 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Unrolling in Omni Models
Apr 23, 2026We present Omni, a unified multimodal model natively trained on diverse modalities, including text, images, videos, 3D geometry, and hidden representations. We find that such training enables Context Unrolling, where the model explicitly reasons across multiple modal representations before producing predictions. This process enables the model to aggregate complementary information across heterogeneous modalities, facilitating a more faithful approximation of the shared multimodal knowledge manifold and improving downstream reasoning fidelity. As a result, Omni achieves strong performance on both multimodal generation and understanding benchmarks, while demonstrating advanced multimodal reasoning capabilities, including in-context generation of text, image, video, and 3D geometry.
From Instruction to Event: Sound-Triggered Mobile Manipulation
Jan 29, 2026Current mobile manipulation research predominantly follows an instruction-driven paradigm, where agents rely on predefined textual commands to execute tasks. However, this setting confines agents to a passive role, limiting their autonomy and ability to react to dynamic environmental events. To address these limitations, we introduce sound-triggered mobile manipulation, where agents must actively perceive and interact with sound-emitting objects without explicit action instructions. To support these tasks, we develop Habitat-Echo, a data platform that integrates acoustic rendering with physical interaction. We further propose a baseline comprising a high-level task planner and low-level policy models to complete these tasks. Extensive experiments show that the proposed baseline empowers agents to actively detect and respond to auditory events, eliminating the need for case-by-case instructions. Notably, in the challenging dual-source scenario, the agent successfully isolates the primary source from overlapping acoustic interference to execute the first interaction, and subsequently proceeds to manipulate the secondary object, verifying the robustness of the baseline.
Recurrent Autoregressive Diffusion: Global Memory Meets Local Attention
Nov 17, 2025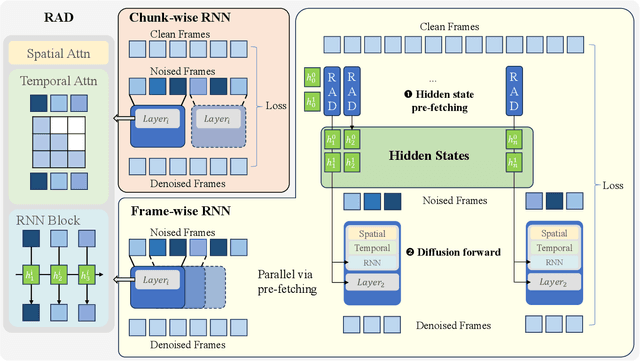
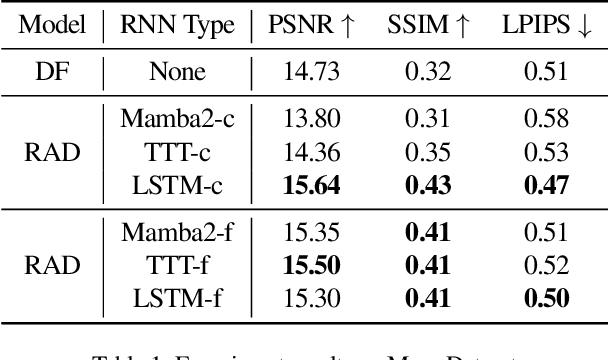
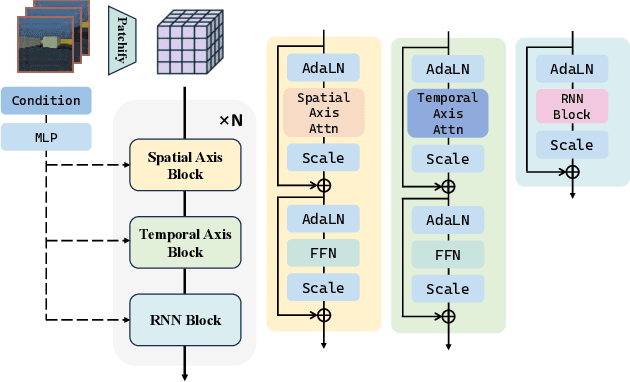
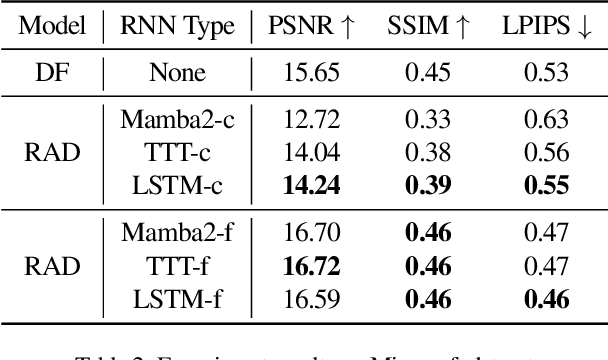
Recent advancements in video generation have demonstrated the potential of using video diffusion models as world models, with autoregressive generation of infinitely long videos through masked conditioning. However, such models, usually with local full attention, lack effective memory compression and retrieval for long-term generation beyond the window size, leading to issues of forgetting and spatiotemporal inconsistencies. To enhance the retention of historical information within a fixed memory budget, we introduce a recurrent neural network (RNN) into the diffusion transformer framework. Specifically, a diffusion model incorporating LSTM with attention achieves comparable performance to state-of-the-art RNN blocks, such as TTT and Mamba2. Moreover, existing diffusion-RNN approaches often suffer from performance degradation due to training-inference gap or the lack of overlap across windows. To address these limitations, we propose a novel Recurrent Autoregressive Diffusion (RAD) framework, which executes frame-wise autoregression for memory update and retrieval, consistently across training and inference time. Experiments on Memory Maze and Minecraft datasets demonstrate the superiority of RAD for long video generation, highlighting the efficiency of LSTM in sequence modeling.
Single-stream Policy Optimization
Sep 16, 2025
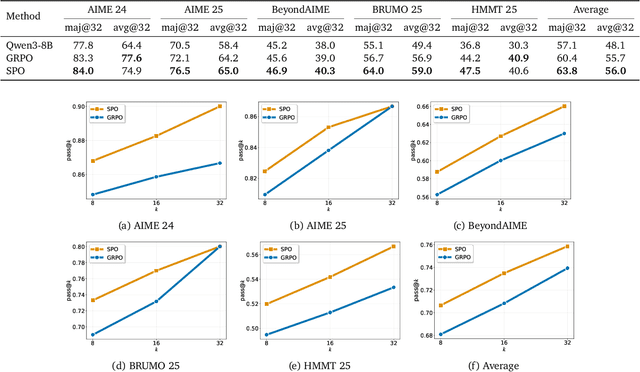

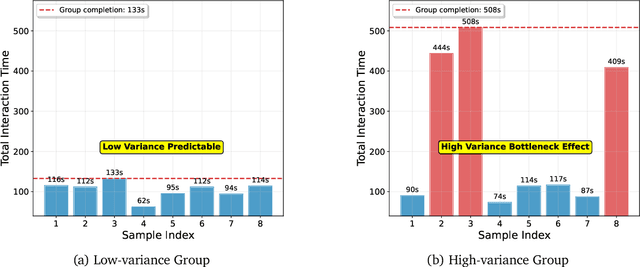
We revisit policy-gradient optimization for Large Language Models (LLMs) from a single-stream perspective. Prevailing group-based methods like GRPO reduce variance with on-the-fly baselines but suffer from critical flaws: frequent degenerate groups erase learning signals, and synchronization barriers hinder scalability. We introduce Single-stream Policy Optimization (SPO), which eliminates these issues by design. SPO replaces per-group baselines with a persistent, KL-adaptive value tracker and normalizes advantages globally across the batch, providing a stable, low-variance learning signal for every sample. Being group-free, SPO enables higher throughput and scales effectively in long-horizon or tool-integrated settings where generation times vary. Furthermore, the persistent value tracker naturally enables an adaptive curriculum via prioritized sampling. Experiments using Qwen3-8B show that SPO converges more smoothly and attains higher accuracy than GRPO, while eliminating computation wasted on degenerate groups. Ablation studies confirm that SPO's gains stem from its principled approach to baseline estimation and advantage normalization, offering a more robust and efficient path for LLM reasoning. Across five hard math benchmarks with Qwen3 8B, SPO improves the average maj@32 by +3.4 percentage points (pp) over GRPO, driven by substantial absolute point gains on challenging datasets, including +7.3 pp on BRUMO 25, +4.4 pp on AIME 25, +3.3 pp on HMMT 25, and achieves consistent relative gain in pass@$k$ across the evaluated $k$ values. SPO's success challenges the prevailing trend of adding incidental complexity to RL algorithms, highlighting a path where fundamental principles, not architectural workarounds, drive the next wave of progress in LLM reasoning.
ClutterDexGrasp: A Sim-to-Real System for General Dexterous Grasping in Cluttered Scenes
Jun 17, 2025



Dexterous grasping in cluttered scenes presents significant challenges due to diverse object geometries, occlusions, and potential collisions. Existing methods primarily focus on single-object grasping or grasp-pose prediction without interaction, which are insufficient for complex, cluttered scenes. Recent vision-language-action models offer a potential solution but require extensive real-world demonstrations, making them costly and difficult to scale. To address these limitations, we revisit the sim-to-real transfer pipeline and develop key techniques that enable zero-shot deployment in reality while maintaining robust generalization. We propose ClutterDexGrasp, a two-stage teacher-student framework for closed-loop target-oriented dexterous grasping in cluttered scenes. The framework features a teacher policy trained in simulation using clutter density curriculum learning, incorporating both a novel geometry and spatially-embedded scene representation and a comprehensive safety curriculum, enabling general, dynamic, and safe grasping behaviors. Through imitation learning, we distill the teacher's knowledge into a student 3D diffusion policy (DP3) that operates on partial point cloud observations. To the best of our knowledge, this represents the first zero-shot sim-to-real closed-loop system for target-oriented dexterous grasping in cluttered scenes, demonstrating robust performance across diverse objects and layouts. More details and videos are available at https://clutterdexgrasp.github.io/.
Learning World Models for Interactive Video Generation
May 28, 2025Foundational world models must be both interactive and preserve spatiotemporal coherence for effective future planning with action choices. However, present models for long video generation have limited inherent world modeling capabilities due to two main challenges: compounding errors and insufficient memory mechanisms. We enhance image-to-video models with interactive capabilities through additional action conditioning and autoregressive framework, and reveal that compounding error is inherently irreducible in autoregressive video generation, while insufficient memory mechanism leads to incoherence of world models. We propose video retrieval augmented generation (VRAG) with explicit global state conditioning, which significantly reduces long-term compounding errors and increases spatiotemporal consistency of world models. In contrast, naive autoregressive generation with extended context windows and retrieval-augmented generation prove less effective for video generation, primarily due to the limited in-context learning capabilities of current video models. Our work illuminates the fundamental challenges in video world models and establishes a comprehensive benchmark for improving video generation models with internal world modeling capabilities.
Variable-Friction In-Hand Manipulation for Arbitrary Objects via Diffusion-Based Imitation Learning
Mar 04, 2025



Dexterous in-hand manipulation (IHM) for arbitrary objects is challenging due to the rich and subtle contact process. Variable-friction manipulation is an alternative approach to dexterity, previously demonstrating robust and versatile 2D IHM capabilities with only two single-joint fingers. However, the hard-coded manipulation methods for variable friction hands are restricted to regular polygon objects and limited target poses, as well as requiring the policy to be tailored for each object. This paper proposes an end-to-end learning-based manipulation method to achieve arbitrary object manipulation for any target pose on real hardware, with minimal engineering efforts and data collection. The method features a diffusion policy-based imitation learning method with co-training from simulation and a small amount of real-world data. With the proposed framework, arbitrary objects including polygons and non-polygons can be precisely manipulated to reach arbitrary goal poses within 2 hours of training on an A100 GPU and only 1 hour of real-world data collection. The precision is higher than previous customized object-specific policies, achieving an average success rate of 71.3% with average pose error being 2.676 mm and 1.902 degrees.
Generative Diffusion Modeling: A Practical Handbook
Dec 22, 2024
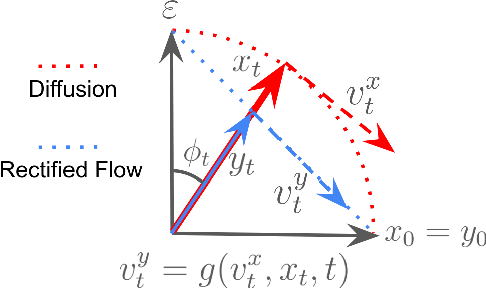
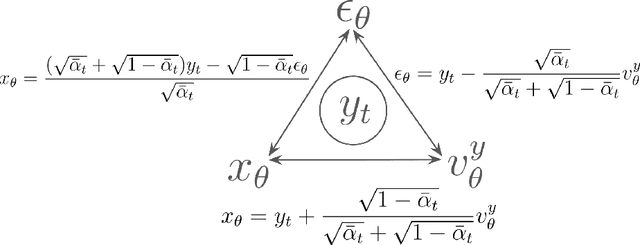

This handbook offers a unified perspective on diffusion models, encompassing diffusion probabilistic models, score-based generative models, consistency models, rectified flow, and related methods. By standardizing notations and aligning them with code implementations, it aims to bridge the "paper-to-code" gap and facilitate robust implementations and fair comparisons. The content encompasses the fundamentals of diffusion models, the pre-training process, and various post-training methods. Post-training techniques include model distillation and reward-based fine-tuning. Designed as a practical guide, it emphasizes clarity and usability over theoretical depth, focusing on widely adopted approaches in generative modeling with diffusion models.
DOLLAR: Few-Step Video Generation via Distillation and Latent Reward Optimization
Dec 20, 2024Diffusion probabilistic models have shown significant progress in video generation; however, their computational efficiency is limited by the large number of sampling steps required. Reducing sampling steps often compromises video quality or generation diversity. In this work, we introduce a distillation method that combines variational score distillation and consistency distillation to achieve few-step video generation, maintaining both high quality and diversity. We also propose a latent reward model fine-tuning approach to further enhance video generation performance according to any specified reward metric. This approach reduces memory usage and does not require the reward to be differentiable. Our method demonstrates state-of-the-art performance in few-step generation for 10-second videos (128 frames at 12 FPS). The distilled student model achieves a score of 82.57 on VBench, surpassing the teacher model as well as baseline models Gen-3, T2V-Turbo, and Kling. One-step distillation accelerates the teacher model's diffusion sampling by up to 278.6 times, enabling near real-time generation. Human evaluations further validate the superior performance of our 4-step student models compared to teacher model using 50-step DDIM sampling.
TopV-Nav: Unlocking the Top-View Spatial Reasoning Potential of MLLM for Zero-shot Object Navigation
Nov 25, 2024



The Zero-Shot Object Navigation (ZSON) task requires embodied agents to find a previously unseen object by navigating in unfamiliar environments. Such a goal-oriented exploration heavily relies on the ability to perceive, understand, and reason based on the spatial information of the environment. However, current LLM-based approaches convert visual observations to language descriptions and reason in the linguistic space, leading to the loss of spatial information. In this paper, we introduce TopV-Nav, a MLLM-based method that directly reasons on the top-view map with complete spatial information. To fully unlock the MLLM's spatial reasoning potential in top-view perspective, we propose the Adaptive Visual Prompt Generation (AVPG) method to adaptively construct semantically-rich top-view map. It enables the agent to directly utilize spatial information contained in the top-view map to conduct thorough reasoning. Besides, we design a Dynamic Map Scaling (DMS) mechanism to dynamically zoom top-view map at preferred scales, enhancing local fine-grained reasoning. Additionally, we devise a Target-Guided Navigation (TGN) mechanism to predict and to utilize target locations, facilitating global and human-like exploration. Experiments on MP3D and HM3D benchmarks demonstrate the superiority of our TopV-Nav, e.g., $+3.9\%$ SR and $+2.0\%$ SPL absolute improvements on HM3D.