 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASTE-Rob: Advancing Video Generation of Task-Oriented Hand-Object Interaction for Generalizable Robotic Manipulation
Mar 14, 2025

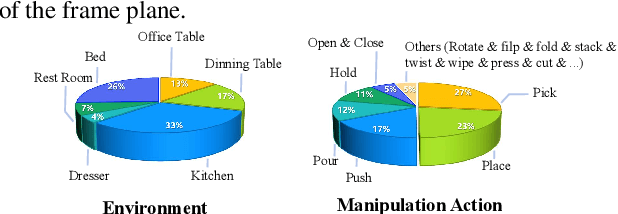
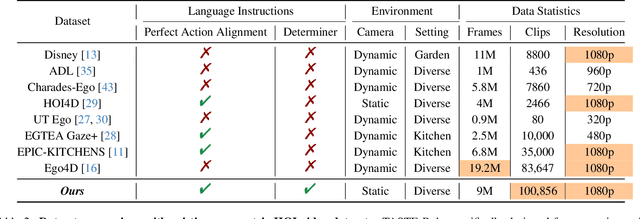
We address key limitations in existing datasets and models for task-oriented hand-object interaction video generation, a critical approach of generating video demonstrations for robotic imitation learning. Current datasets, such as Ego4D, often suffer from inconsistent view perspectives and misaligned interactions, leading to reduced video quality and limiting their applicability for precise imitation learning tasks. Towards this end, we introduce TASTE-Rob -- a pioneering large-scale dataset of 100,856 ego-centric hand-object interaction videos. Each video is meticulously aligned with language instructions and recorded from a consistent camera viewpoint to ensure interaction clarity. By fine-tuning a Video Diffusion Model (VDM) on TASTE-Rob, we achieve realistic object interactions, though we observed occasional inconsistencies in hand grasping postures. To enhance realism, we introduce a three-stage pose-refinement pipeline that improves hand posture accuracy in generated videos. Our curated dataset, coupled with the specialized pose-refinement framework, provides notable performance gains in generating high-quality, task-oriented hand-object interaction videos, resulting in achieving superior generalizable robotic manipulation. The TASTE-Rob dataset will be made publicly available upon publication to foster further advancements in the field.
Ctrl123: Consistent Novel View Synthesis via Closed-Loop Transcription
Mar 16, 2024



Large image diffusion models have demonstrated zero-shot capability in novel view synthesis (NVS). However, existing diffusion-based NVS methods struggle to generate novel views that are accurately consistent with the corresponding ground truth poses and appearances, even on the training set. This consequently limits the performance of downstream tasks, such as image-to-multiview generation and 3D reconstruction. We realize that such inconsistency is largely due to the fact that it is difficult to enforce accurate pose and appearance alignment directly in the diffusion training, as mostly done by existing methods such as Zero123. To remedy this problem, we propose Ctrl123, a closed-loop transcription-based NVS diffusion method that enforces alignment between the generated view and ground truth in a pose-sensitive feature space. Our extensive experiments demonstrate the effectiveness of Ctrl123 on the tasks of NVS and 3D reconstruction, achieving significant improvements in both multiview-consistency and pose-consistency over existing methods.