 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Quality: Unlocking Diversity in Ad Headline Generation with Large Language Models
Aug 26, 2025
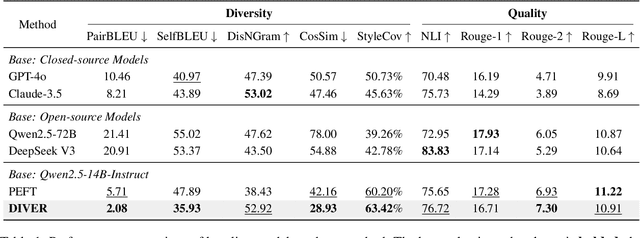
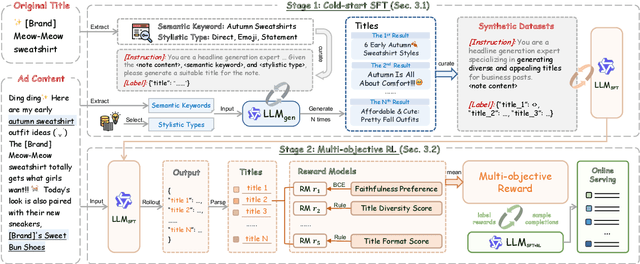
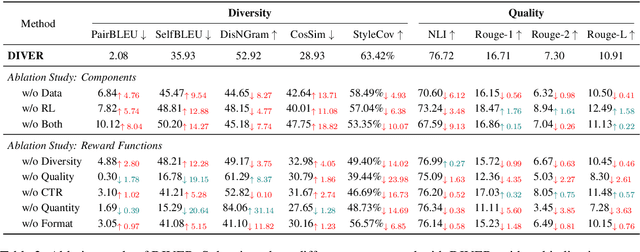
The generation of ad headlines plays a vital role in modern advertising, where both quality and diversity are essential to engage a broad range of audience segments. Current approaches primarily optimize language models for headline quality or click-through rates (CTR), often overlooking the need for diversity and resulting in homogeneous outputs. To address this limitation, we propose DIVER, a novel framework based on large language models (LLMs) that are jointly optimized for both diversity and quality. We first design a semantic- and stylistic-aware data generation pipeline that automatically produces high-quality training pairs with ad content and multiple diverse headlines. To achieve the goal of generating high-quality and diversified ad headlines within a single forward pass, we propose a multi-stage multi-objective optimization framework with supervised fine-tuning (SFT) and reinforcement learning (RL). Experiments on real-world industrial datasets demonstrate that DIVER effectively balances quality and diversity. Deployed on a large-scale content-sharing platform serving hundreds of millions of users, our framework improves advertiser value (ADVV) and CTR by 4.0% and 1.4%.
Towards Large-scale Generative Ranking
May 08, 2025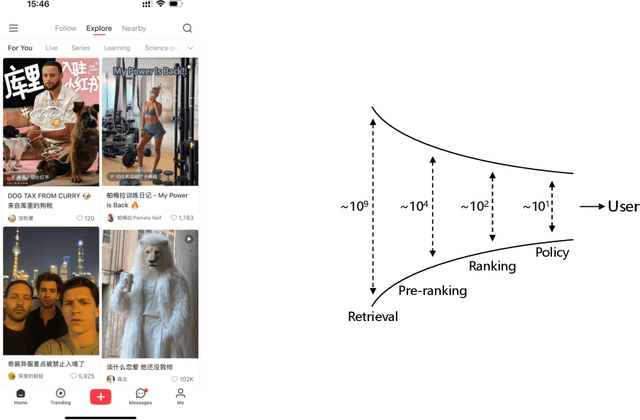
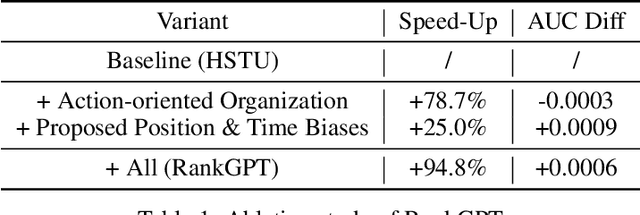
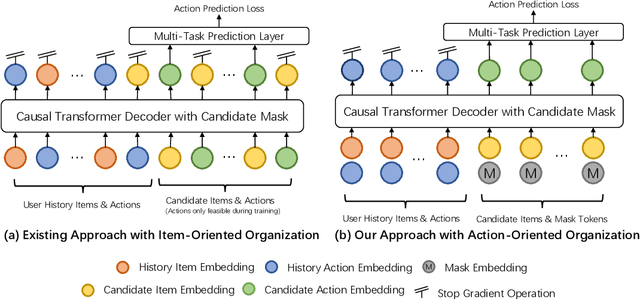

Generative recommendation has recently emerged as a promising paradigm in information retrieval. However, generative ranking systems are still understudied, particularly with respect to their effectiveness and feasibility in large-scale industrial settings. This paper investigates this topic at the ranking stage of Xiaohongshu's Explore Feed, a recommender system that serves hundreds of millions of users. Specifically, we first examine how generative ranking outperforms current industrial recommenders. Through theoretical and empirical analyses, we find that the primary improvement in effectiveness stems from the generative architecture, rather than the training paradigm. To facilitate efficient deployment of generative ranking, we introduce GenRank, a novel generative architecture for ranking. We validate the effectiveness and efficiency of our solution through online A/B experiments. The results show that GenRank achieves significant improvements in user satisfaction with nearly equivalent computational resources compared to the existing production system.
Code-Driven Inductive Synthesis: Enhancing Reasoning Abilities of Large Language Models with Sequences
Mar 17, 2025
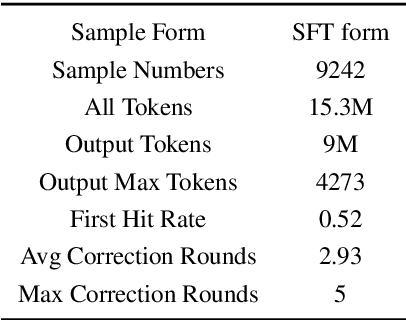
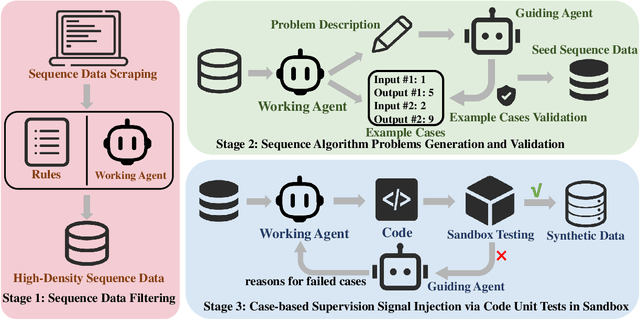

Large language models make remarkable progress in reasoning capabilities. Existing works focus mainly on deductive reasoning tasks (e.g., code and math), while another type of reasoning mode that better aligns with human learning, inductive reasoning, is not well studied. We attribute the reason to the fact that obtaining high-quality process supervision data is challenging for inductive reasoning. Towards this end, we novelly employ number sequences as the source of inductive reasoning data. We package sequences into algorithmic problems to find the general term of each sequence through a code solution. In this way, we can verify whether the code solution holds for any term in the current sequence, and inject case-based supervision signals by using code unit tests. We build a sequence synthetic data pipeline and form a training dataset CodeSeq. Experimental results show that the models tuned with CodeSeq improve on both code and comprehensive reasoning benchmarks.
LLaVA-RadZ: Can Multimodal Large Language Models Effectively Tackle Zero-shot Radiology Recognition?
Mar 10, 2025Recently, multimodal large models (MLLMs) have demonstrated exceptional capabilities in visual understanding and reasoning across various vision-language tasks. However, MLLMs usually perform poorly in zero-shot medical disease recognition, as they do not fully exploit the captured features and available medical knowledge. To address this challenge, we propose LLaVA-RadZ, a simple yet effective framework for zero-shot medical disease recognition. Specifically, we design an end-to-end training strategy, termed Decoding-Side Feature Alignment Training (DFAT) to take advantage of the characteristics of the MLLM decoder architecture and incorporate modality-specific tokens tailored for different modalities, which effectively utilizes image and text representations and facilitates robust cross-modal alignment. Additionally, we introduce a Domain Knowledge Anchoring Module (DKAM) to exploit the intrinsic medical knowledge of large models, which mitigates the category semantic gap in image-text alignment. DKAM improves category-level alignment, allowing for accurate disease recognition. Extensive experiments on multiple benchmarks demonstrate that our LLaVA-RadZ significantly outperforms traditional MLLMs in zero-shot disease recognition and exhibits the state-of-the-art performance compared to the well-established and highly-optimized CLIP-based approaches.
Exploring Mathematical Extrapolation of Large Language Models with Synthetic Data
Jun 04, 2024



Large Language Models (LLMs) have shown excellent performance in language understanding, text generation, code synthesis, and many other tasks, while they still struggle in complex multi-step reasoning problems, such as mathematical reasoning. In this paper, through a newly proposed arithmetical puzzle problem, we show that the model can perform well on multi-step reasoning tasks via fine-tuning on high-quality synthetic data. Experimental results with the open-llama-3B model on three different test datasets show that not only the model can reach a zero-shot pass@1 at 0.44 on the in-domain dataset, it also demonstrates certain generalization capabilities on the out-of-domain datasets. Specifically, this paper has designed two out-of-domain datasets in the form of extending the numerical range and the composing components of the arithmetical puzzle problem separately. The fine-tuned models have shown encouraging performance on these two far more difficult tasks with the zero-shot pass@1 at 0.33 and 0.35, respectively.
Progressive Multi-stage Interactive Training in Mobile Network for Fine-grained Recognition
Dec 08, 2021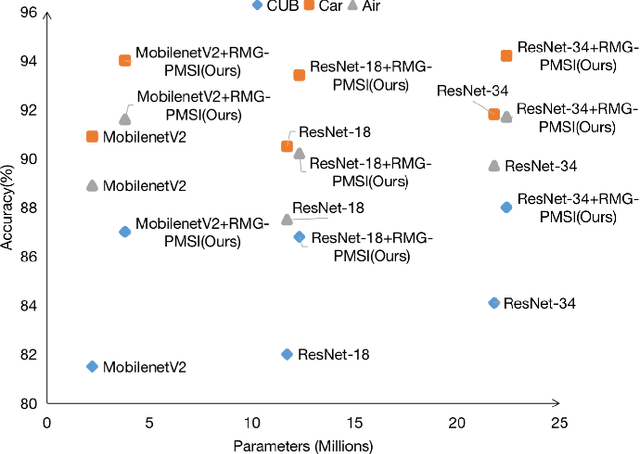
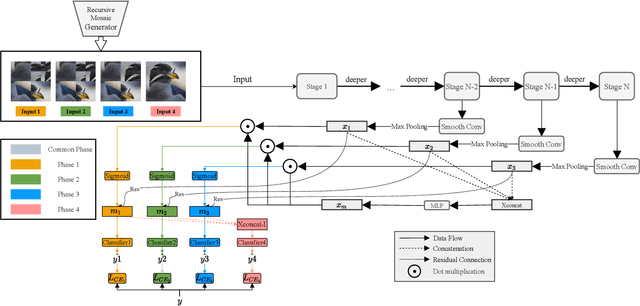
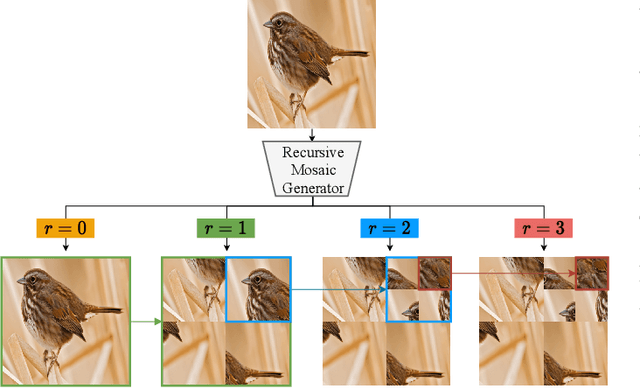

Fine-grained Visual Classification (FGVC) aims to identify objects from subcategories. It is a very challenging task because of the subtle inter-class differences. Existing research applies large-scale convolutional neural networks or visual transformers as the feature extractor, which is extremely computationally expensive. In fact, real-world scenarios of fine-grained recognition often require a more lightweight mobile network that can be utilized offline. However, the fundamental mobile network feature extraction capability is weaker than large-scale models. In this paper, based on the lightweight MobilenetV2, we propose a Progressive Multi-Stage Interactive training method with a Recursive Mosaic Generator (RMG-PMSI). First, we propose a Recursive Mosaic Generator (RMG) that generates images with different granularities in different phases. Then, the features of different stages pass through a Multi-Stage Interaction (MSI) module, which strengthens and complements the corresponding features of different stages. Finally, using the progressive training (P), the features extracted by the model in different stages can be fully utilized and fused with each other. Experiments on three prestigious fine-grained benchmarks show that RMG-PMSI can significantly improve the performance with good robustness and transferability.
Towards Class-Specific Unit
Nov 22, 2020
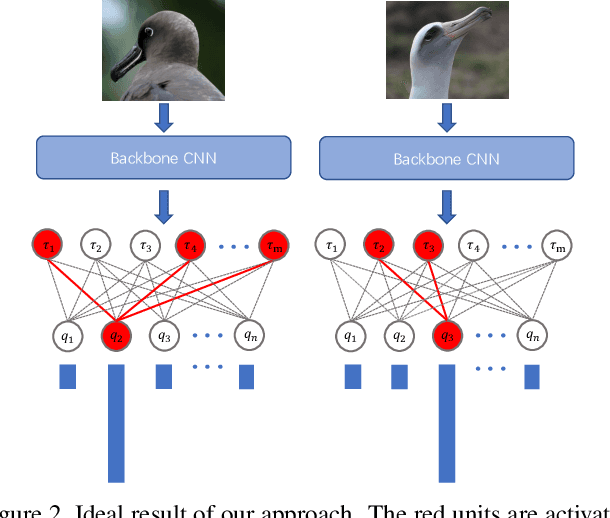

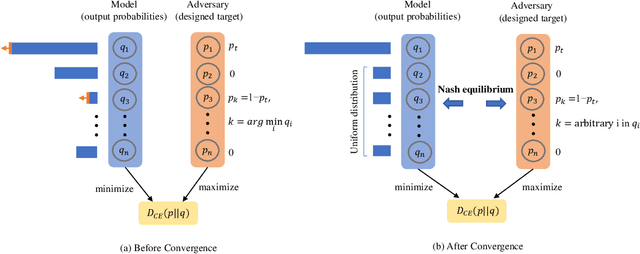
Class selectivity is an attribute of a unit in deep neural networks, which characterizes the discriminative ability of units to a specific class. Intuitively, decisions made by several highly selective units are more interpretable since it is easier to be traced back to the origin while that made by complex combinations of lowly selective units are more difficult to interpret. In this work, we develop a novel way to directly train highly selective units, through which we are able to examine the performance of a network that only rely on highly selective units. Specifically, we train the network such that all the units in the penultimate layer only response to one specific class, which we named as class-specific unit. By innovatively formulating the problem using mutual information, we find that in such a case, the output of the model has a special form that all the probabilities over non-target classes are uniformly distributed. We then propose a minimax loss based on a game theoretic framework to achieve the goal. Nash equilibria are proved to exist and the outcome is consistent with our regularization objective. Experimental results show that the model trained with the proposed objective outperforms models trained with baseline objective among all the tasks we test. Our results shed light on the role of class-specific units by indicating that they can be directly used for decisions without relying on low selective units.