 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Collaboration of Multi-Language Models based on Minimal Complete Semantic Units
Aug 26, 2025This paper investigates the enhancement of reasoning capabilities in language models through token-level multi-model collaboration. Our approach selects the optimal tokens from the next token distributions provided by multiple models to perform autoregressive reasoning. Contrary to the assumption that more models yield better results, we introduce a distribution distance-based dynamic selection strategy (DDS) to optimize the multi-model collaboration process. To address the critical challenge of vocabulary misalignment in multi-model collaboration, we propose the concept of minimal complete semantic units (MCSU), which is simple yet enables multiple language models to achieve natural alignment within the linguistic space. Experimental results across various benchmarks demonstrate the superiority of our method. The code will be available at https://github.com/Fanye12/DDS.
Beyond Quality: Unlocking Diversity in Ad Headline Generation with Large Language Models
Aug 26, 2025
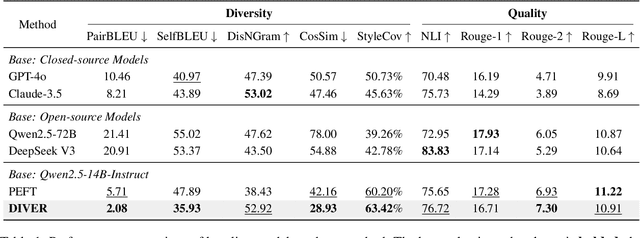
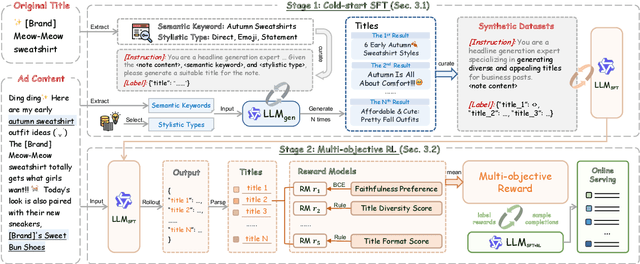
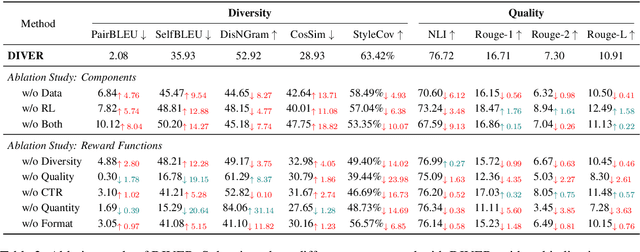
The generation of ad headlines plays a vital role in modern advertising, where both quality and diversity are essential to engage a broad range of audience segments. Current approaches primarily optimize language models for headline quality or click-through rates (CTR), often overlooking the need for diversity and resulting in homogeneous outputs. To address this limitation, we propose DIVER, a novel framework based on large language models (LLMs) that are jointly optimized for both diversity and quality. We first design a semantic- and stylistic-aware data generation pipeline that automatically produces high-quality training pairs with ad content and multiple diverse headlines. To achieve the goal of generating high-quality and diversified ad headlines within a single forward pass, we propose a multi-stage multi-objective optimization framework with supervised fine-tuning (SFT) and reinforcement learning (RL). Experiments on real-world industrial datasets demonstrate that DIVER effectively balances quality and diversity. Deployed on a large-scale content-sharing platform serving hundreds of millions of users, our framework improves advertiser value (ADVV) and CTR by 4.0% and 1.4%.
A Metric for MLLM Alignment in Large-scale Recommendation
Aug 07, 2025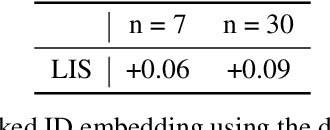
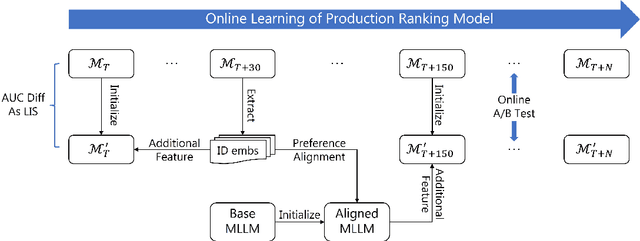


Multimodal recommendation has emerged as a critical technique in modern recommender systems, leveraging content representations from advanced multimodal large language models (MLLMs). To ensure these representations are well-adapted, alignment with the recommender system is essential. However, evaluating the alignment of MLLMs for recommendation presents significant challenges due to three key issues: (1) static benchmarks are inaccurate because of the dynamism in real-world applications, (2) evaluations with online system, while accurate, are prohibitively expensive at scale, and (3) conventional metrics fail to provide actionable insights when learned representations underperform. To address these challenges, we propose the Leakage Impact Score (LIS), a novel metric for multimodal recommendation. Rather than directly assessing MLLMs, LIS efficiently measures the upper bound of preference data. We also share practical insights on deploying MLLMs with LIS in real-world scenarios. Online A/B tests on both Content Feed and Display Ads of Xiaohongshu's Explore Feed production demonstrate the effectiveness of our proposed method, showing significant improvements in user spent time and advertiser value.
CineTechBench: A Benchmark for Cinematographic Technique Understanding and Generation
May 21, 2025



Cinematography is a cornerstone of film production and appreciation, shaping mood, emotion, and narrative through visual elements such as camera movement, shot composition, and lighting. Despite recent progress in multimodal large language models (MLLMs) and video generation models, the capacity of current models to grasp and reproduce cinematographic techniques remains largely uncharted, hindered by the scarcity of expert-annotated data. To bridge this gap, we present CineTechBench, a pioneering benchmark founded on precise, manual annotation by seasoned cinematography experts across key cinematography dimensions. Our benchmark covers seven essential aspects-shot scale, shot angle, composition, camera movement, lighting, color, and focal length-and includes over 600 annotated movie images and 120 movie clips with clear cinematographic techniques. For the understanding task, we design question answer pairs and annotated descriptions to assess MLLMs' ability to interpret and explain cinematographic techniques. For the generation task, we assess advanced video generation models on their capacity to reconstruct cinema-quality camera movements given conditions such as textual prompts or keyframes. We conduct a large-scale evaluation on 15+ MLLMs and 5+ video generation models. Our results offer insights into the limitations of current models and future directions for cinematography understanding and generation in automatically film production and appreciation. The code and benchmark can be accessed at https://github.com/PRIS-CV/CineTechBench.
Towards Large-scale Generative Ranking
May 08, 2025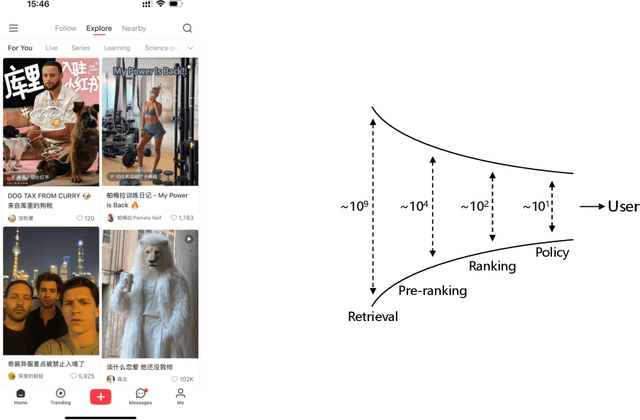
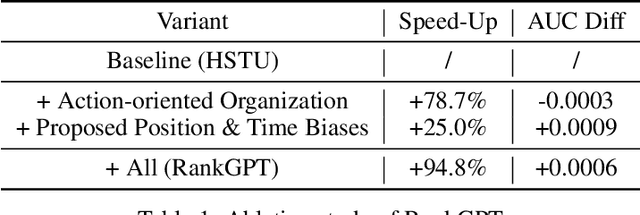
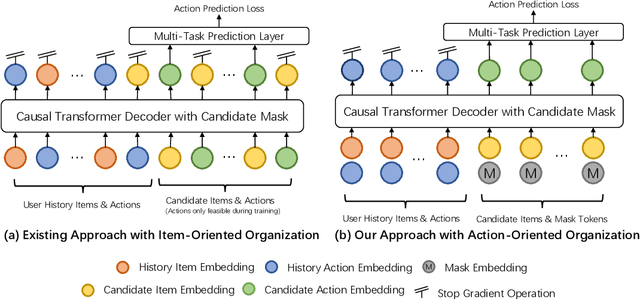

Generative recommendation has recently emerged as a promising paradigm in information retrieval. However, generative ranking systems are still understudied, particularly with respect to their effectiveness and feasibility in large-scale industrial settings. This paper investigates this topic at the ranking stage of Xiaohongshu's Explore Feed, a recommender system that serves hundreds of millions of users. Specifically, we first examine how generative ranking outperforms current industrial recommenders. Through theoretical and empirical analyses, we find that the primary improvement in effectiveness stems from the generative architecture, rather than the training paradigm. To facilitate efficient deployment of generative ranking, we introduce GenRank, a novel generative architecture for ranking. We validate the effectiveness and efficiency of our solution through online A/B experiments. The results show that GenRank achieves significant improvements in user satisfaction with nearly equivalent computational resources compared to the existing production system.
Harmonized Speculative Sampling
Aug 28, 2024

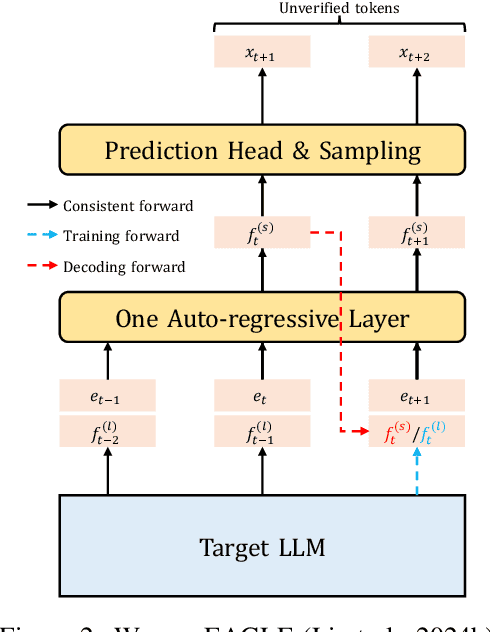

Speculative sampling has proven to be an effective solution to accelerate decoding from large language models, where the acceptance rate significantly determines the performance. Most previous works on improving the acceptance rate focus on aligned training and efficient decoding, implicitly paying less attention to the linkage of training and decoding. In this work, we first investigate the linkage of training and decoding for speculative sampling and then propose a solution named HArmonized Speculative Sampling (HASS). HASS improves the acceptance rate without extra inference overhead by harmonizing training and decoding on their objectives and contexts. Experiments on three LLaMA models demonstrate that HASS achieves 2.81x-3.65x wall-clock time speedup ratio averaging across three datasets, which is 8%-15% faster than EAGLE-2.
An Aligning and Training Framework for Multimodal Recommendations
Mar 20, 2024



With the development of multimedia applications, multimodal recommendations are playing an essential role, as they can leverage rich contexts beyond user interactions. Existing methods mainly regard multimodal information as an auxiliary, using them to help learn ID features; however, there exist semantic gaps among multimodal content features and ID features, for which directly using multimodal information as an auxiliary would lead to misalignment in representations of users and items. In this paper, we first systematically investigate the misalignment issue in multimodal recommendations, and propose a solution named AlignRec. In AlignRec, the recommendation objective is decomposed into three alignments, namely alignment within contents, alignment between content and categorical ID, and alignment between users and items. Each alignment is characterized by a specific objective function and is integrated into our multimodal recommendation framework. To effectively train our AlignRec, we propose starting from pre-training the first alignment to obtain unified multimodal features and subsequently training the following two alignments together with these features as input. As it is essential to analyze whether each multimodal feature helps in training, we design three new classes of metrics to evaluate intermediate performance. Our extensive experiments on three real-world datasets consistently verify the superiority of AlignRec compared to nine baselines. We also find that the multimodal features generated by AlignRec are better than currently used ones, which are to be open-sourced.
Sliding Spectrum Decomposition for Diversified Recommendation
Jul 12, 2021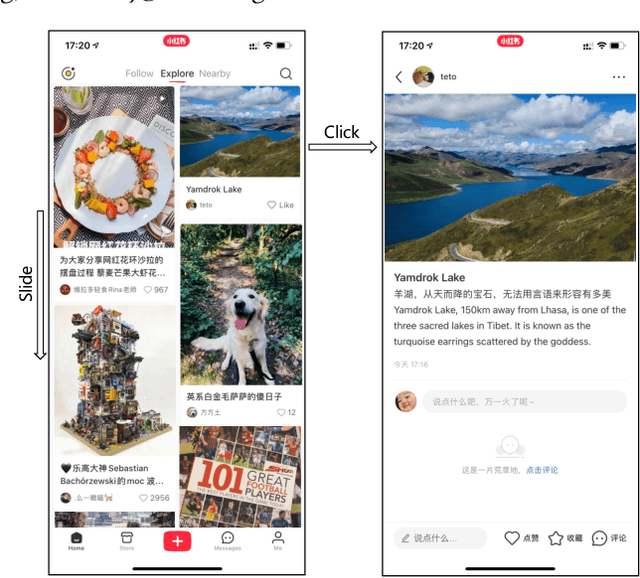



Content feed, a type of product that recommends a sequence of items for users to browse and engage with, has gained tremendous popularity among social media platforms. In this paper, we propose to study the diversity problem in such a scenario from an item sequence perspective using time series analysis techniques. We derive a method called sliding spectrum decomposition (SSD) that captures users' perception of diversity in browsing a long item sequence. We also share our experiences in designing and implementing a suitable item embedding method for accurate similarity measurement under long tail effect. Combined together, they are now fully implemented and deployed in Xiaohongshu App's production recommender system that serves the main Explore Feed product for tens of millions of users every day. We demonstrate the effectiveness and efficiency of the method through theoretical analysis, offline experiments and online A/B tests.
RLzoo: A Comprehensive and Adaptive Reinforcement Learning Library
Sep 18, 2020
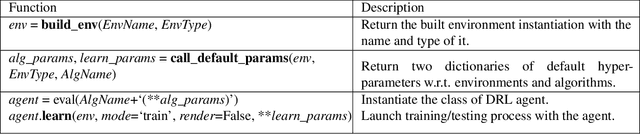
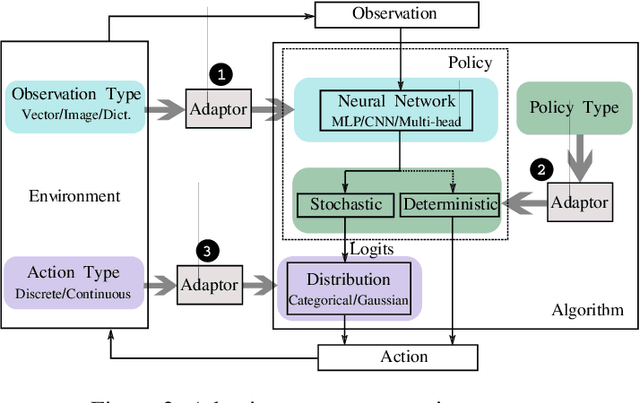
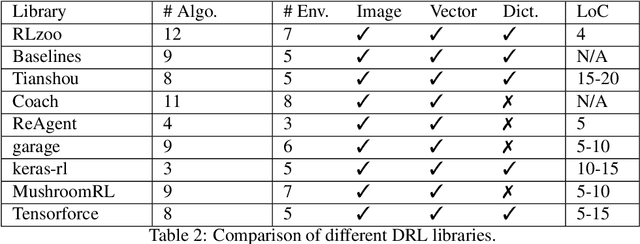
Recently, we have seen a rapidly growing adoption of Deep Reinforcement Learning (DRL) technologies. Fully achieving the promise of these technologies in practice is, however, extremely difficult. Users have to invest tremendous efforts in building DRL agents, incorporating the agents into various external training environments, and tuning agent implementation/hyper-parameters so that they can reproduce state-of-the-art (SOTA) performance. In this paper, we propose RLzoo, a new DRL library that aims to make it easy to develop and reproduce DRL algorithms. RLzoo has both high-level APIs and low-level APIs, useful for constructing and customising DRL agents, respectively. It has an adaptive agent construction algorithm that can automatically integrate custom RLzoo agents into various external training environments. To help reproduce the results of SOTA algorithms, RLzoo provides rich reference DRL algorithm implementations and effective hyper-parameter settings. Extensive evaluation results show that RLzoo not only outperforms existing DRL libraries in its simplicity of API design; but also provides the largest number of reference DRL algorithm implementations.