 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-means Derived Unsupervised Feature Selection using Improved ADMM
Paper and Code
Nov 19, 2024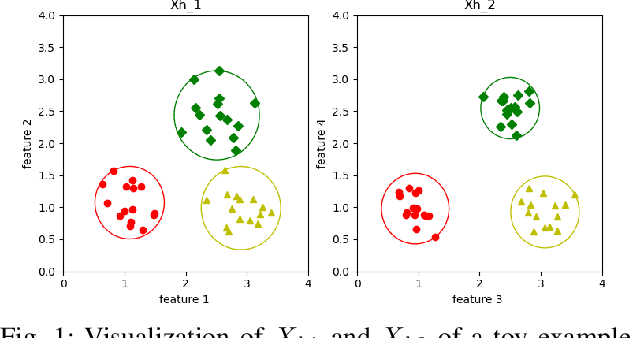
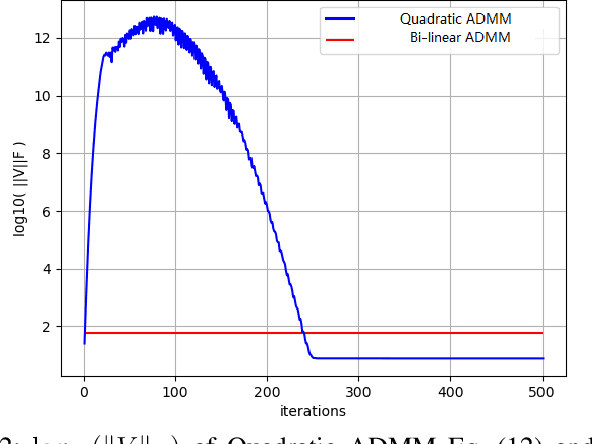

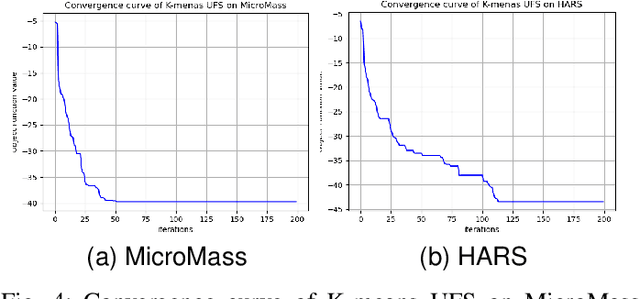
Feature selection is important for high-dimensional data analysis and is non-trivial in unsupervised learning problems such as dimensionality reduction and clustering. The goal of unsupervised feature selection is finding a subset of features such that the data points from different clusters are well separated. This paper presents a novel method called K-means Derived Unsupervised Feature Selection (K-means UFS). Unlike most existing spectral analysis based unsupervised feature selection methods, we select features using the objective of K-means. We develop an alternating direction method of multipliers (ADMM) to solve the NP-hard optimization problem of our K-means UFS model. Extensive experiments on real datasets show that our K-means UFS is more effective than the baselines in selecting features for clustering.