 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Primitive Embodied World Models: Towards Scalable Robotic Learning
Aug 28, 2025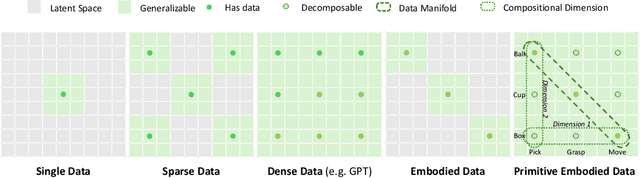



While video-generation-based embodied world models have gained increasing attention, their reliance on large-scale embodied interaction data remains a key bottleneck. The scarcity, difficulty of collection, and high dimensionality of embodied data fundamentally limit the alignment granularity between language and actions and exacerbate the challenge of long-horizon video generation--hindering generative models from achieving a "GPT moment" in the embodied domain. There is a naive observation: the diversity of embodied data far exceeds the relatively small space of possible primitive motions. Based on this insight, we propose a novel paradigm for world modeling--Primitive Embodied World Models (PEWM). By restricting video generation to fixed short horizons, our approach 1) enables fine-grained alignment between linguistic concepts and visual representations of robotic actions, 2) reduces learning complexity, 3) improves data efficiency in embodied data collection, and 4) decreases inference latency. By equipping with a modular Vision-Language Model (VLM) planner and a Start-Goal heatmap Guidance mechanism (SGG), PEWM further enables flexible closed-loop control and supports compositional generalization of primitive-level policies over extended, complex tasks. Our framework leverages the spatiotemporal vision priors in video models and the semantic awareness of VLMs to bridge the gap between fine-grained physical interaction and high-level reasoning, paving the way toward scalable, interpretable, and general-purpose embodied intelligence.
Training-Free Text-Guided Color Editing with Multi-Modal Diffusion Transformer
Aug 12, 2025

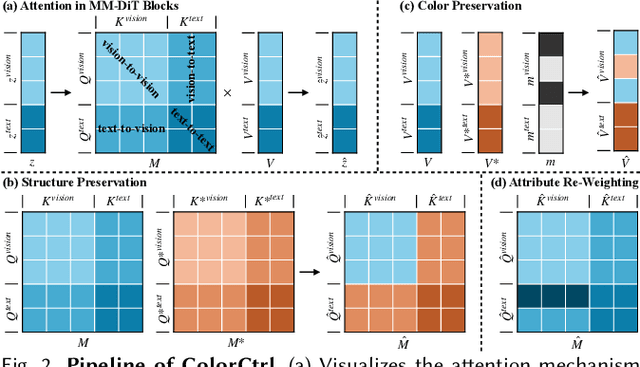
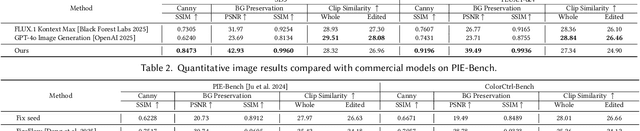
Text-guided color editing in images and videos is a fundamental yet unsolved problem, requiring fine-grained manipulation of color attributes, including albedo, light source color, and ambient lighting, while preserving physical consistency in geometry, material properties, and light-matter interactions. Existing training-free methods offer broad applicability across editing tasks but struggle with precise color control and often introduce visual inconsistency in both edited and non-edited regions. In this work, we present ColorCtrl, a training-free color editing method that leverages the attention mechanisms of modern Multi-Modal Diffusion Transformers (MM-DiT). By disentangling structure and color through targeted manipulation of attention maps and value tokens, our method enables accurate and consistent color editing, along with word-level control of attribute intensity. Our method modifies only the intended regions specified by the prompt, leaving unrelated areas untouched. Extensive experiments on both SD3 and FLUX.1-dev demonstrate that ColorCtrl outperforms existing training-free approaches and achieves state-of-the-art performances in both edit quality and consistency. Furthermore, our method surpasses strong commercial models such as FLUX.1 Kontext Max and GPT-4o Image Generation in terms of consistency. When extended to video models like CogVideoX, our approach exhibits greater advantages, particularly in maintaining temporal coherence and editing stability. Finally, our method also generalizes to instruction-based editing diffusion models such as Step1X-Edit and FLUX.1 Kontext dev, further demonstrating its versatility.
Taming Transformer Without Using Learning Rate Warmup
May 28, 2025Scaling Transformer to a large scale without using some technical tricks such as learning rate warump and using an obviously lower learning rate is an extremely challenging task, and is increasingly gaining more attention. In this paper, we provide a theoretical analysis for the process of training Transformer and reveal the rationale behind the model crash phenomenon in the training process, termed \textit{spectral energy concentration} of ${\bW_q}^{\top} \bW_k$, which is the reason for a malignant entropy collapse, where ${\bW_q}$ and $\bW_k$ are the projection matrices for the query and the key in Transformer, respectively. To remedy this problem, motivated by \textit{Weyl's Inequality}, we present a novel optimization strategy, \ie, making the weight updating in successive steps smooth -- if the ratio $\frac{\sigma_{1}(\nabla \bW_t)}{\sigma_{1}(\bW_{t-1})}$ is larger than a threshold, we will automatically bound the learning rate to a weighted multiple of $\frac{\sigma_{1}(\bW_{t-1})}{\sigma_{1}(\nabla \bW_t)}$, where $\nabla \bW_t$ is the updating quantity in step $t$. Such an optimization strategy can prevent spectral energy concentration to only a few directions, and thus can avoid malignant entropy collapse which will trigger the model crash. We conduct extensive experiments using ViT, Swin-Transformer and GPT, showing that our optimization strategy can effectively and stably train these Transformers without using learning rate warmup.
Unposed Sparse Views Room Layout Reconstruction in the Age of Pretrain Model
Feb 24, 2025Room layout estimation from multiple-perspective images is poorly investigated due to the complexities that emerge from multi-view geometry, which requires muti-step solutions such as camera intrinsic and extrinsic estimation, image matching, and triangulation. However, in 3D reconstruction, the advancement of recent 3D foundation models such as DUSt3R has shifted the paradigm from the traditional multi-step structure-from-motion process to an end-to-end single-step approach. To this end, we introduce Plane-DUSt3R}, a novel method for multi-view room layout estimation leveraging the 3D foundation model DUSt3R. Plane-DUSt3R incorporates the DUSt3R framework and fine-tunes on a room layout dataset (Structure3D) with a modified objective to estimate structural planes. By generating uniform and parsimonious results, Plane-DUSt3R enables room layout estimation with only a single post-processing step and 2D detection results. Unlike previous methods that rely on single-perspective or panorama image, Plane-DUSt3R extends the setting to handle multiple-perspective images. Moreover, it offers a streamlined, end-to-end solution that simplifies the process and reduces error accumulation. Experimental results demonstrate that Plane-DUSt3R not only outperforms state-of-the-art methods on the synthetic dataset but also proves robust and effective on in the wild data with different image styles such as cartoon.
BIFRÖST: 3D-Aware Image compositing with Language Instructions
Oct 24, 2024This paper introduces Bifr\"ost, a novel 3D-aware framework that is built upon diffusion models to perform instruction-based image composition. Previous methods concentrate on image compositing at the 2D level, which fall short in handling complex spatial relationships ($\textit{e.g.}$, occlusion). Bifr\"ost addresses these issues by training MLLM as a 2.5D location predictor and integrating depth maps as an extra condition during the generation process to bridge the gap between 2D and 3D, which enhances spatial comprehension and supports sophisticated spatial interactions. Our method begins by fine-tuning MLLM with a custom counterfactual dataset to predict 2.5D object locations in complex backgrounds from language instructions. Then, the image-compositing model is uniquely designed to process multiple types of input features, enabling it to perform high-fidelity image compositions that consider occlusion, depth blur, and image harmonization. Extensive qualitative and quantitative evaluations demonstrate that Bifr\"ost significantly outperforms existing methods, providing a robust solution for generating realistically composed images in scenarios demanding intricate spatial understanding. This work not only pushes the boundaries of generative image compositing but also reduces reliance on expensive annotated datasets by effectively utilizing existing resources in innovative ways.
Anti-Collapse Loss for Deep Metric Learning Based on Coding Rate Metric
Jul 03, 2024Deep metric learning (DML) aims to learn a discriminative high-dimensional embedding space for downstream tasks like classification, clustering, and retrieval. Prior literature predominantly focuses on pair-based and proxy-based methods to maximize inter-class discrepancy and minimize intra-class diversity. However, these methods tend to suffer from the collapse of the embedding space due to their over-reliance on label information. This leads to sub-optimal feature representation and inferior model performance. To maintain the structure of embedding space and avoid feature collapse, we propose a novel loss function called Anti-Collapse Loss. Specifically, our proposed loss primarily draws inspiration from the principle of Maximal Coding Rate Reduction. It promotes the sparseness of feature clusters in the embedding space to prevent collapse by maximizing the average coding rate of sample features or class proxies. Moreover, we integrate our proposed loss with pair-based and proxy-based methods, resulting in notable performance improvement. Comprehensive experiments on benchmark datasets demonstrate that our proposed method outperforms existing state-of-the-art methods. Extensive ablation studies verify the effectiveness of our method in preventing embedding space collapse and promoting generalization performance.
Ctrl123: Consistent Novel View Synthesis via Closed-Loop Transcription
Mar 16, 2024



Large image diffusion models have demonstrated zero-shot capability in novel view synthesis (NVS). However, existing diffusion-based NVS methods struggle to generate novel views that are accurately consistent with the corresponding ground truth poses and appearances, even on the training set. This consequently limits the performance of downstream tasks, such as image-to-multiview generation and 3D reconstruction. We realize that such inconsistency is largely due to the fact that it is difficult to enforce accurate pose and appearance alignment directly in the diffusion training, as mostly done by existing methods such as Zero123. To remedy this problem, we propose Ctrl123, a closed-loop transcription-based NVS diffusion method that enforces alignment between the generated view and ground truth in a pose-sensitive feature space. Our extensive experiments demonstrate the effectiveness of Ctrl123 on the tasks of NVS and 3D reconstruction, achieving significant improvements in both multiview-consistency and pose-consistency over existing methods.
Image Clustering via the Principle of Rate Reduction in the Age of Pretrained Models
Jun 09, 2023



The advent of large pre-trained models has brought about a paradigm shift in both visual representation learning and natural language processing. However, clustering unlabeled images, as a fundamental and classic machine learning problem, still lacks effective solution, particularly for large-scale datasets. In this paper, we propose a novel image clustering pipeline that leverages the powerful feature representation of large pre-trained models such as CLIP and cluster images effectively and efficiently at scale. We show that the pre-trained features are significantly more structured by further optimizing the rate reduction objective. The resulting features may significantly improve the clustering accuracy, e.g., from 57\% to 66\% on ImageNet-1k. Furthermore, by leveraging CLIP's image-text binding, we show how the new clustering method leads to a simple yet effective self-labeling algorithm that successfully works on unlabeled large datasets such as MS-COCO and LAION-Aesthetics. We will release the code in https://github.com/LeslieTrue/CPP.
Closed-Loop Transcription via Convolutional Sparse Coding
Feb 18, 2023



Autoencoding has achieved great empirical success as a framework for learning generative models for natural images. Autoencoders often use generic deep networks as the encoder or decoder, which are difficult to interpret, and the learned representations lack clear structure. In this work, we make the explicit assumption that the image distribution is generated from a multi-stage sparse deconvolution. The corresponding inverse map, which we use as an encoder, is a multi-stage convolution sparse coding (CSC), with each stage obtained from unrolling an optimization algorithm for solving the corresponding (convexified) sparse coding program. To avoid computational difficulties in minimizing distributional distance between the real and generated images, we utilize the recent closed-loop transcription (CTRL) framework that optimizes the rate reduction of the learned sparse representations. Conceptually, our method has high-level connections to score-matching methods such as diffusion models. Empirically, our framework demonstrates competitive performance on large-scale datasets, such as ImageNet-1K, compared to existing autoencoding and generative methods under fair conditions. Even with simpler networks and fewer computational resources, our method demonstrates high visual quality in regenerated images. More surprisingly, the learned autoencoder performs well on unseen datasets. Our method enjoys several side benefits, including more structured and interpretable representations, more stable convergence, and scalability to large datasets. Our method is arguably the first to demonstrate that a concatenation of multiple convolution sparse coding/decoding layers leads to an interpretable and effective autoencoder for modeling the distribution of large-scale natural image datasets.
Unsupervised Manifold Linearizing and Clustering
Jan 04, 2023Clustering data lying close to a union of low-dimensional manifolds, with each manifold as a cluster, is a fundamental problem in machine learning. When the manifolds are assumed to be linear subspaces, many methods succeed using low-rank and sparse priors, which have been studied extensively over the past two decades. Unfortunately, most real-world datasets can not be well approximated by linear subspaces. On the other hand, several works have proposed to identify the manifolds by learning a feature map such that the data transformed by the map lie in a union of linear subspaces, even though the original data are from non-linear manifolds. However, most works either assume knowledge of the membership of samples to clusters, or are shown to learn trivial representations. In this paper, we propose to simultaneously perform clustering and learn a union-of-subspace representation via Maximal Coding Rate Reduction. Experiments on synthetic and realistic datasets show that the proposed method achieves clustering accuracy comparable with state-of-the-art alternatives, while being more scalable and learning geometrically meaningful representations.