 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLzoo: A Comprehensive and Adaptive Reinforcement Learning Library
Sep 18, 2020
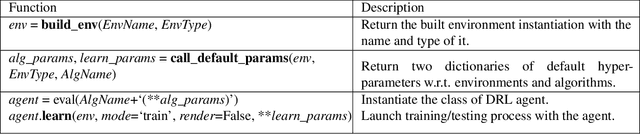
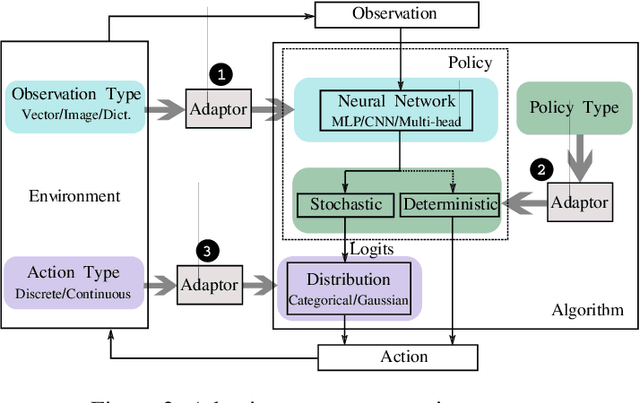
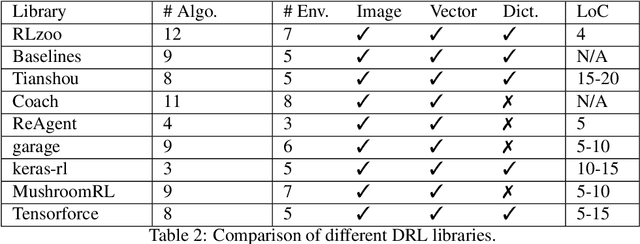
Recently, we have seen a rapidly growing adoption of Deep Reinforcement Learning (DRL) technologies. Fully achieving the promise of these technologies in practice is, however, extremely difficult. Users have to invest tremendous efforts in building DRL agents, incorporating the agents into various external training environments, and tuning agent implementation/hyper-parameters so that they can reproduce state-of-the-art (SOTA) performance. In this paper, we propose RLzoo, a new DRL library that aims to make it easy to develop and reproduce DRL algorithms. RLzoo has both high-level APIs and low-level APIs, useful for constructing and customising DRL agents, respectively. It has an adaptive agent construction algorithm that can automatically integrate custom RLzoo agents into various external training environments. To help reproduce the results of SOTA algorithms, RLzoo provides rich reference DRL algorithm implementations and effective hyper-parameter settings. Extensive evaluation results show that RLzoo not only outperforms existing DRL libraries in its simplicity of API design; but also provides the largest number of reference DRL algorithm implementations.
Iterative Update and Unified Representation for Multi-Agent Reinforcement Learning
Aug 16, 2019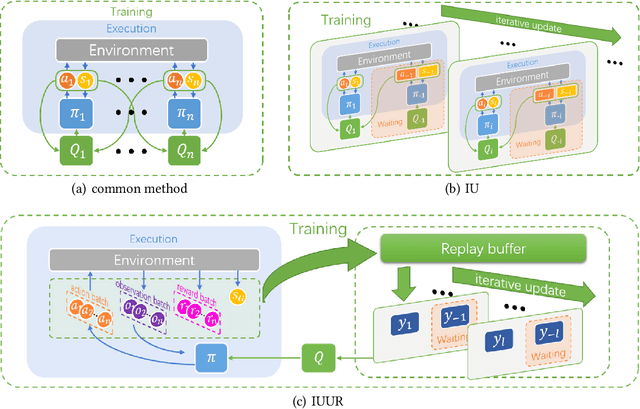
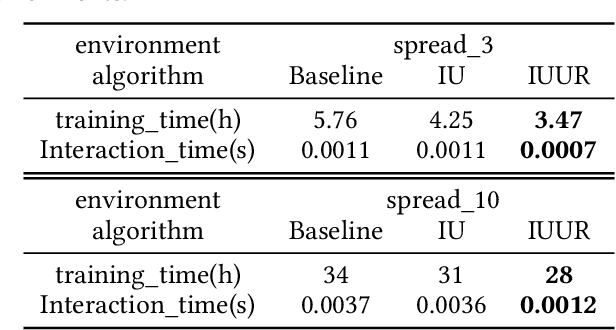

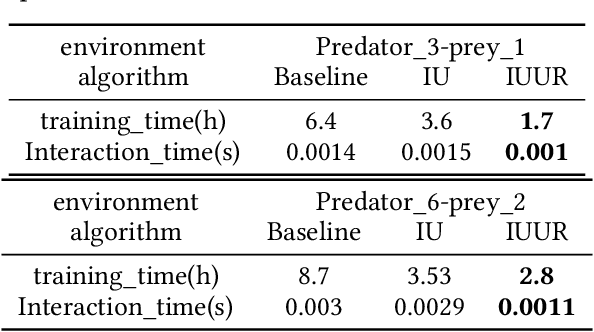
Multi-agent systems have a wide range of applications in cooperative and competitive tasks. As the number of agents increases, nonstationarity gets more serious in multi-agent reinforcement learning (MARL), which brings great difficulties to the learning process. Besides, current mainstream algorithms configure each agent an independent network,so that the memory usage increases linearly with the number of agents which greatly slows down the interaction with the environment. Inspired by Generative Adversarial Networks (GAN), this paper proposes an iterative update method (IU) to stabilize the nonstationary environment. Further, we add first-person perspective and represent all agents by only one network which can change agents' policies from sequential compute to batch compute. Similar to continual lifelong learning, we realize the iterative update method in this unified representative network (IUUR). In this method, iterative update can greatly alleviate the nonstationarity of the environment, unified representation can speed up the interaction with environment and avoid the linear growth of memory usage. Besides, this method does not bother decentralized execution and distributed deployment. Experiments show that compared with MADDPG, our algorithm achieves state-of-the-art performance and saves wall-clock time by a large margin especially with more agents.