 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni123: Exploring 3D Native Foundation Models with Limited 3D Data by Unifying Text to 2D and 3D Generation
Apr 02, 2026Recent multimodal large language models have achieved strong performance in unified text and image understanding and generation, yet extending such native capability to 3D remains challenging due to limited data. Compared to abundant 2D imagery, high-quality 3D assets are scarce, making 3D synthesis under-constrained. Existing methods often rely on indirect pipelines that edit in 2D and lift results into 3D via optimization, sacrificing geometric consistency. We present Omni123, a 3D-native foundation model that unifies text-to-2D and text-to-3D generation within a single autoregressive framework. Our key insight is that cross-modal consistency between images and 3D can serve as an implicit structural constraint. By representing text, images, and 3D as discrete tokens in a shared sequence space, the model leverages abundant 2D data as a geometric prior to improve 3D representations. We introduce an interleaved X-to-X training paradigm that coordinates diverse cross-modal tasks over heterogeneous paired datasets without requiring fully aligned text-image-3D triplets. By traversing semantic-visual-geometric cycles (e.g., text to image to 3D to image) within autoregressive sequences, the model jointly enforces semantic alignment, appearance fidelity, and multi-view geometric consistency. Experiments show that Omni123 significantly improves text-guided 3D generation and editing, demonstrating a scalable path toward multimodal 3D world models.
LoFA: Learning to Predict Personalized Priors for Fast Adaptation of Visual Generative Models
Dec 09, 2025Personalizing visual generative models to meet specific user needs has gained increasing attention, yet current methods like Low-Rank Adaptation (LoRA) remain impractical due to their demand for task-specific data and lengthy optimization. While a few hypernetwork-based approaches attempt to predict adaptation weights directly, they struggle to map fine-grained user prompts to complex LoRA distributions, limiting their practical applicability. To bridge this gap, we propose LoFA, a general framework that efficiently predicts personalized priors for fast model adaptation. We first identify a key property of LoRA: structured distribution patterns emerge in the relative changes between LoRA and base model parameters. Building on this, we design a two-stage hypernetwork: first predicting relative distribution patterns that capture key adaptation regions, then using these to guide final LoRA weight prediction. Extensive experiments demonstrate that our method consistently predicts high-quality personalized priors within seconds, across multiple tasks and user prompts, even outperforming conventional LoRA that requires hours of processing. Project page: https://jaeger416.github.io/lofa/.
TASTE-Rob: Advancing Video Generation of Task-Oriented Hand-Object Interaction for Generalizable Robotic Manipulation
Mar 14, 2025

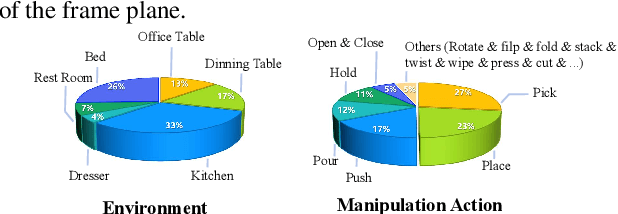
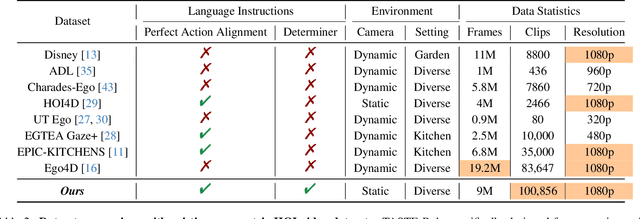
We address key limitations in existing datasets and models for task-oriented hand-object interaction video generation, a critical approach of generating video demonstrations for robotic imitation learning. Current datasets, such as Ego4D, often suffer from inconsistent view perspectives and misaligned interactions, leading to reduced video quality and limiting their applicability for precise imitation learning tasks. Towards this end, we introduce TASTE-Rob -- a pioneering large-scale dataset of 100,856 ego-centric hand-object interaction videos. Each video is meticulously aligned with language instructions and recorded from a consistent camera viewpoint to ensure interaction clarity. By fine-tuning a Video Diffusion Model (VDM) on TASTE-Rob, we achieve realistic object interactions, though we observed occasional inconsistencies in hand grasping postures. To enhance realism, we introduce a three-stage pose-refinement pipeline that improves hand posture accuracy in generated videos. Our curated dataset, coupled with the specialized pose-refinement framework, provides notable performance gains in generating high-quality, task-oriented hand-object interaction videos, resulting in achieving superior generalizable robotic manipulation. The TASTE-Rob dataset will be made publicly available upon publication to foster further advancements in the field.
Deep Reward Supervisions for Tuning Text-to-Image Diffusion Models
May 01, 2024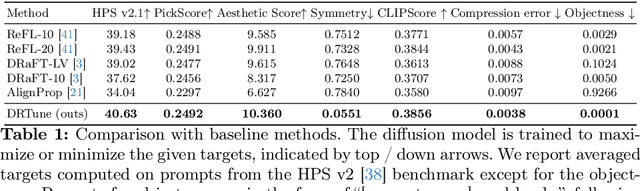
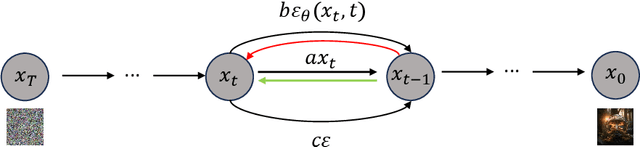
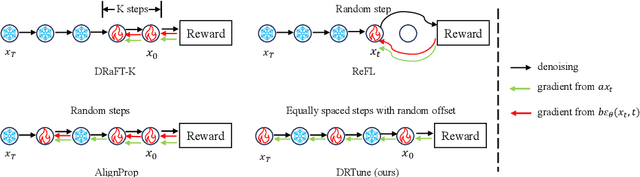

Optimizing a text-to-image diffusion model with a given reward function is an important but underexplored research area. In this study, we propose Deep Reward Tuning (DRTune), an algorithm that directly supervises the final output image of a text-to-image diffusion model and back-propagates through the iterative sampling process to the input noise. We find that training earlier steps in the sampling process is crucial for low-level rewards, and deep supervision can be achieved efficiently and effectively by stopping the gradient of the denoising network input. DRTune is extensively evaluated on various reward models. It consistently outperforms other algorithms, particularly for low-level control signals, where all shallow supervision methods fail. Additionally, we fine-tune Stable Diffusion XL 1.0 (SDXL 1.0) model via DRTune to optimize Human Preference Score v2.1, resulting in the Favorable Diffusion XL 1.0 (FDXL 1.0) model. FDXL 1.0 significantly enhances image quality compared to SDXL 1.0 and reaches comparable quality compared with Midjourney v5.2.
Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis
Jun 15, 2023



Recent text-to-image generative models can generate high-fidelity images from text inputs, but the quality of these generated images cannot be accurately evaluated by existing evaluation metrics. To address this issue, we introduce Human Preference Dataset v2 (HPD v2), a large-scale dataset that captures human preferences on images from a wide range of sources. HPD v2 comprises 798,090 human preference choices on 430,060 pairs of images, making it the largest dataset of its kind. The text prompts and images are deliberately collected to eliminate potential bias, which is a common issue in previous datasets. By fine-tuning CLIP on HPD v2, we obtain Human Preference Score v2 (HPS v2), a scoring model that can more accurately predict text-generated images' human preferences. Our experiments demonstrate that HPS v2 generalizes better than previous metrics across various image distributions and is responsive to algorithmic improvements of text-to-image generative models, making it a preferable evaluation metric for these models. We also investigate the design of the evaluation prompts for text-to-image generative models, to make the evaluation stable, fair and easy-to-use. Finally, we establish a benchmark for text-to-image generative models using HPS v2, which includes a set of recent text-to-image models from the academia, community and industry. The code and dataset is / will be available at https://github.com/tgxs002/HPSv2.
Perception Imitation: Towards Synthesis-free Simulator for Autonomous Vehicles
Apr 19, 2023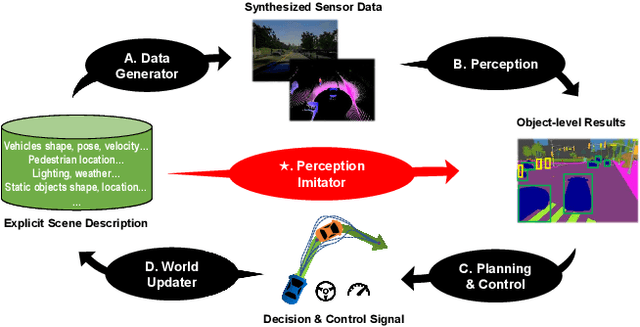
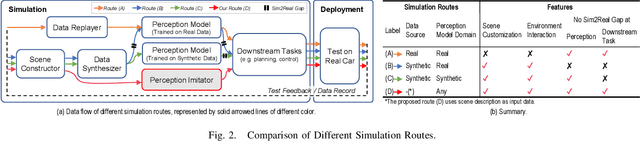
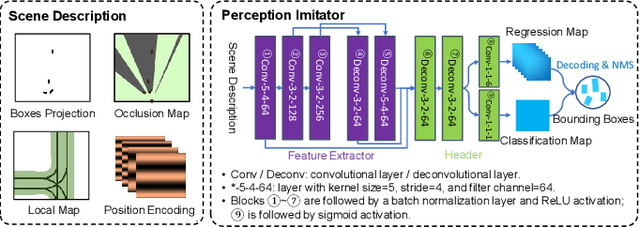
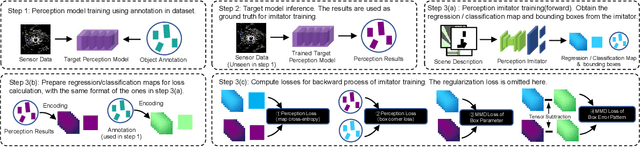
We propose a perception imitation method to simulate results of a certain perception model, and discuss a new heuristic route of autonomous driving simulator without data synthesis. The motivation is that original sensor data is not always necessary for tasks such as planning and control when semantic perception results are ready, so that simulating perception directly is more economic and efficient. In this work, a series of evaluation methods such as matching metric and performance of downstream task are exploited to examine the simulation quality. Experiments show that our method is effective to model the behavior of learning-based perception model, and can be further applied in the proposed simulation route smoothly.