 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Update and Unified Representation for Multi-Agent Reinforcement Learning
Paper and Code
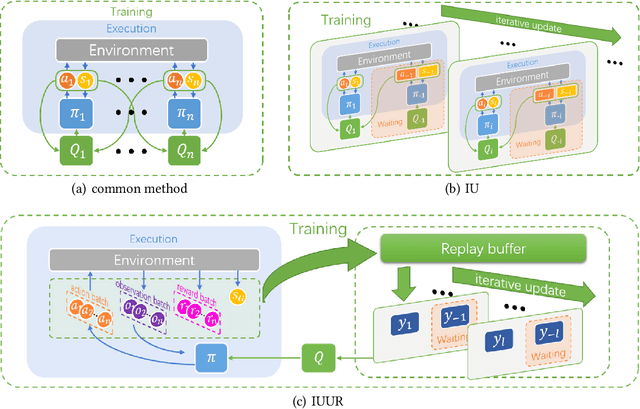
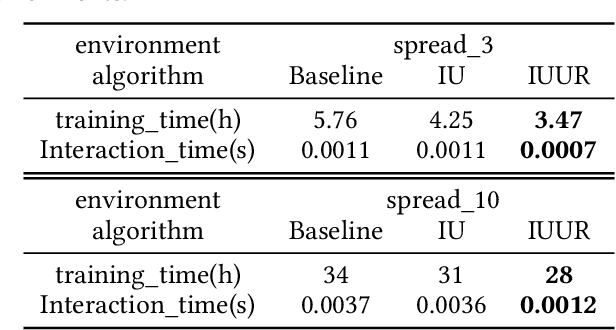

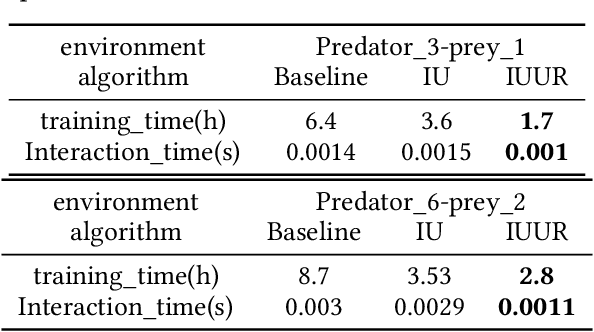
Multi-agent systems have a wide range of applications in cooperative and competitive tasks. As the number of agents increases, nonstationarity gets more serious in multi-agent reinforcement learning (MARL), which brings great difficulties to the learning process. Besides, current mainstream algorithms configure each agent an independent network,so that the memory usage increases linearly with the number of agents which greatly slows down the interaction with the environment. Inspired by Generative Adversarial Networks (GAN), this paper proposes an iterative update method (IU) to stabilize the nonstationary environment. Further, we add first-person perspective and represent all agents by only one network which can change agents' policies from sequential compute to batch compute. Similar to continual lifelong learning, we realize the iterative update method in this unified representative network (IUUR). In this method, iterative update can greatly alleviate the nonstationarity of the environment, unified representation can speed up the interaction with environment and avoid the linear growth of memory usage. Besides, this method does not bother decentralized execution and distributed deployment. Experiments show that compared with MADDPG, our algorithm achieves state-of-the-art performance and saves wall-clock time by a large margin especially with more agents.