 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Two Consensuses of the Transferability in Deep Learning
Dec 01, 2022Deep transfer learning (DTL) has formed a long-term quest toward enabling deep neural networks (DNNs) to reuse historical experiences as efficiently as humans. This ability is named knowledge transferability. A commonly used paradigm for DTL is firstly learning general knowledge (pre-training) and then reusing (fine-tuning) them for a specific target task. There are two consensuses of transferability of pre-trained DNNs: (1) a larger domain gap between pre-training and downstream data brings lower transferability; (2) the transferability gradually decreases from lower layers (near input) to higher layers (near output). However, these consensuses were basically drawn from the experiments based on natural images, which limits their scope of application. This work aims to study and complement them from a broader perspective by proposing a method to measure the transferability of pre-trained DNN parameters. Our experiments on twelve diverse image classification datasets get similar conclusions to the previous consensuses. More importantly, two new findings are presented, i.e., (1) in addition to the domain gap, a larger data amount and huge dataset diversity of downstream target task also prohibit the transferability; (2) although the lower layers learn basic image features, they are usually not the most transferable layers due to their domain sensitivity.
MetaLR: Layer-wise Learning Rate based on Meta-Learning for Adaptively Fine-tuning Medical Pre-trained Models
Jun 03, 2022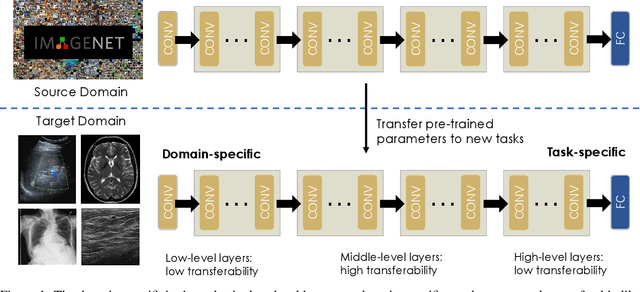

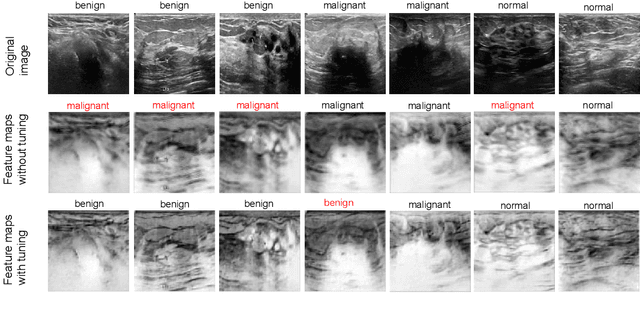
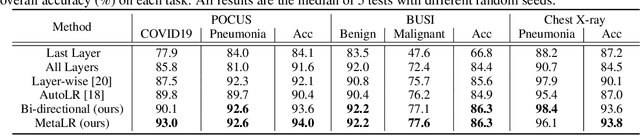
When applying transfer learning for medical image analysis, downstream tasks often have significant gaps with the pre-training tasks. Previous methods mainly focus on improving the transferabilities of the pre-trained models to bridge the gaps. In fact, model fine-tuning can also play a very important role in tackling this problem. A conventional fine-tuning method is updating all deep neural networks (DNNs) layers by a single learning rate (LR), which ignores the unique transferabilities of different layers. In this work, we explore the behaviors of different layers in the fine-tuning stage. More precisely, we first hypothesize that lower-level layers are more domain-specific while higher-level layers are more task-specific, which is verified by a simple bi-directional fine-tuning scheme. It is harder for the pre-trained specific layers to transfer to new tasks than general layers. On this basis, to make different layers better co-adapt to the downstream tasks according to their transferabilities, a meta-learning-based LR learner, namely MetaLR, is proposed to assign LRs for each layer automatically. Extensive experiments on various medical applications (i.e., POCUS, BUSI, Chest X-ray, and LiTS) well confirm our hypothesis and show the superior performance of the proposed methods to previous state-of-the-art fine-tuning methods.