 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Continual Learning-driven Model for Accurate and Generalizable Segmentation of Clinically Comprehensive and Fine-grained Whole-body Anatomies in CT
Mar 16, 2025Precision medicine in the quantitative management of chronic diseases and oncology would be greatly improved if the Computed Tomography (CT) scan of any patient could be segmented, parsed and analyzed in a precise and detailed way. However, there is no such fully annotated CT dataset with all anatomies delineated for training because of the exceptionally high manual cost, the need for specialized clinical expertise, and the time required to finish the task. To this end, we proposed a novel continual learning-driven CT model that can segment complete anatomies presented using dozens of previously partially labeled datasets, dynamically expanding its capacity to segment new ones without compromising previously learned organ knowledge. Existing multi-dataset approaches are not able to dynamically segment new anatomies without catastrophic forgetting and would encounter optimization difficulty or infeasibility when segmenting hundreds of anatomies across the whole range of body regions. Our single unified CT segmentation model, CL-Net, can highly accurately segment a clinically comprehensive set of 235 fine-grained whole-body anatomies. Composed of a universal encoder, multiple optimized and pruned decoders, CL-Net is developed using 13,952 CT scans from 20 public and 16 private high-quality partially labeled CT datasets of various vendors, different contrast phases, and pathologies. Extensive evaluation demonstrates that CL-Net consistently outperforms the upper limit of an ensemble of 36 specialist nnUNets trained per dataset with the complexity of 5% model size and significantly surpasses the segmentation accuracy of recent leading Segment Anything-style medical image foundation models by large margins. Our continual learning-driven CL-Net model would lay a solid foundation to facilitate many downstream tasks of oncology and chronic diseases using the most widely adopted CT imaging.
From Slices to Sequences: Autoregressive Tracking Transformer for Cohesive and Consistent 3D Lymph Node Detection in CT Scans
Mar 11, 2025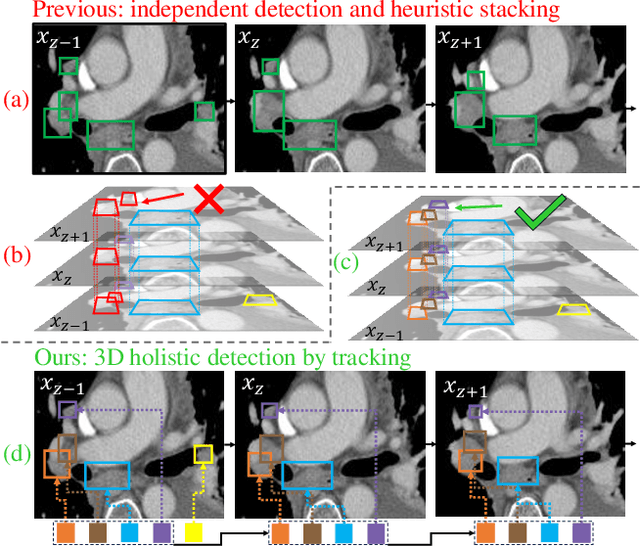

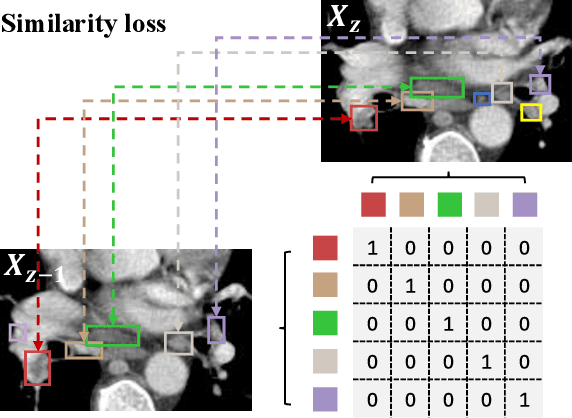
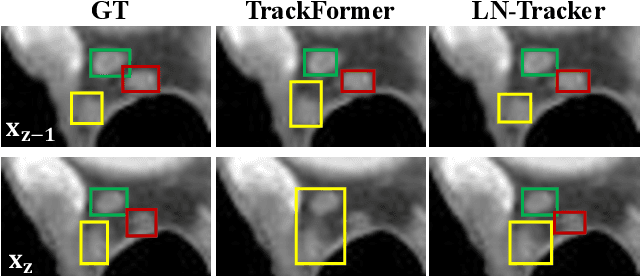
Lymph node (LN) assessment is an essential task in the routine radiology workflow, providing valuable insights for cancer staging, treatment planning and beyond. Identifying scatteredly-distributed and low-contrast LNs in 3D CT scans is highly challenging, even for experienced clinicians. Previous lesion and LN detection methods demonstrate effectiveness of 2.5D approaches (i.e, using 2D network with multi-slice inputs), leveraging pretrained 2D model weights and showing improved accuracy as compared to separate 2D or 3D detectors. However, slice-based 2.5D detectors do not explicitly model inter-slice consistency for LN as a 3D object, requiring heuristic post-merging steps to generate final 3D LN instances, which can involve tuning a set of parameters for each dataset. In this work, we formulate 3D LN detection as a tracking task and propose LN-Tracker, a novel LN tracking transformer, for joint end-to-end detection and 3D instance association. Built upon DETR-based detector, LN-Tracker decouples transformer decoder's query into the track and detection groups, where the track query autoregressively follows previously tracked LN instances along the z-axis of a CT scan. We design a new transformer decoder with masked attention module to align track query's content to the context of current slice, meanwhile preserving detection query's high accuracy in current slice. An inter-slice similarity loss is introduced to encourage cohesive LN association between slices. Extensive evaluation on four lymph node datasets shows LN-Tracker's superior performance, with at least 2.7% gain in average sensitivity when compared to other top 3D/2.5D detectors. Further validation on public lung nodule and prostate tumor detection tasks confirms the generalizability of LN-Tracker as it achieves top performance on both tasks. Datasets will be released upon acceptance.
Low-Rank Continual Pyramid Vision Transformer: Incrementally Segment Whole-Body Organs in CT with Light-Weighted Adaptation
Oct 07, 2024Deep segmentation networks achieve high performance when trained on specific datasets. However, in clinical practice, it is often desirable that pretrained segmentation models can be dynamically extended to enable segmenting new organs without access to previous training datasets or without training from scratch. This would ensure a much more efficient model development and deployment paradigm accounting for the patient privacy and data storage issues. This clinically preferred process can be viewed as a continual semantic segmentation (CSS) problem. Previous CSS works would either experience catastrophic forgetting or lead to unaffordable memory costs as models expand. In this work, we propose a new continual whole-body organ segmentation model with light-weighted low-rank adaptation (LoRA). We first train and freeze a pyramid vision transformer (PVT) base segmentation model on the initial task, then continually add light-weighted trainable LoRA parameters to the frozen model for each new learning task. Through a holistically exploration of the architecture modification, we identify three most important layers (i.e., patch-embedding, multi-head attention and feed forward layers) that are critical in adapting to the new segmentation tasks, while retaining the majority of the pretrained parameters fixed. Our proposed model continually segments new organs without catastrophic forgetting and meanwhile maintaining a low parameter increasing rate. Continually trained and tested on four datasets covering different body parts of a total of 121 organs, results show that our model achieves high segmentation accuracy, closely reaching the PVT and nnUNet upper bounds, and significantly outperforms other regularization-based CSS methods. When comparing to the leading architecture-based CSS method, our model has a substantial lower parameter increasing rate while achieving comparable performance.
Effective Lymph Nodes Detection in CT Scans Using Location Debiased Query Selection and Contrastive Query Representation in Transformer
Apr 04, 2024Lymph node (LN) assessment is a critical, indispensable yet very challenging task in the routine clinical workflow of radiology and oncology. Accurate LN analysis is essential for cancer diagnosis, staging, and treatment planning. Finding scatteredly distributed, low-contrast clinically relevant LNs in 3D CT is difficult even for experienced physicians under high inter-observer variations. Previous automatic LN detection works typically yield limited recall and high false positives (FPs) due to adjacent anatomies with similar image intensities, shapes, or textures (vessels, muscles, esophagus, etc). In this work, we propose a new LN DEtection TRansformer, named LN-DETR, to achieve more accurate performance. By enhancing the 2D backbone with a multi-scale 2.5D feature fusion to incorporate 3D context explicitly, more importantly, we make two main contributions to improve the representation quality of LN queries. 1) Considering that LN boundaries are often unclear, an IoU prediction head and a location debiased query selection are proposed to select LN queries of higher localization accuracy as the decoder query's initialization. 2) To reduce FPs, query contrastive learning is employed to explicitly reinforce LN queries towards their best-matched ground-truth queries over unmatched query predictions. Trained and tested on 3D CT scans of 1067 patients (with 10,000+ labeled LNs) via combining seven LN datasets from different body parts (neck, chest, and abdomen) and pathologies/cancers, our method significantly improves the performance of previous leading methods by > 4-5% average recall at the same FP rates in both internal and external testing. We further evaluate on the universal lesion detection task using NIH DeepLesion benchmark, and our method achieves the top performance of 88.46% averaged recall across 0.5 to 4 FPs per image, compared with other leading reported results.
Towards a Comprehensive, Efficient and Promptable Anatomic Structure Segmentation Model using 3D Whole-body CT Scans
Mar 22, 2024



Segment anything model (SAM) demonstrates strong generalization ability on natural image segmentation. However, its direct adaption in medical image segmentation tasks shows significant performance drops with inferior accuracy and unstable results. It may also requires an excessive number of prompt points to obtain a reasonable accuracy. For segmenting 3D radiological CT or MRI scans, a 2D SAM model has to separately handle hundreds of 2D slices. Although quite a few studies explore adapting SAM into medical image volumes, the efficiency of 2D adaption methods is unsatisfactory and 3D adaptation methods only capable of segmenting specific organs/tumors. In this work, we propose a comprehensive and scalable 3D SAM model for whole-body CT segmentation, named CT-SAM3D. Instead of adapting SAM, we propose a 3D promptable segmentation model using a (nearly) fully labeled CT dataset. To train CT-SAM3D effectively, ensuring the model's accurate responses to higher-dimensional spatial prompts is crucial, and 3D patch-wise training is required due to GPU memory constraints. For this purpose, we propose two key technical developments: 1) a progressively and spatially aligned prompt encoding method to effectively encode click prompts in local 3D space; and 2) a cross-patch prompt learning scheme to capture more 3D spatial context, which is beneficial for reducing the editing workloads when interactively prompting on large organs. CT-SAM3D is trained and validated using a curated dataset of 1204 CT scans containing 107 whole-body anatomies, reporting significantly better quantitative performance against all previous SAM-derived models by a large margin with much fewer click prompts. Our model can handle segmenting unseen organ as well. Code, data, and our 3D interactive segmentation tool with quasi-real-time responses will be made publicly available.
Anatomy-Aware Lymph Node Detection in Chest CT using Implicit Station Stratification
Jul 28, 2023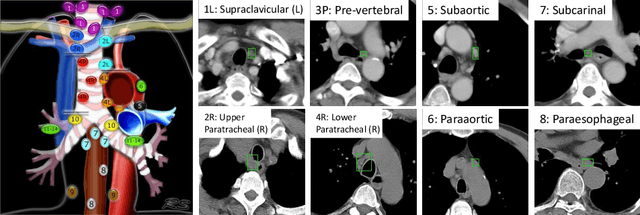
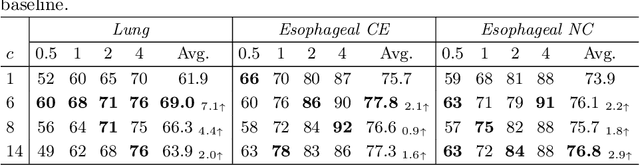


Finding abnormal lymph nodes in radiological images is highly important for various medical tasks such as cancer metastasis staging and radiotherapy planning. Lymph nodes (LNs) are small glands scattered throughout the body. They are grouped or defined to various LN stations according to their anatomical locations. The CT imaging appearance and context of LNs in different stations vary significantly, posing challenges for automated detection, especially for pathological LNs. Motivated by this observation, we propose a novel end-to-end framework to improve LN detection performance by leveraging their station information. We design a multi-head detector and make each head focus on differentiating the LN and non-LN structures of certain stations. Pseudo station labels are generated by an LN station classifier as a form of multi-task learning during training, so we do not need another explicit LN station prediction model during inference. Our algorithm is evaluated on 82 patients with lung cancer and 91 patients with esophageal cancer. The proposed implicit station stratification method improves the detection sensitivity of thoracic lymph nodes from 65.1% to 71.4% and from 80.3% to 85.5% at 2 false positives per patient on the two datasets, respectively, which significantly outperforms various existing state-of-the-art baseline techniques such as nnUNet, nnDetection and LENS.
Accurate Airway Tree Segmentation in CT Scans via Anatomy-aware Multi-class Segmentation and Topology-guided Iterative Learning
Jun 15, 2023



Intrathoracic airway segmentation in computed tomography (CT) is a prerequisite for various respiratory disease analyses such as chronic obstructive pulmonary disease (COPD), asthma and lung cancer. Unlike other organs with simpler shapes or topology, the airway's complex tree structure imposes an unbearable burden to generate the "ground truth" label (up to 7 or 3 hours of manual or semi-automatic annotation on each case). Most of the existing airway datasets are incompletely labeled/annotated, thus limiting the completeness of computer-segmented airway. In this paper, we propose a new anatomy-aware multi-class airway segmentation method enhanced by topology-guided iterative self-learning. Based on the natural airway anatomy, we formulate a simple yet highly effective anatomy-aware multi-class segmentation task to intuitively handle the severe intra-class imbalance of the airway. To solve the incomplete labeling issue, we propose a tailored self-iterative learning scheme to segment toward the complete airway tree. For generating pseudo-labels to achieve higher sensitivity , we introduce a novel breakage attention map and design a topology-guided pseudo-label refinement method by iteratively connecting breaking branches commonly existed from initial pseudo-labels. Extensive experiments have been conducted on four datasets including two public challenges. The proposed method ranked 1st in both EXACT'09 challenge using average score and ATM'22 challenge on weighted average score. In a public BAS dataset and a private lung cancer dataset, our method significantly improves previous leading approaches by extracting at least (absolute) 7.5% more detected tree length and 4.0% more tree branches, while maintaining similar precision.
Multi-site, Multi-domain Airway Tree Modeling : A Public Benchmark for Pulmonary Airway Segmentation
Mar 10, 2023



Open international challenges are becoming the de facto standard for assessing computer vision and image analysis algorithms. In recent years, new methods have extended the reach of pulmonary airway segmentation that is closer to the limit of image resolution. Since EXACT'09 pulmonary airway segmentation, limited effort has been directed to quantitative comparison of newly emerged algorithms driven by the maturity of deep learning based approaches and clinical drive for resolving finer details of distal airways for early intervention of pulmonary diseases. Thus far, public annotated datasets are extremely limited, hindering the development of data-driven methods and detailed performance evaluation of new algorithms. To provide a benchmark for the medical imaging community, we organized the Multi-site, Multi-domain Airway Tree Modeling (ATM'22), which was held as an official challenge event during the MICCAI 2022 conference. ATM'22 provides large-scale CT scans with detailed pulmonary airway annotation, including 500 CT scans (300 for training, 50 for validation, and 150 for testing). The dataset was collected from different sites and it further included a portion of noisy COVID-19 CTs with ground-glass opacity and consolidation. Twenty-three teams participated in the entire phase of the challenge and the algorithms for the top ten teams are reviewed in this paper. Quantitative and qualitative results revealed that deep learning models embedded with the topological continuity enhancement achieved superior performance in general. ATM'22 challenge holds as an open-call design, the training data and the gold standard evaluation are available upon successful registration via its homepage.
Continual Segment: Towards a Single, Unified and Accessible Continual Segmentation Model of 143 Whole-body Organs in CT Scans
Feb 04, 2023
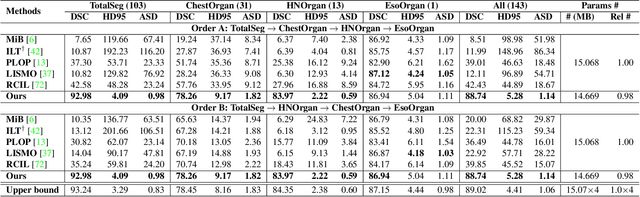
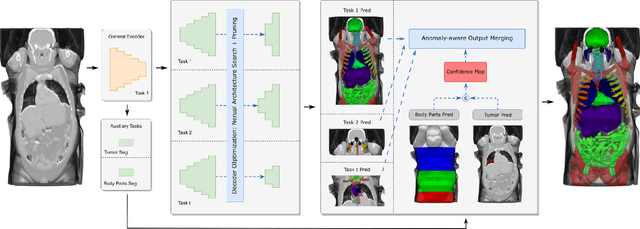
Deep learning empowers the mainstream medical image segmentation methods. Nevertheless current deep segmentation approaches are not capable of efficiently and effectively adapting and updating the trained models when new incremental segmentation classes (along with new training datasets or not) are required to be added. In real clinical environment, it can be preferred that segmentation models could be dynamically extended to segment new organs/tumors without the (re-)access to previous training datasets due to obstacles of patient privacy and data storage. This process can be viewed as a continual semantic segmentation (CSS) problem, being understudied for multi-organ segmentation. In this work, we propose a new architectural CSS learning framework to learn a single deep segmentation model for segmenting a total of 143 whole-body organs. Using the encoder/decoder network structure, we demonstrate that a continually-trained then frozen encoder coupled with incrementally-added decoders can extract and preserve sufficiently representative image features for new classes to be subsequently and validly segmented. To maintain a single network model complexity, we trim each decoder progressively using neural architecture search and teacher-student based knowledge distillation. To incorporate with both healthy and pathological organs appearing in different datasets, a novel anomaly-aware and confidence learning module is proposed to merge the overlapped organ predictions, originated from different decoders. Trained and validated on 3D CT scans of 2500+ patients from four datasets, our single network can segment total 143 whole-body organs with very high accuracy, closely reaching the upper bound performance level by training four separate segmentation models (i.e., one model per dataset/task).
LViT: Language meets Vision Transformer in Medical Image Segmentation
Jun 29, 2022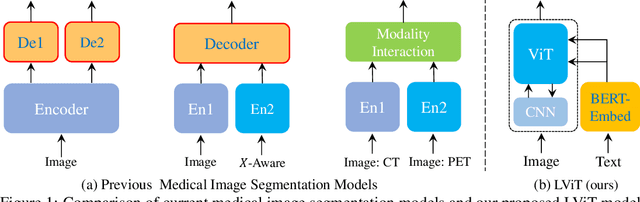
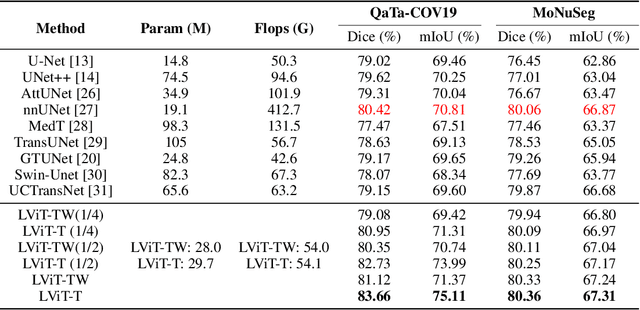
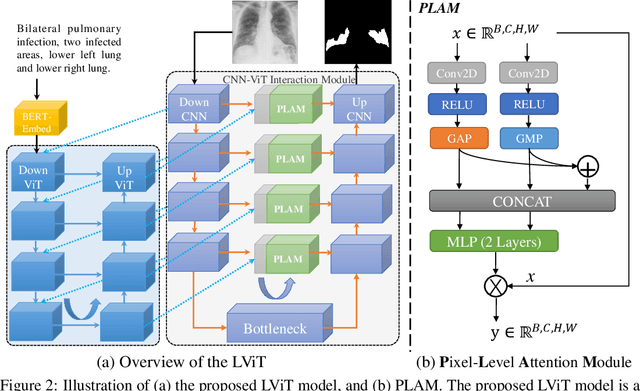
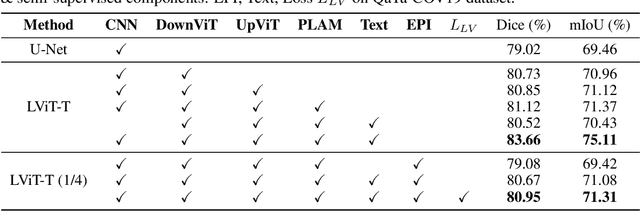
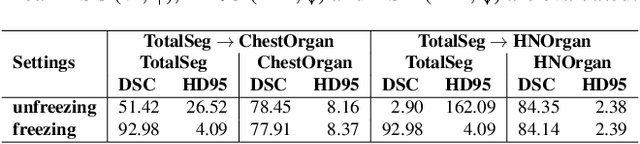
Deep learning has been widely used in medical image segmentation and other aspects. However, the performance of existing medical image segmentation models has been limited by the challenge of obtaining sufficient number of high-quality data with the high cost of data annotation. To overcome the limitation, we propose a new vision-language medical image segmentation model LViT (Language meets Vision Transformer). In our model, medical text annotation is introduced to compensate for the quality deficiency in image data. In addition, the text information can guide the generation of pseudo labels to a certain extent and further guarantee the quality of pseudo labels in semi-supervised learning. We also propose the Exponential Pseudo label Iteration mechanism (EPI) to help extend the semi-supervised version of LViT and the Pixel-Level Attention Module (PLAM) to preserve local features of images. In our model, LV (Language-Vision) loss is designed to supervise the training of unlabeled images using text information directly. To validate the performance of LViT, we construct multimodal medical segmentation datasets (image + text) containing pathological images, X-rays,etc. Experimental results show that our proposed LViT has better segmentation performance in both fully and semi-supervised conditions. Code and datasets are available at https://github.com/HUANGLIZI/LViT.