 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy We Feel: Breaking Boundaries in Emotional Reasoning with Multimodal Large Language Models
Apr 10, 2025Most existing emotion analysis emphasizes which emotion arises (e.g., happy, sad, angry) but neglects the deeper why. We propose Emotion Interpretation (EI), focusing on causal factors-whether explicit (e.g., observable objects, interpersonal interactions) or implicit (e.g., cultural context, off-screen events)-that drive emotional responses. Unlike traditional emotion recognition, EI tasks require reasoning about triggers instead of mere labeling. To facilitate EI research, we present EIBench, a large-scale benchmark encompassing 1,615 basic EI samples and 50 complex EI samples featuring multifaceted emotions. Each instance demands rationale-based explanations rather than straightforward categorization. We further propose a Coarse-to-Fine Self-Ask (CFSA) annotation pipeline, which guides Vision-Language Models (VLLMs) through iterative question-answer rounds to yield high-quality labels at scale. Extensive evaluations on open-source and proprietary large language models under four experimental settings reveal consistent performance gaps-especially for more intricate scenarios-underscoring EI's potential to enrich empathetic, context-aware AI applications. Our benchmark and methods are publicly available at: https://github.com/Lum1104/EIBench, offering a foundation for advanced multimodal causal analysis and next-generation affective computing.
A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond
Mar 27, 2025Recent Large Reasoning Models (LRMs), such as DeepSeek-R1 and OpenAI o1, have demonstrated strong performance gains by scaling up the length of Chain-of-Thought (CoT) reasoning during inference. However, a growing concern lies in their tendency to produce excessively long reasoning traces, which are often filled with redundant content (e.g., repeated definitions), over-analysis of simple problems, and superficial exploration of multiple reasoning paths for harder tasks. This inefficiency introduces significant challenges for training, inference, and real-world deployment (e.g., in agent-based systems), where token economy is critical. In this survey, we provide a comprehensive overview of recent efforts aimed at improving reasoning efficiency in LRMs, with a particular focus on the unique challenges that arise in this new paradigm. We identify common patterns of inefficiency, examine methods proposed across the LRM lifecycle, i.e., from pretraining to inference, and discuss promising future directions for research. To support ongoing development, we also maintain a real-time GitHub repository tracking recent progress in the field. We hope this survey serves as a foundation for further exploration and inspires innovation in this rapidly evolving area.
MegaSR: Mining Customized Semantics and Expressive Guidance for Image Super-Resolution
Mar 11, 2025Pioneering text-to-image (T2I) diffusion models have ushered in a new era of real-world image super-resolution (Real-ISR), significantly enhancing the visual perception of reconstructed images. However, existing methods typically integrate uniform abstract textual semantics across all blocks, overlooking the distinct semantic requirements at different depths and the fine-grained, concrete semantics inherently present in the images themselves. Moreover, relying solely on a single type of guidance further disrupts the consistency of reconstruction. To address these issues, we propose MegaSR, a novel framework that mines customized block-wise semantics and expressive guidance for diffusion-based ISR. Compared to uniform textual semantics, MegaSR enables flexible adaptation to multi-granularity semantic awareness by dynamically incorporating image attributes at each block. Furthermore, we experimentally identify HED edge maps, depth maps, and segmentation maps as the most expressive guidance, and propose a multi-stage aggregation strategy to modulate them into the T2I models. Extensive experiments demonstrate the superiority of MegaSR in terms of semantic richness and structural consistency.
UCDR-Adapter: Exploring Adaptation of Pre-Trained Vision-Language Models for Universal Cross-Domain Retrieval
Dec 14, 2024



Universal Cross-Domain Retrieval (UCDR) retrieves relevant images from unseen domains and classes without semantic labels, ensuring robust generalization. Existing methods commonly employ prompt tuning with pre-trained vision-language models but are inherently limited by static prompts, reducing adaptability. We propose UCDR-Adapter, which enhances pre-trained models with adapters and dynamic prompt generation through a two-phase training strategy. First, Source Adapter Learning integrates class semantics with domain-specific visual knowledge using a Learnable Textual Semantic Template and optimizes Class and Domain Prompts via momentum updates and dual loss functions for robust alignment. Second, Target Prompt Generation creates dynamic prompts by attending to masked source prompts, enabling seamless adaptation to unseen domains and classes. Unlike prior approaches, UCDR-Adapter dynamically adapts to evolving data distributions, enhancing both flexibility and generalization. During inference, only the image branch and generated prompts are used, eliminating reliance on textual inputs for highly efficient retrieval. Extensive benchmark experiments show that UCDR-Adapter consistently outperforms ProS in most cases and other state-of-the-art methods on UCDR, U(c)CDR, and U(d)CDR settings.
POPoS: Improving Efficient and Robust Facial Landmark Detection with Parallel Optimal Position Search
Oct 15, 2024



Achieving a balance between accuracy and efficiency is a critical challenge in facial landmark detection (FLD). This paper introduces the Parallel Optimal Position Search (POPoS), a high-precision encoding-decoding framework designed to address the fundamental limitations of traditional FLD methods. POPoS employs three key innovations: (1) Pseudo-range multilateration is utilized to correct heatmap errors, enhancing the precision of landmark localization. By integrating multiple anchor points, this approach minimizes the impact of individual heatmap inaccuracies, leading to robust overall positioning. (2) To improve the pseudo-range accuracy of selected anchor points, a new loss function, named multilateration anchor loss, is proposed. This loss function effectively enhances the accuracy of the distance map, mitigates the risk of local optima, and ensures optimal solutions. (3) A single-step parallel computation algorithm is introduced, significantly enhancing computational efficiency and reducing processing time. Comprehensive evaluations across five benchmark datasets demonstrate that POPoS consistently outperforms existing methods, particularly excelling in low-resolution scenarios with minimal computational overhead. These features establish POPoS as a highly efficient and accurate tool for FLD, with broad applicability in real-world scenarios. The code is available at https://github.com/teslatasy/PoPoS
Towards Graph Prompt Learning: A Survey and Beyond
Aug 26, 2024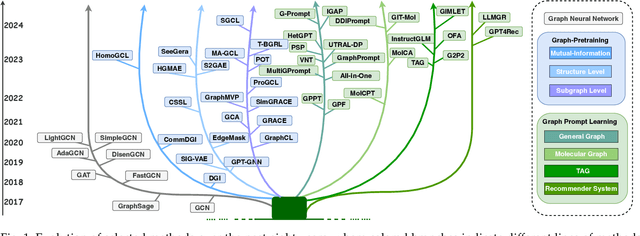
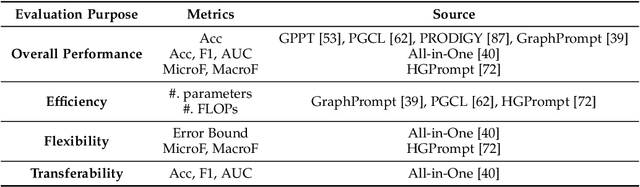
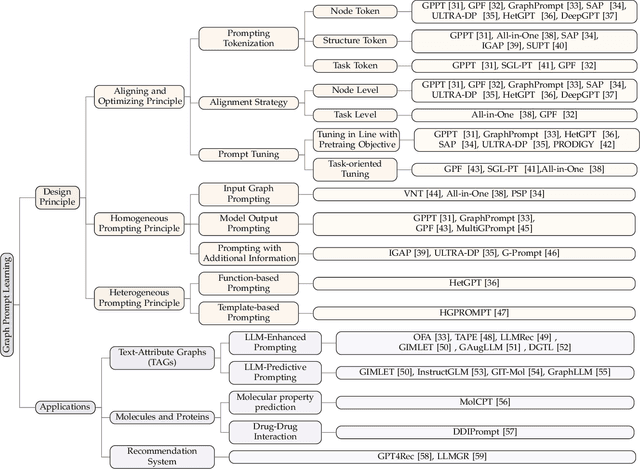
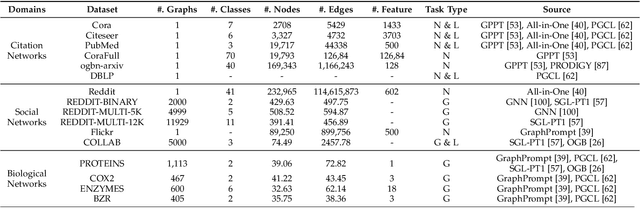
Large-scale "pre-train and prompt learning" paradigms have demonstrated remarkable adaptability, enabling broad applications across diverse domains such as question answering, image recognition, and multimodal retrieval. This approach fully leverages the potential of large-scale pre-trained models, reducing downstream data requirements and computational costs while enhancing model applicability across various tasks. Graphs, as versatile data structures that capture relationships between entities, play pivotal roles in fields such as social network analysis, recommender systems, and biological graphs. Despite the success of pre-train and prompt learning paradigms in Natural Language Processing (NLP) and Computer Vision (CV), their application in graph domains remains nascent. In graph-structured data, not only do the node and edge features often have disparate distributions, but the topological structures also differ significantly. This diversity in graph data can lead to incompatible patterns or gaps between pre-training and fine-tuning on downstream graphs. We aim to bridge this gap by summarizing methods for alleviating these disparities. This includes exploring prompt design methodologies, comparing related techniques, assessing application scenarios and datasets, and identifying unresolved problems and challenges. This survey categorizes over 100 relevant works in this field, summarizing general design principles and the latest applications, including text-attributed graphs, molecules, proteins, and recommendation systems. Through this extensive review, we provide a foundational understanding of graph prompt learning, aiming to impact not only the graph mining community but also the broader Artificial General Intelligence (AGI) community.
DisenSemi: Semi-supervised Graph Classification via Disentangled Representation Learning
Jul 19, 2024
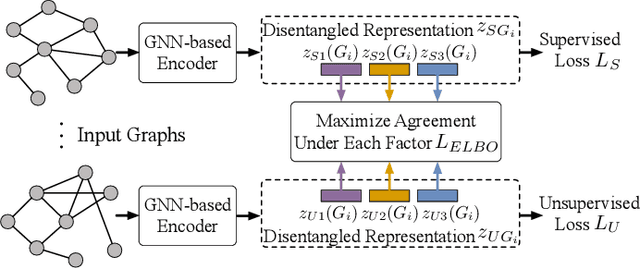


Graph classification is a critical task in numerous multimedia applications, where graphs are employed to represent diverse types of multimedia data, including images, videos, and social networks. Nevertheless, in real-world scenarios, labeled graph data can be limited or scarce. To address this issue, we focus on the problem of semi-supervised graph classification, which involves both supervised and unsupervised models learning from labeled and unlabeled data. In contrast to recent approaches that transfer the entire knowledge from the unsupervised model to the supervised one, we argue that an effective transfer should only retain the relevant semantics that align well with the supervised task. In this paper, we propose a novel framework named DisenSemi, which learns disentangled representation for semi-supervised graph classification. Specifically, a disentangled graph encoder is proposed to generate factor-wise graph representations for both supervised and unsupervised models. Then we train two models via supervised objective and mutual information (MI)-based constraints respectively. To ensure the meaningful transfer of knowledge from the unsupervised encoder to the supervised one, we further define an MI-based disentangled consistency regularization between two models and identify the corresponding rationale that aligns well with the current graph classification task. Experimental results on a range of publicly accessible datasets reveal the effectiveness of our DisenSemi.
Anti-Collapse Loss for Deep Metric Learning Based on Coding Rate Metric
Jul 03, 2024Deep metric learning (DML) aims to learn a discriminative high-dimensional embedding space for downstream tasks like classification, clustering, and retrieval. Prior literature predominantly focuses on pair-based and proxy-based methods to maximize inter-class discrepancy and minimize intra-class diversity. However, these methods tend to suffer from the collapse of the embedding space due to their over-reliance on label information. This leads to sub-optimal feature representation and inferior model performance. To maintain the structure of embedding space and avoid feature collapse, we propose a novel loss function called Anti-Collapse Loss. Specifically, our proposed loss primarily draws inspiration from the principle of Maximal Coding Rate Reduction. It promotes the sparseness of feature clusters in the embedding space to prevent collapse by maximizing the average coding rate of sample features or class proxies. Moreover, we integrate our proposed loss with pair-based and proxy-based methods, resulting in notable performance improvement. Comprehensive experiments on benchmark datasets demonstrate that our proposed method outperforms existing state-of-the-art methods. Extensive ablation studies verify the effectiveness of our method in preventing embedding space collapse and promoting generalization performance.
DEMO: A Statistical Perspective for Efficient Image-Text Matching
May 19, 2024



Image-text matching has been a long-standing problem, which seeks to connect vision and language through semantic understanding. Due to the capability to manage large-scale raw data, unsupervised hashing-based approaches have gained prominence recently. They typically construct a semantic similarity structure using the natural distance, which subsequently provides guidance to the model optimization process. However, the similarity structure could be biased at the boundaries of semantic distributions, causing error accumulation during sequential optimization. To tackle this, we introduce a novel hashing approach termed Distribution-based Structure Mining with Consistency Learning (DEMO) for efficient image-text matching. From a statistical view, DEMO characterizes each image using multiple augmented views, which are considered as samples drawn from its intrinsic semantic distribution. Then, we employ a non-parametric distribution divergence to ensure a robust and precise similarity structure. In addition, we introduce collaborative consistency learning which not only preserves the similarity structure in the Hamming space but also encourages consistency between retrieval distribution from different directions in a self-supervised manner. Through extensive experiments on three benchmark image-text matching datasets, we demonstrate that DEMO achieves superior performance compared with many state-of-the-art methods.
An Evaluation of Large Language Models in Bioinformatics Research
Feb 21, 2024



Large language models (LLMs) such as ChatGPT have gained considerable interest across diverse research communities. Their notable ability for text completion and generation has inaugurated a novel paradigm for language-interfaced problem solving. However, the potential and efficacy of these models in bioinformatics remain incompletely explored. In this work, we study the performance LLMs on a wide spectrum of crucial bioinformatics tasks. These tasks include the identification of potential coding regions, extraction of named entities for genes and proteins, detection of antimicrobial and anti-cancer peptides, molecular optimization, and resolution of educational bioinformatics problems. Our findings indicate that, given appropriate prompts, LLMs like GPT variants can successfully handle most of these tasks. In addition, we provide a thorough analysis of their limitations in the context of complicated bioinformatics tasks. In conclusion, we believe that this work can provide new perspectives and motivate future research in the field of LLMs applications, AI for Science and bioinformatics.