 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
BudgetDraft: Acceptance-Aware Multi-View Training for Sparse-KV Speculative Decoding
May 29, 2026Speculative decoding speeds up autoregressive decoding by using a drafter to propose multiple tokens that a verifier validates in parallel. In resource-constrained deployments, the drafter uses a sparse KV cache to limit peak GPU memory and end-to-end latency under a fixed KV budget, while the verifier keeps a full KV cache. Mid-to-long context inference (4K--16K context length) is common in real applications. However, naive sparse/full speculative decoding suffers from the sparse/full mismatch as context length grows, causing the acceptance rate to drop quickly. We propose BudgetDraft, a multi-view sparse training method for sparse drafting in mid-to-long inference. The drafter is exposed to multiple sampled KV budgets during training and learns to align each sparse view with one shared full-cache teacher target. BudgetDraft combines an acceptance-aware loss on a full-cache branch with a multi-view loss on a sparse-cache branch, producing a single budget-robust drafter that recovers acceptance across sparsity levels without extra inference-time components. Experimental results on PG-19, LongBench, and LWM show that BudgetDraft achieves up to 6.55x, 4.46x, and 2.10x end-to-end speedup vs AR at 4K, 8K, and 16K context lengths, while keeping the inference pipeline memory-friendly.
DeepTumorVQA: A Hierarchical 3D CT Benchmark for Stage-Wise Evaluation of Medical VLMs and Tool-Augmented Agents
May 10, 2026Medical vision-language models (VLMs) and AI agents have made significant progress in learning to analyze and reason about clinical images. However, existing medical visual question answering (VQA) benchmarks collapse model capabilities into a single accuracy score, obscuring where and why models fail. We propose DeepTumorVQA, a hierarchical benchmark that follows the multi-stage evidence chain in tumor diagnosis and decomposes 3D CT reasoning into four stages: recognition, measurement, visual reasoning, and medical reasoning. Higher-level questions remain independently scorable, while their ground-truth evidence chains are defined over lower-level primitives. The benchmark contains 476K questions across 42 clinical subtypes on 9,262 3D CT volumes. In addition to a direct reasoning mode for VLMs, DeepTumorVQA provides tool-interaction environments for agent evaluation, where a model can call external tools, including segmentation models, measurement programs, and medical knowledge modules, before answering the question. Evaluating over 30 model configurations, we find that reliable quantitative measurement is the primary bottleneck, making later-stage visual and medical reasoning harder for VLMs, while tool augmentation substantially mitigates this issue. When tools are available, leveraging medical knowledge and tools to reason about medical images becomes a new challenge. We further show that ground-truth step-by-step tool-use traces from DeepTumorVQA can supervise agents and reduce tool-use and reasoning failures. This stage-wise progression from recognition to measurement to visual and medical reasoning provides a concrete roadmap for future medical VLM and AI agent studies. All data and code are released at https://github.com/Schuture/DeepTumorVQA.
A Hybrid Quantum-Classical Framework for Financial Volatility Forecasting Based on Quantum Circuit Born Machines
Mar 10, 2026Accurate forecasting of financial market volatility is crucial for risk management, option pricing, and portfolio optimization. Traditional econometric models and classical machine learning methods face challenges in handling the inherent non-linear and non-stationary characteristics of financial time series. In recent years, the rapid development of quantum computing has provided a new paradigm for solving complex optimization and sampling problems. This paper proposes a novel hybrid quantum-classical computing framework aimed at combining the powerful representation capabilities of classical neural networks with the unique advantages of quantum models. For the specific task of financial market volatility forecasting, we designed and implemented a hybrid model based on this framework, which combines a Long Short-Term Memory (LSTM) network with a Quantum Circuit Born Machine (QCBM). The LSTM is responsible for extracting complex dynamic features from historical time series data, while the QCBM serves as a learnable prior module, providing the model with a high-quality prior distribution to guide the forecasting process. We evaluated the model on two real financial datasets consisting of 5-minute high-frequency data from the Shanghai Stock Exchange (SSE) Composite Index and CSI 300 Index. Experimental results show that, compared to a purely classical LSTM baseline model, our hybrid quantum-classical model demonstrates significant advantages across multiple key metrics, including Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and QLIKE loss, proving the great potential of quantum computing in enhancing the capabilities of financial forecasting models. More broadly, the proposed hybrid framework offers a flexible architecture that may be adapted to other machine learning tasks involving high-dimensional, complex, or non-linear data distributions.
Meissa: Multi-modal Medical Agentic Intelligence
Mar 09, 2026Multi-modal large language models (MM-LLMs) have shown strong performance in medical image understanding and clinical reasoning. Recent medical agent systems extend them with tool use and multi-agent collaboration, enabling complex decision-making. However, these systems rely almost entirely on frontier models (e.g., GPT), whose API-based deployment incurs high cost, high latency, and privacy risks that conflict with on-premise clinical requirements. We present Meissa, a lightweight 4B-parameter medical MM-LLM that brings agentic capability offline. Instead of imitating static answers, Meissa learns both when to engage external interaction (strategy selection) and how to execute multi-step interaction (strategy execution) by distilling structured trajectories from frontier models. Specifically, we propose: (1) Unified trajectory modeling: trajectories (reasoning and action traces) are represented within a single state-action-observation formalism, allowing one model to generalize across heterogeneous medical environments. (2) Three-tier stratified supervision: the model's own errors trigger progressive escalation from direct reasoning to tool-augmented and multi-agent interaction, explicitly learning difficulty-aware strategy selection. (3) Prospective-retrospective supervision: pairing exploratory forward traces with hindsight-rationalized execution traces enables stable learning of effective interaction policies. Trained on 40K curated trajectories, Meissa matches or exceeds proprietary frontier agents in 10 of 16 evaluation settings across 13 medical benchmarks spanning radiology, pathology, and clinical reasoning. Using over 25x fewer parameters than typical frontier models like Gemini-3, Meissa operates fully offline with 22x lower end-to-end latency compared to API-based deployment. Data, models, and environments are released at https://github.com/Schuture/Meissa.
Large-Scale Label Quality Assessment for Medical Segmentation via a Vision-Language Judge and Synthetic Data
Jan 20, 2026Large-scale medical segmentation datasets often combine manual and pseudo-labels of uneven quality, which can compromise training and evaluation. Low-quality labels may hamper performance and make the model training less robust. To address this issue, we propose SegAE (Segmentation Assessment Engine), a lightweight vision-language model (VLM) that automatically predicts label quality across 142 anatomical structures. Trained on over four million image-label pairs with quality scores, SegAE achieves a high correlation coefficient of 0.902 with ground-truth Dice similarity and evaluates a 3D mask in 0.06s. SegAE shows several practical benefits: (I) Our analysis reveals widespread low-quality labeling across public datasets; (II) SegAE improves data efficiency and training performance in active and semi-supervised learning, reducing dataset annotation cost by one-third and quality-checking time by 70% per label. This tool provides a simple and effective solution for quality control in large-scale medical segmentation datasets. The dataset, model weights, and codes are released at https://github.com/Schuture/SegAE.
Are Vision Language Models Ready for Clinical Diagnosis? A 3D Medical Benchmark for Tumor-centric Visual Question Answering
May 25, 2025Vision-Language Models (VLMs) have shown promise in various 2D visual tasks, yet their readiness for 3D clinical diagnosis remains unclear due to stringent demands for recognition precision, reasoning ability, and domain knowledge. To systematically evaluate these dimensions, we present DeepTumorVQA, a diagnostic visual question answering (VQA) benchmark targeting abdominal tumors in CT scans. It comprises 9,262 CT volumes (3.7M slices) from 17 public datasets, with 395K expert-level questions spanning four categories: Recognition, Measurement, Visual Reasoning, and Medical Reasoning. DeepTumorVQA introduces unique challenges, including small tumor detection and clinical reasoning across 3D anatomy. Benchmarking four advanced VLMs (RadFM, M3D, Merlin, CT-CHAT), we find current models perform adequately on measurement tasks but struggle with lesion recognition and reasoning, and are still not meeting clinical needs. Two key insights emerge: (1) large-scale multimodal pretraining plays a crucial role in DeepTumorVQA testing performance, making RadFM stand out among all VLMs. (2) Our dataset exposes critical differences in VLM components, where proper image preprocessing and design of vision modules significantly affect 3D perception. To facilitate medical multimodal research, we have released DeepTumorVQA as a rigorous benchmark: https://github.com/Schuture/DeepTumorVQA.
CoCa-CXR: Contrastive Captioners Learn Strong Temporal Structures for Chest X-Ray Vision-Language Understanding
Feb 27, 2025Vision-language models have proven to be of great benefit for medical image analysis since they learn rich semantics from both images and reports. Prior efforts have focused on better alignment of image and text representations to enhance image understanding. However, though explicit reference to a prior image is common in Chest X-Ray (CXR) reports, aligning progression descriptions with the semantics differences in image pairs remains under-explored. In this work, we propose two components to address this issue. (1) A CXR report processing pipeline to extract temporal structure. It processes reports with a large language model (LLM) to separate the description and comparison contexts, and extracts fine-grained annotations from reports. (2) A contrastive captioner model for CXR, namely CoCa-CXR, to learn how to both describe images and their temporal progressions. CoCa-CXR incorporates a novel regional cross-attention module to identify local differences between paired CXR images. Extensive experiments show the superiority of CoCa-CXR on both progression analysis and report generation compared to previous methods. Notably, on MS-CXR-T progression classification, CoCa-CXR obtains 65.0% average testing accuracy on five pulmonary conditions, outperforming the previous state-of-the-art (SOTA) model BioViL-T by 4.8%. It also achieves a RadGraph F1 of 24.2% on MIMIC-CXR, which is comparable to the Med-Gemini foundation model.
MoLE: Enhancing Human-centric Text-to-image Diffusion via Mixture of Low-rank Experts
Oct 30, 2024



Text-to-image diffusion has attracted vast attention due to its impressive image-generation capabilities. However, when it comes to human-centric text-to-image generation, particularly in the context of faces and hands, the results often fall short of naturalness due to insufficient training priors. We alleviate the issue in this work from two perspectives. 1) From the data aspect, we carefully collect a human-centric dataset comprising over one million high-quality human-in-the-scene images and two specific sets of close-up images of faces and hands. These datasets collectively provide a rich prior knowledge base to enhance the human-centric image generation capabilities of the diffusion model. 2) On the methodological front, we propose a simple yet effective method called Mixture of Low-rank Experts (MoLE) by considering low-rank modules trained on close-up hand and face images respectively as experts. This concept draws inspiration from our observation of low-rank refinement, where a low-rank module trained by a customized close-up dataset has the potential to enhance the corresponding image part when applied at an appropriate scale. To validate the superiority of MoLE in the context of human-centric image generation compared to state-of-the-art, we construct two benchmarks and perform evaluations with diverse metrics and human studies. Datasets, model, and code are released at https://sites.google.com/view/mole4diffuser/.
AbdomenAtlas: A Large-Scale, Detailed-Annotated, & Multi-Center Dataset for Efficient Transfer Learning and Open Algorithmic Benchmarking
Jul 23, 2024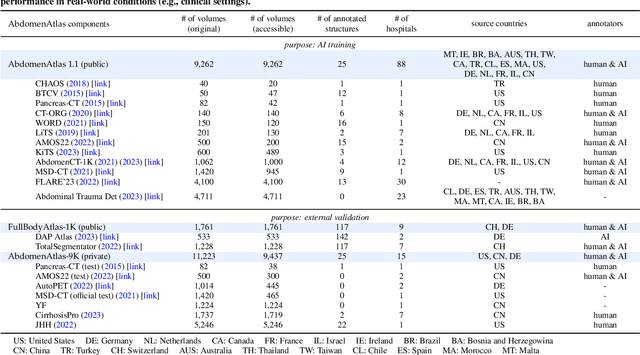


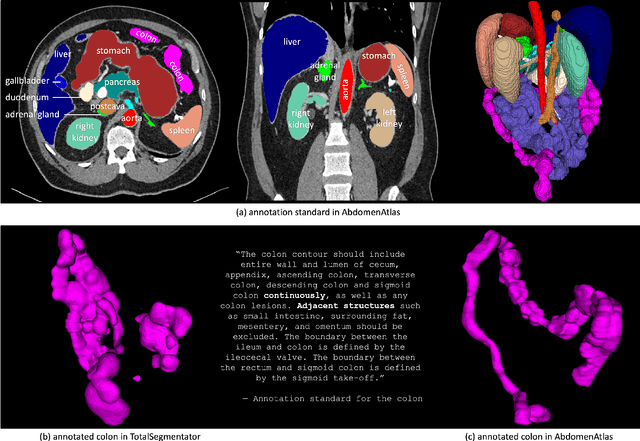
We introduce the largest abdominal CT dataset (termed AbdomenAtlas) of 20,460 three-dimensional CT volumes sourced from 112 hospitals across diverse populations, geographies, and facilities. AbdomenAtlas provides 673K high-quality masks of anatomical structures in the abdominal region annotated by a team of 10 radiologists with the help of AI algorithms. We start by having expert radiologists manually annotate 22 anatomical structures in 5,246 CT volumes. Following this, a semi-automatic annotation procedure is performed for the remaining CT volumes, where radiologists revise the annotations predicted by AI, and in turn, AI improves its predictions by learning from revised annotations. Such a large-scale, detailed-annotated, and multi-center dataset is needed for two reasons. Firstly, AbdomenAtlas provides important resources for AI development at scale, branded as large pre-trained models, which can alleviate the annotation workload of expert radiologists to transfer to broader clinical applications. Secondly, AbdomenAtlas establishes a large-scale benchmark for evaluating AI algorithms -- the more data we use to test the algorithms, the better we can guarantee reliable performance in complex clinical scenarios. An ISBI & MICCAI challenge named BodyMaps: Towards 3D Atlas of Human Body was launched using a subset of our AbdomenAtlas, aiming to stimulate AI innovation and to benchmark segmentation accuracy, inference efficiency, and domain generalizability. We hope our AbdomenAtlas can set the stage for larger-scale clinical trials and offer exceptional opportunities to practitioners in the medical imaging community. Codes, models, and datasets are available at https://www.zongweiz.com/dataset