 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLUBench: A Clustering Benchmark
May 28, 2026Clustering is a fundamental problem in data science with a long-standing research history, yielding numerous insightful algorithms. Despite this progress, a systematic and large-scale empirical evaluation that jointly considers conventional algorithms, deep learning-based methods, and recent foundation model-based clustering remains largely absent, leading to limited guidance on algorithm selection and deployment. To address this gap, we introduce CLUBench, a comprehensive clustering benchmark comprising 24 algorithms of diverse principles evaluated on 131 datasets across tabular, text, and image data, involving 178,815 experiments. Importantly, our analyses of (i) the impact of hyperparameter tuning,(ii) the impact of data types and characteristics,(iii) the impact of pretrained embeddings,(iv) large language model-based clustering,(v) the similarity of algorithms, and (vi) the low-rank structures of performance matrices, yield meaningful insights and promising pathways for clustering research. For instance, our study reveals that: 1) All evaluated deep clustering methods do not exhibit a significant advantage compared with the top-performing conventional clustering algorithms (e.g., KMeans, SpeClu) in terms of average performance; 2) For image and text clustering tasks, combining pretrained embeddings with conventional clustering algorithms (e.g., KMeans, SpeClu) offers effective and efficient clustering; 3) Clustering remains a challenging and nontrivial problem, even in the era of increasingly dominant foundation models. Moreover, we propose to use the low-rank structure in cross-model performance matrices to efficiently approximate the overall performance evaluation in practical applications. We further demonstrate the feasibility of model selection based on the performance matrices across all hyperparameter configurations.
FTDMamba: Frequency-Assisted Temporal Dilation Mamba for Unmanned Aerial Vehicle Video Anomaly Detection
Jan 16, 2026Recent advances in video anomaly detection (VAD) mainly focus on ground-based surveillance or unmanned aerial vehicle (UAV) videos with static backgrounds, whereas research on UAV videos with dynamic backgrounds remains limited. Unlike static scenarios, dynamically captured UAV videos exhibit multi-source motion coupling, where the motion of objects and UAV-induced global motion are intricately intertwined. Consequently, existing methods may misclassify normal UAV movements as anomalies or fail to capture true anomalies concealed within dynamic backgrounds. Moreover, many approaches do not adequately address the joint modeling of inter-frame continuity and local spatial correlations across diverse temporal scales. To overcome these limitations, we propose the Frequency-Assisted Temporal Dilation Mamba (FTDMamba) network for UAV VAD, including two core components: (1) a Frequency Decoupled Spatiotemporal Correlation Module, which disentangles coupled motion patterns and models global spatiotemporal dependencies through frequency analysis; and (2) a Temporal Dilation Mamba Module, which leverages Mamba's sequence modeling capability to jointly learn fine-grained temporal dynamics and local spatial structures across multiple temporal receptive fields. Additionally, unlike existing UAV VAD datasets which focus on static backgrounds, we construct a large-scale Moving UAV VAD dataset (MUVAD), comprising 222,736 frames with 240 anomaly events across 12 anomaly types. Extensive experiments demonstrate that FTDMamba achieves state-of-the-art (SOTA) performance on two public static benchmarks and the new MUVAD dataset. The code and MUVAD dataset will be available at: https://github.com/uavano/FTDMamba.
DualNILM: Energy Injection Identification Enabled Disaggregation with Deep Multi-Task Learning
Aug 20, 2025Non-Intrusive Load Monitoring (NILM) offers a cost-effective method to obtain fine-grained appliance-level energy consumption in smart homes and building applications. However, the increasing adoption of behind-the-meter energy sources, such as solar panels and battery storage, poses new challenges for conventional NILM methods that rely solely on at-the-meter data. The injected energy from the behind-the-meter sources can obscure the power signatures of individual appliances, leading to a significant decline in NILM performance. To address this challenge, we present DualNILM, a deep multi-task learning framework designed for the dual tasks of appliance state recognition and injected energy identification in NILM. By integrating sequence-to-point and sequence-to-sequence strategies within a Transformer-based architecture, DualNILM can effectively capture multi-scale temporal dependencies in the aggregate power consumption patterns, allowing for accurate appliance state recognition and energy injection identification. We conduct validation of DualNILM using both self-collected and synthesized open NILM datasets that include both appliance-level energy consumption and energy injection. Extensive experimental results demonstrate that DualNILM maintains an excellent performance for the dual tasks in NILM, much outperforming conventional methods.
GraphProp: Training the Graph Foundation Models using Graph Properties
Aug 06, 2025



This work focuses on training graph foundation models (GFMs) that have strong generalization ability in graph-level tasks such as graph classification. Effective GFM training requires capturing information consistent across different domains. We discover that graph structures provide more consistent cross-domain information compared to node features and graph labels. However, traditional GFMs primarily focus on transferring node features from various domains into a unified representation space but often lack structural cross-domain generalization. To address this, we introduce GraphProp, which emphasizes structural generalization. The training process of GraphProp consists of two main phases. First, we train a structural GFM by predicting graph invariants. Since graph invariants are properties of graphs that depend only on the abstract structure, not on particular labellings or drawings of the graph, this structural GFM has a strong ability to capture the abstract structural information and provide discriminative graph representations comparable across diverse domains. In the second phase, we use the representations given by the structural GFM as positional encodings to train a comprehensive GFM. This phase utilizes domain-specific node attributes and graph labels to further improve cross-domain node feature generalization. Our experiments demonstrate that GraphProp significantly outperforms the competitors in supervised learning and few-shot learning, especially in handling graphs without node attributes.
Learnable Kernel Density Estimation for Graphs
May 27, 2025This work proposes a framework LGKDE that learns kernel density estimation for graphs. The key challenge in graph density estimation lies in effectively capturing both structural patterns and semantic variations while maintaining theoretical guarantees. Combining graph kernels and kernel density estimation (KDE) is a standard approach to graph density estimation, but has unsatisfactory performance due to the handcrafted and fixed features of kernels. Our method LGKDE leverages graph neural networks to represent each graph as a discrete distribution and utilizes maximum mean discrepancy to learn the graph metric for multi-scale KDE, where all parameters are learned by maximizing the density of graphs relative to the density of their well-designed perturbed counterparts. The perturbations are conducted on both node features and graph spectra, which helps better characterize the boundary of normal density regions. Theoretically, we establish consistency and convergence guarantees for LGKDE, including bounds on the mean integrated squared error, robustness, and complexity. We validate LGKDE by demonstrating its effectiveness in recovering the underlying density of synthetic graph distributions and applying it to graph anomaly detection across diverse benchmark datasets. Extensive empirical evaluation shows that LGKDE demonstrates superior performance compared to state-of-the-art baselines on most benchmark datasets.
K-means Derived Unsupervised Feature Selection using Improved ADMM
Nov 19, 2024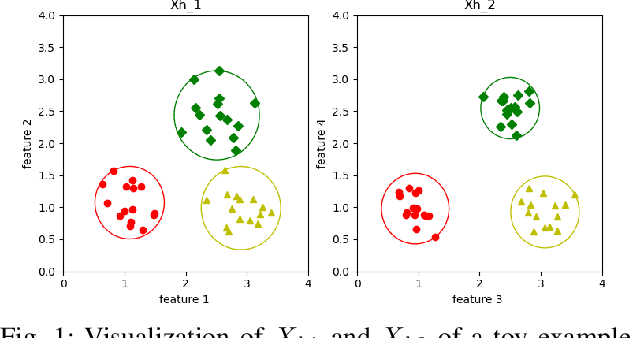
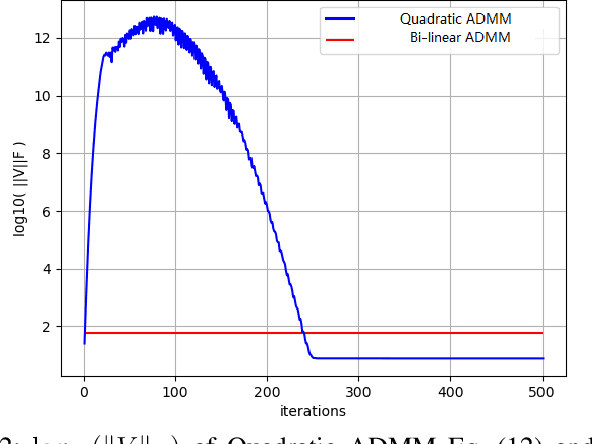

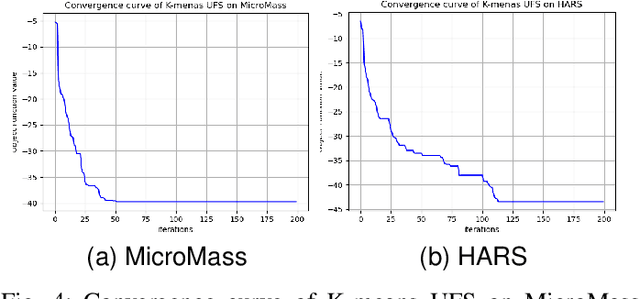
Feature selection is important for high-dimensional data analysis and is non-trivial in unsupervised learning problems such as dimensionality reduction and clustering. The goal of unsupervised feature selection is finding a subset of features such that the data points from different clusters are well separated. This paper presents a novel method called K-means Derived Unsupervised Feature Selection (K-means UFS). Unlike most existing spectral analysis based unsupervised feature selection methods, we select features using the objective of K-means. We develop an alternating direction method of multipliers (ADMM) to solve the NP-hard optimization problem of our K-means UFS model. Extensive experiments on real datasets show that our K-means UFS is more effective than the baselines in selecting features for clustering.
Fuzzy K-Means Clustering without Cluster Centroids
Apr 07, 2024Fuzzy K-Means clustering is a critical technique in unsupervised data analysis. However, the performance of popular Fuzzy K-Means algorithms is sensitive to the selection of initial cluster centroids and is also affected by noise when updating mean cluster centroids. To address these challenges, this paper proposes a novel Fuzzy K-Means clustering algorithm that entirely eliminates the reliance on cluster centroids, obtaining membership matrices solely through distance matrix computation. This innovation enhances flexibility in distance measurement between sample points, thus improving the algorithm's performance and robustness. The paper also establishes theoretical connections between the proposed model and popular Fuzzy K-Means clustering techniques. Experimental results on several real datasets demonstrate the effectiveness of the algorithm.
Weighted Sparse Partial Least Squares for Joint Sample and Feature Selection
Aug 13, 2023

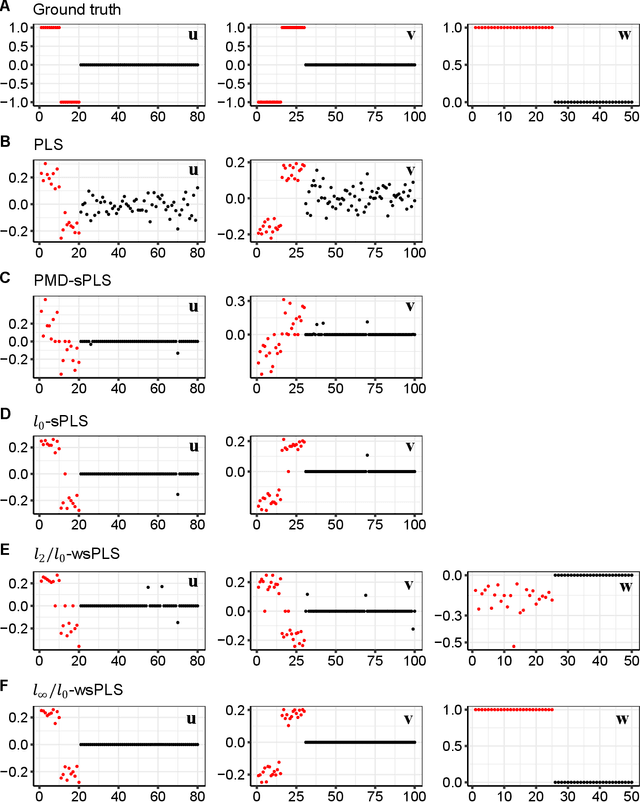
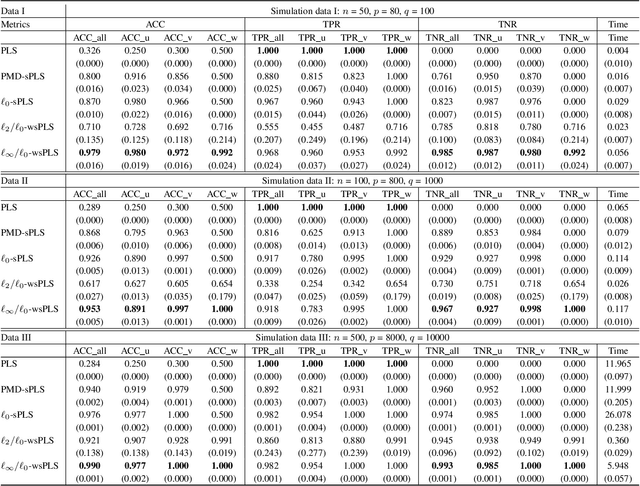
Sparse Partial Least Squares (sPLS) is a common dimensionality reduction technique for data fusion, which projects data samples from two views by seeking linear combinations with a small number of variables with the maximum variance. However, sPLS extracts the combinations between two data sets with all data samples so that it cannot detect latent subsets of samples. To extend the application of sPLS by identifying a specific subset of samples and remove outliers, we propose an $\ell_\infty/\ell_0$-norm constrained weighted sparse PLS ($\ell_\infty/\ell_0$-wsPLS) method for joint sample and feature selection, where the $\ell_\infty/\ell_0$-norm constrains are used to select a subset of samples. We prove that the $\ell_\infty/\ell_0$-norm constrains have the Kurdyka-\L{ojasiewicz}~property so that a globally convergent algorithm is developed to solve it. Moreover, multi-view data with a same set of samples can be available in various real problems. To this end, we extend the $\ell_\infty/\ell_0$-wsPLS model and propose two multi-view wsPLS models for multi-view data fusion. We develop an efficient iterative algorithm for each multi-view wsPLS model and show its convergence property. As well as numerical and biomedical data experiments demonstrate the efficiency of the proposed methods.
X-IQE: eXplainable Image Quality Evaluation for Text-to-Image Generation with Visual Large Language Models
May 26, 2023



This paper introduces a novel explainable image quality evaluation approach called X-IQE, which leverages visual large language models (LLMs) to evaluate text-to-image generation methods by generating textual explanations. X-IQE utilizes a hierarchical Chain of Thought (CoT) to enable MiniGPT-4 to produce self-consistent, unbiased texts that are highly correlated with human evaluation. It offers several advantages, including the ability to distinguish between real and generated images, evaluate text-image alignment, and assess image aesthetics without requiring model training or fine-tuning. X-IQE is more cost-effective and efficient compared to human evaluation, while significantly enhancing the transparency and explainability of deep image quality evaluation models. We validate the effectiveness of our method as a benchmark using images generated by prevalent diffusion models. X-IQE demonstrates similar performance to state-of-the-art (SOTA) evaluation methods on COCO Caption, while overcoming the limitations of previous evaluation models on DrawBench, particularly in handling ambiguous generation prompts and text recognition in generated images. Project website: https://github.com/Schuture/Benchmarking-Awesome-Diffusion-Models
Rethinking Two Consensuses of the Transferability in Deep Learning
Dec 01, 2022Deep transfer learning (DTL) has formed a long-term quest toward enabling deep neural networks (DNNs) to reuse historical experiences as efficiently as humans. This ability is named knowledge transferability. A commonly used paradigm for DTL is firstly learning general knowledge (pre-training) and then reusing (fine-tuning) them for a specific target task. There are two consensuses of transferability of pre-trained DNNs: (1) a larger domain gap between pre-training and downstream data brings lower transferability; (2) the transferability gradually decreases from lower layers (near input) to higher layers (near output). However, these consensuses were basically drawn from the experiments based on natural images, which limits their scope of application. This work aims to study and complement them from a broader perspective by proposing a method to measure the transferability of pre-trained DNN parameters. Our experiments on twelve diverse image classification datasets get similar conclusions to the previous consensuses. More importantly, two new findings are presented, i.e., (1) in addition to the domain gap, a larger data amount and huge dataset diversity of downstream target task also prohibit the transferability; (2) although the lower layers learn basic image features, they are usually not the most transferable layers due to their domain sensitivity.