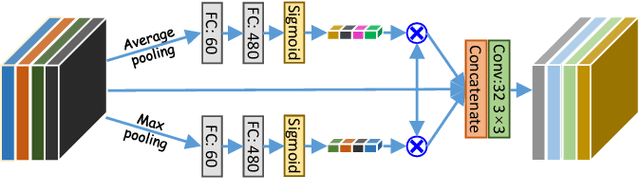
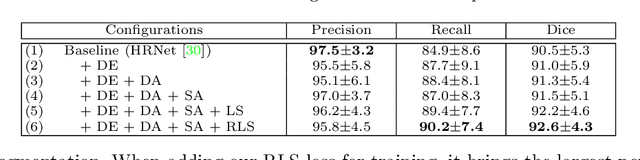
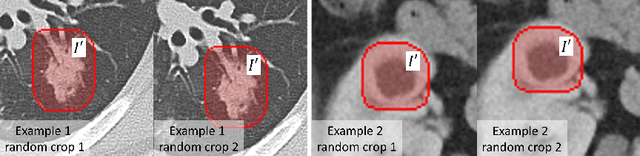
Accurately segmenting a variety of clinically significant lesions from whole body computed tomography (CT) scans is a critical task on precision oncology imaging, denoted as universal lesion segmentation (ULS). Manual annotation is the current clinical practice, being highly time-consuming and inconsistent on tumor's longitudinal assessment. Effectively training an automatic segmentation model is desirable but relies heavily on a large number of pixel-wise labelled data. Existing weakly-supervised segmentation approaches often struggle with regions nearby the lesion boundaries. In this paper, we present a novel weakly-supervised universal lesion segmentation method by building an attention enhanced model based on the High-Resolution Network (HRNet), named AHRNet, and propose a regional level set (RLS) loss for optimizing lesion boundary delineation. AHRNet provides advanced high-resolution deep image features by involving a decoder, dual-attention and scale attention mechanisms, which are crucial to performing accurate lesion segmentation. RLS can optimize the model reliably and effectively in a weakly-supervised fashion, forcing the segmentation close to lesion boundary. Extensive experimental results demonstrate that our method achieves the best performance on the publicly large-scale DeepLesion dataset and a hold-out test set.
Fully-Automated Liver Tumor Localization and Characterization from Multi-Phase MR Volumes Using Key-Slice ROI Parsing: A Physician-Inspired Approach
Dec 15, 2020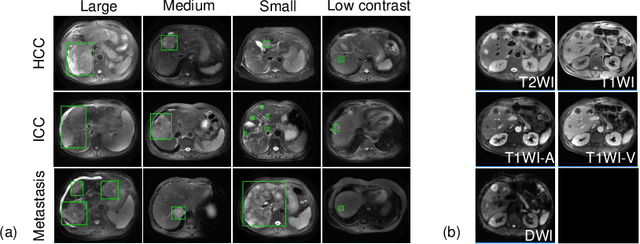
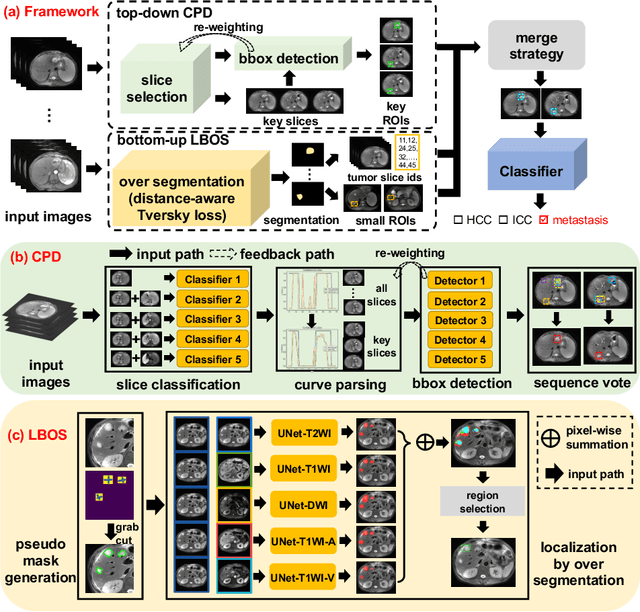
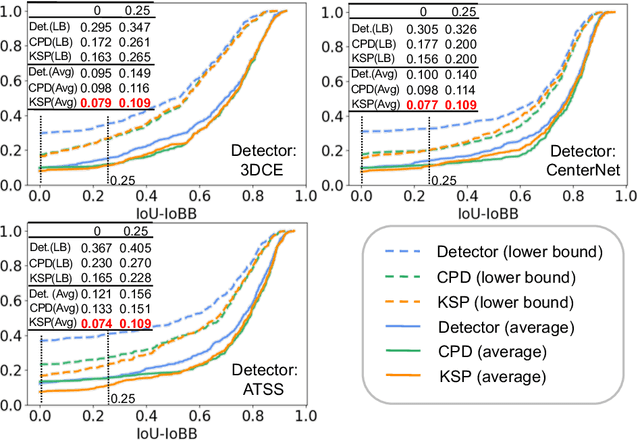
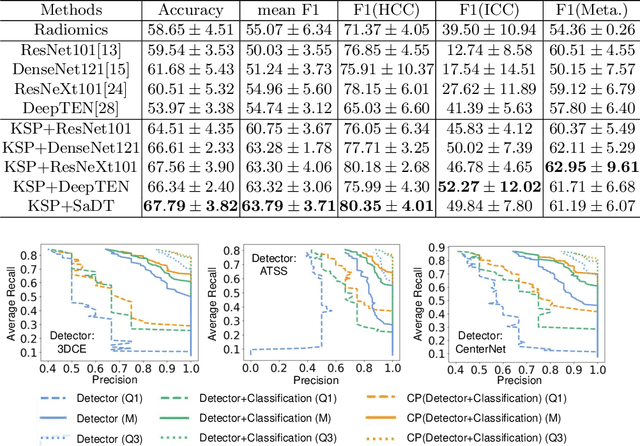
Using radiological scans to identify liver tumors is crucial for proper patient treatment. This is highly challenging, as top radiologists only achieve F1 scores of roughly 80% (hepatocellular carcinoma (HCC) vs. others) with only moderate inter-rater agreement, even when using multi-phase magnetic resonance (MR) imagery. Thus, there is great impetus for computer-aided diagnosis (CAD) solutions. A critical challengeis to reliably parse a 3D MR volume to localize diagnosable regions of interest (ROI). In this paper, we break down this problem using a key-slice parser (KSP), which emulates physician workflows by first identifying key slices and then localize their corresponding key ROIs. Because performance demands are so extreme, (not to miss any key ROI),our KSP integrates complementary modules--top-down classification-plus-detection (CPD) and bottom-up localization-by-over-segmentation(LBOS). The CPD uses a curve-parsing and detection confidence to re-weight classifier confidences. The LBOS uses over-segmentation to flag CPD failure cases and provides its own ROIs. For scalability, LBOS is only weakly trained on pseudo-masks using a new distance-aware Tversky loss. We evaluate our approach on the largest multi-phase MR liver lesion test dataset to date (430 biopsy-confirmed patients). Experiments demonstrate that our KSP can localize diagnosable ROIs with high reliability (85% patients have an average overlap of >= 40% with the ground truth). Moreover, we achieve an HCC vs. others F1 score of 0.804, providing a fully-automated CAD solution comparable with top human physicians.
Deep Lesion Tracker: Monitoring Lesions in 4D Longitudinal Imaging Studies
Dec 09, 2020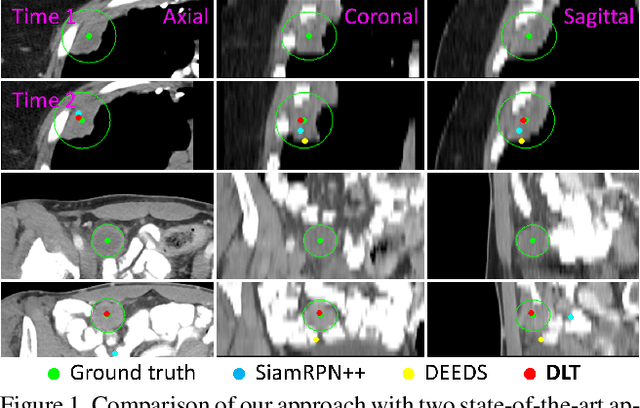
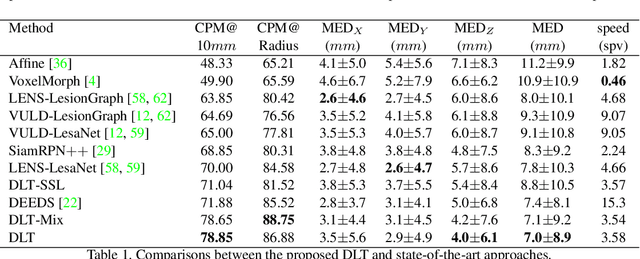
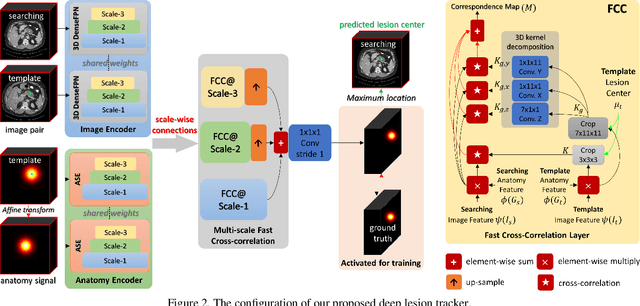
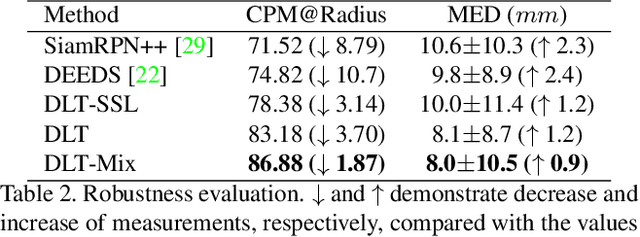
Monitoring treatment response in longitudinal studies plays an important role in clinical practice. Accurately identifying lesions across serial imaging follow-up is the core to the monitoring procedure. Typically this incorporates both image and anatomical considerations. However, matching lesions manually is labor-intensive and time-consuming. In this work, we present deep lesion tracker (DLT), a deep learning approach that uses both appearance- and anatomical-based signals. To incorporate anatomical constraints, we propose an anatomical signal encoder, which prevents lesions being matched with visually similar but spurious regions. In addition, we present a new formulation for Siamese networks that avoids the heavy computational loads of 3D cross-correlation. To present our network with greater varieties of images, we also propose a self-supervised learning (SSL) strategy to train trackers with unpaired images, overcoming barriers to data collection. To train and evaluate our tracker, we introduce and release the first lesion tracking benchmark, consisting of 3891 lesion pairs from the public DeepLesion database. The proposed method, DLT, locates lesion centers with a mean error distance of 7 mm. This is 5% better than a leading registration algorithm while running 14 times faster on whole CT volumes. We demonstrate even greater improvements over detector or similarity-learning alternatives. DLT also generalizes well on an external clinical test set of 100 longitudinal studies, achieving 88% accuracy. Finally, we plug DLT into an automatic tumor monitoring workflow where it leads to an accuracy of 85% in assessing lesion treatment responses, which is only 0.46% lower than the accuracy of manual inputs.
Self-supervised Learning of Pixel-wise Anatomical Embeddings in Radiological Images
Dec 04, 2020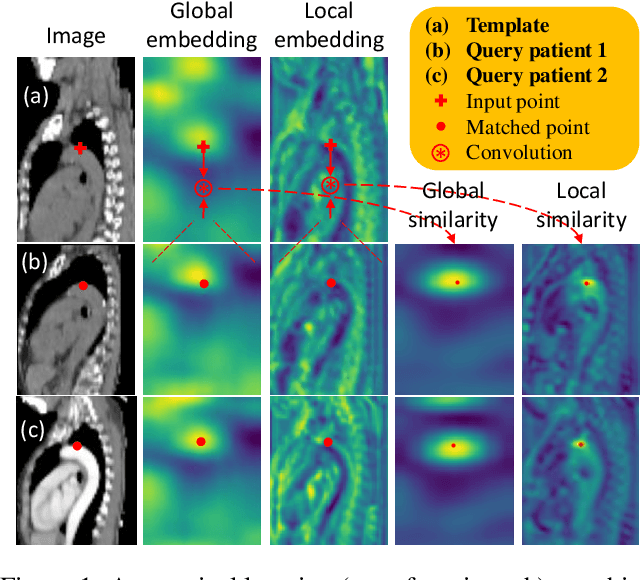
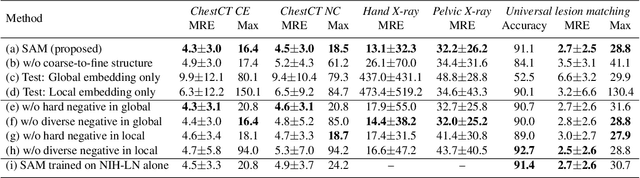
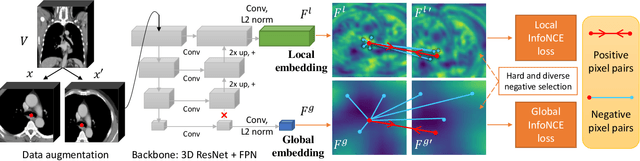
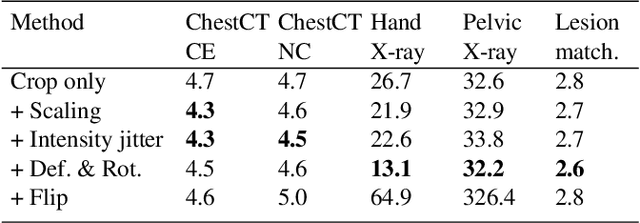
Radiological images such as computed tomography (CT) and X-rays render anatomy with intrinsic structures. Being able to reliably locate the same anatomical or semantic structure across varying images is a fundamental task in medical image analysis. In principle it is possible to use landmark detection or semantic segmentation for this task, but to work well these require large numbers of labeled data for each anatomical structure and sub-structure of interest. A more universal approach would discover the intrinsic structure from unlabeled images. We introduce such an approach, called Self-supervised Anatomical eMbedding (SAM). SAM generates semantic embeddings for each image pixel that describes its anatomical location or body part. To produce such embeddings, we propose a pixel-level contrastive learning framework. A coarse-to-fine strategy ensures both global and local anatomical information are encoded. Negative sample selection strategies are designed to enhance the discriminability among different body parts. Using SAM, one can label any point of interest on a template image, and then locate the same body part in other images by simple nearest neighbor searching. We demonstrate the effectiveness of SAM in multiple tasks with 2D and 3D image modalities. On a chest CT dataset with 19 landmarks, SAM outperforms widely-used registration algorithms while being 200 times faster. On two X-ray datasets, SAM, with only one labeled template image, outperforms supervised methods trained on 50 labeled images. We also apply SAM on whole-body follow-up lesion matching in CT and obtain an accuracy of 91%.
Learning from Multiple Datasets with Heterogeneous and Partial Labels for Universal Lesion Detection in CT
Sep 05, 2020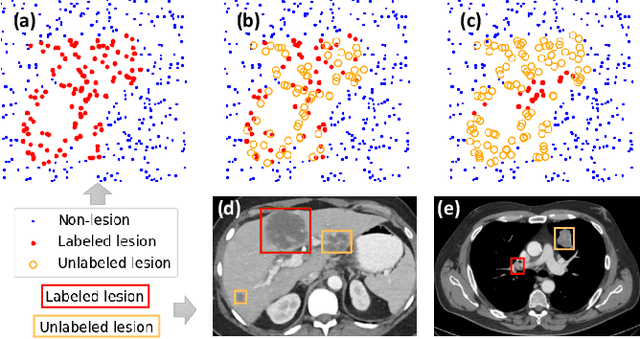
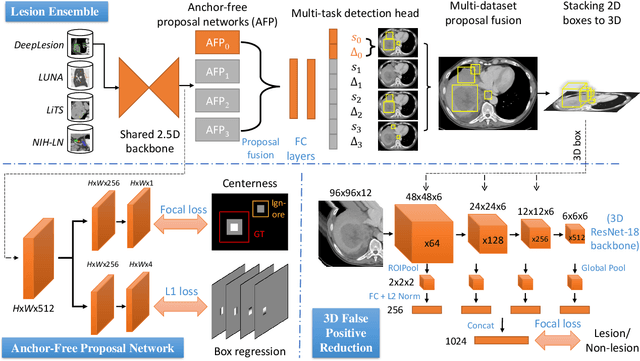
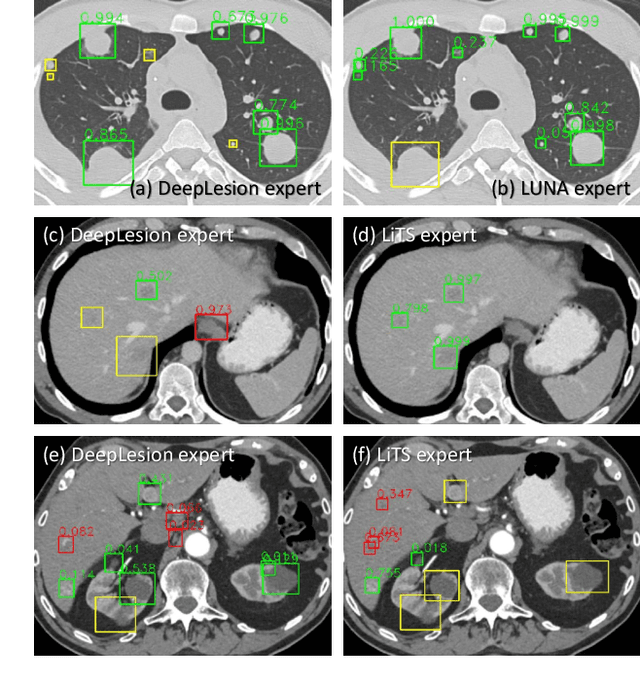
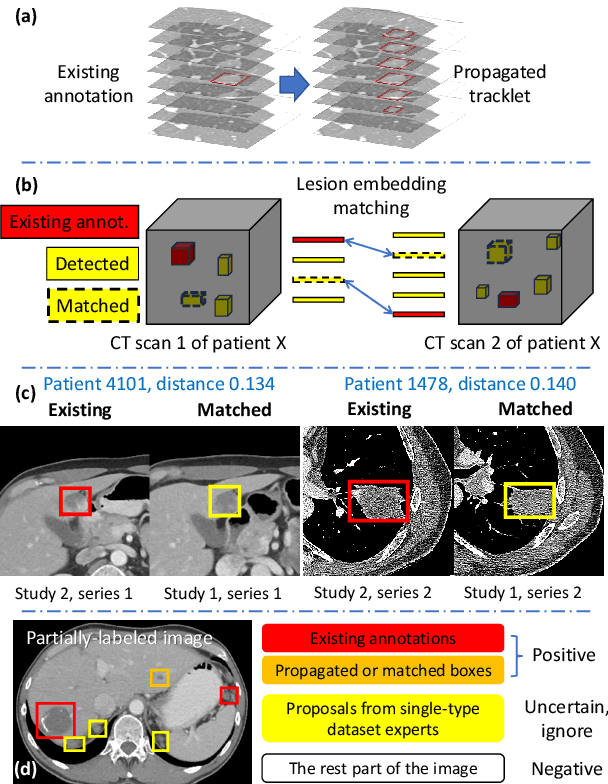
Large-scale datasets with high-quality labels are desired for training accurate deep learning models. However, due to annotation costs, medical imaging datasets are often either partially-labeled or small. For example, DeepLesion is a large-scale CT image dataset with lesions of various types, but it also has many unlabeled lesions (missing annotations). When training a lesion detector on a partially-labeled dataset, the missing annotations will generate incorrect negative signals and degrade performance. Besides DeepLesion, there are several small single-type datasets, such as LUNA for lung nodules and LiTS for liver tumors. Such datasets have heterogeneous label scopes, i.e., different lesion types are labeled in different datasets with other types ignored. In this work, we aim to tackle the problem of heterogeneous and partial labels, and develop a universal lesion detection algorithm to detect a comprehensive variety of lesions. First, we build a simple yet effective lesion detection framework named Lesion ENSemble (LENS). LENS can efficiently learn from multiple heterogeneous lesion datasets in a multi-task fashion and leverage their synergy by feature sharing and proposal fusion. Next, we propose strategies to mine missing annotations from partially-labeled datasets by exploiting clinical prior knowledge and cross-dataset knowledge transfer. Finally, we train our framework on four public lesion datasets and evaluate it on 800 manually-labeled sub-volumes in DeepLesion. On this challenging task, our method brings a relative improvement of 49% compared to the current state-of-the-art approach.
User-Guided Domain Adaptation for Rapid Annotation from User Interactions: A Study on Pathological Liver Segmentation
Sep 05, 2020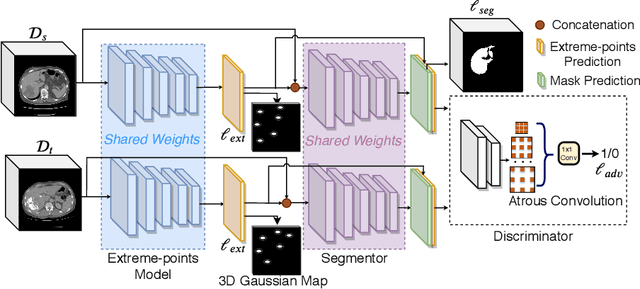
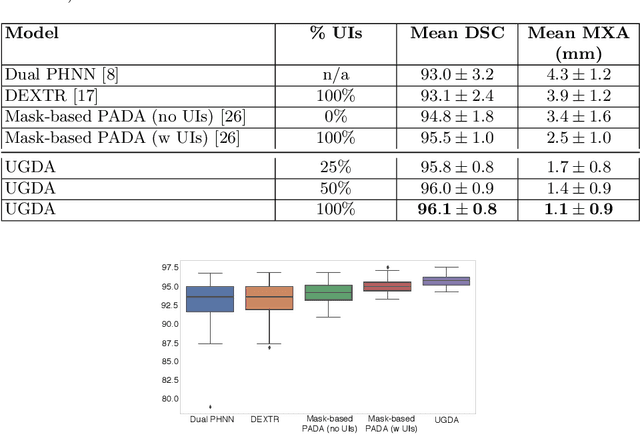
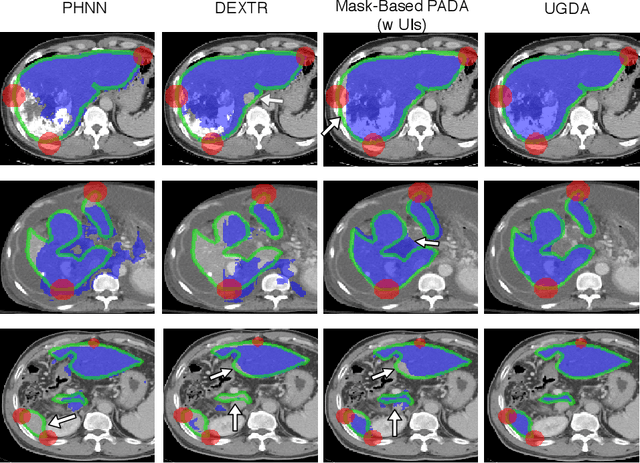

Mask-based annotation of medical images, especially for 3D data, is a bottleneck in developing reliable machine learning models. Using minimal-labor user interactions (UIs) to guide the annotation is promising, but challenges remain on best harmonizing the mask prediction with the UIs. To address this, we propose the user-guided domain adaptation (UGDA) framework, which uses prediction-based adversarial domain adaptation (PADA) to model the combined distribution of UIs and mask predictions. The UIs are then used as anchors to guide and align the mask prediction. Importantly, UGDA can both learn from unlabelled data and also model the high-level semantic meaning behind different UIs. We test UGDA on annotating pathological livers using a clinically comprehensive dataset of 927 patient studies. Using only extreme-point UIs, we achieve a mean (worst-case) performance of 96.1%(94.9%), compared to 93.0% (87.0%) for deep extreme points (DEXTR). Furthermore, we also show UGDA can retain this state-of-the-art performance even when only seeing a fraction of available UIs, demonstrating an ability for robust and reliable UI-guided segmentation with extremely minimal labor demands.
Deep Volumetric Universal Lesion Detection using Light-Weight Pseudo 3D Convolution and Surface Point Regression
Aug 30, 2020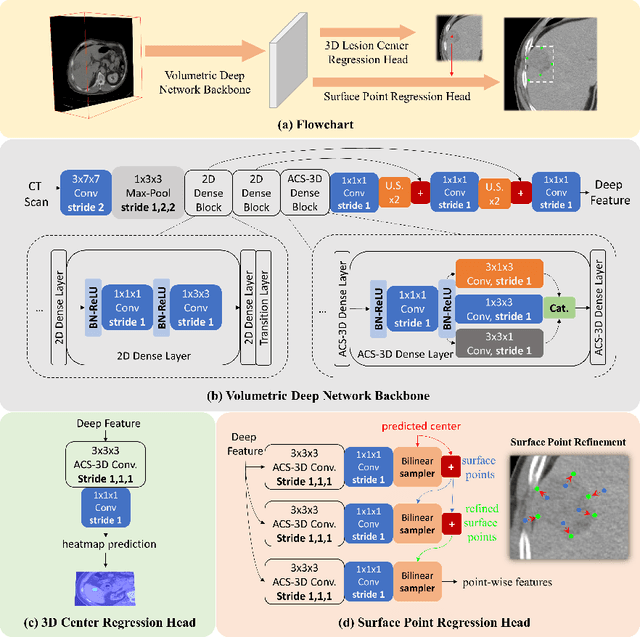
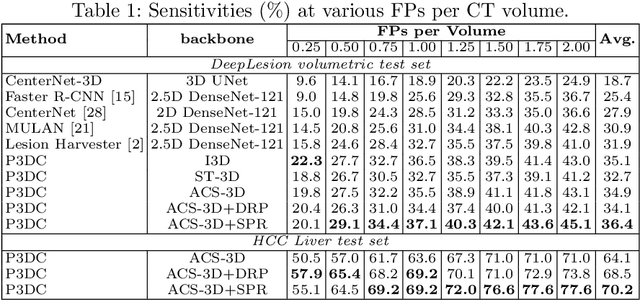

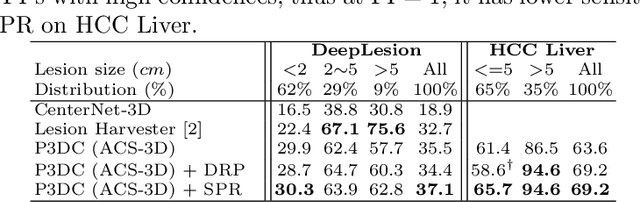
Identifying, measuring and reporting lesions accurately and comprehensively from patient CT scans are important yet time-consuming procedures for physicians. Computer-aided lesion/significant-findings detection techniques are at the core of medical imaging, which remain very challenging due to the tremendously large variability of lesion appearance, location and size distributions in 3D imaging. In this work, we propose a novel deep anchor-free one-stage VULD framework that incorporates (1) P3DC operators to recycle the architectural configurations and pre-trained weights from the off-the-shelf 2D networks, especially ones with large capacities to cope with data variance, and (2) a new SPR method to effectively regress the 3D lesion spatial extents by pinpointing their representative key points on lesion surfaces. Experimental validations are first conducted on the public large-scale NIH DeepLesion dataset where our proposed method delivers new state-of-the-art quantitative performance. We also test VULD on our in-house dataset for liver tumor detection. VULD generalizes well in both large-scale and small-sized tumor datasets in CT imaging.
Lymph Node Gross Tumor Volume Detection in Oncology Imaging via Relationship Learning Using Graph Neural Network
Aug 29, 2020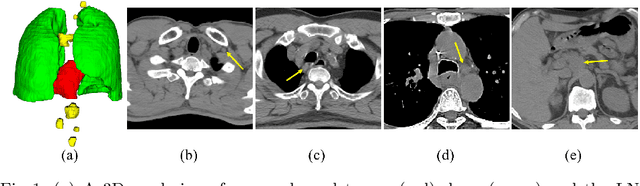
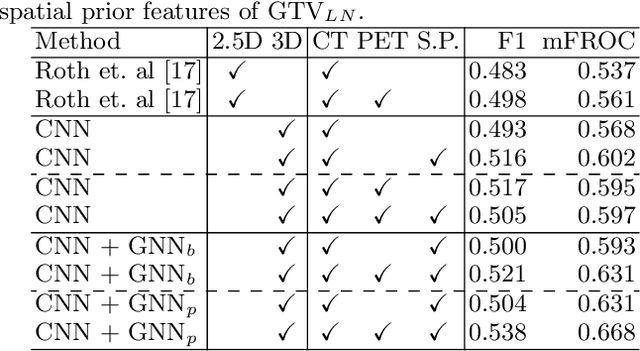
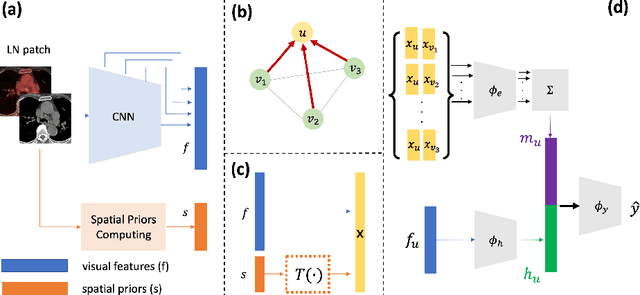
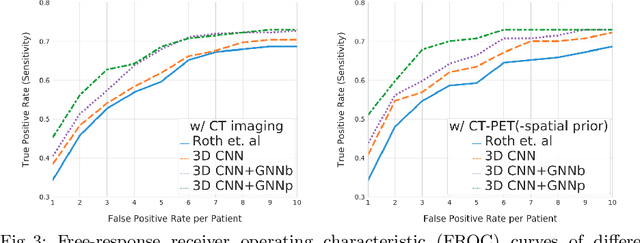
Determining the spread of GTV$_{LN}$ is essential in defining the respective resection or irradiating regions for the downstream workflows of surgical resection and radiotherapy for many cancers. Different from the more common enlarged lymph node (LN), GTV$_{LN}$ also includes smaller ones if associated with high positron emission tomography signals and/or any metastasis signs in CT. This is a daunting task. In this work, we propose a unified LN appearance and inter-LN relationship learning framework to detect the true GTV$_{LN}$. This is motivated by the prior clinical knowledge that LNs form a connected lymphatic system, and the spread of cancer cells among LNs often follows certain pathways. Specifically, we first utilize a 3D convolutional neural network with ROI-pooling to extract the GTV$_{LN}$'s instance-wise appearance features. Next, we introduce a graph neural network to further model the inter-LN relationships where the global LN-tumor spatial priors are included in the learning process. This leads to an end-to-end trainable network to detect by classifying GTV$_{LN}$. We operate our model on a set of GTV$_{LN}$ candidates generated by a preliminary 1st-stage method, which has a sensitivity of $>85\%$ at the cost of high false positive (FP) ($>15$ FPs per patient). We validate our approach on a radiotherapy dataset with 142 paired PET/RTCT scans containing the chest and upper abdominal body parts. The proposed method significantly improves over the state-of-the-art (SOTA) LN classification method by $5.5\%$ and $13.1\%$ in F1 score and the averaged sensitivity value at $2, 3, 4, 6$ FPs per patient, respectively.