 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
Factuality Matters: When Image Generation and Editing Meet Structured Visuals
Oct 06, 2025While modern visual generation models excel at creating aesthetically pleasing natural images, they struggle with producing or editing structured visuals like charts, diagrams, and mathematical figures, which demand composition planning, text rendering, and multimodal reasoning for factual fidelity. To address this, we present the first comprehensive, systematic investigation of this domain, encompassing data construction, model training, and an evaluation benchmark. First, we construct a large-scale dataset of 1.3 million high-quality structured image pairs derived from executable drawing programs and augmented with chain-of-thought reasoning annotations. Building on it, we train a unified model that integrates a VLM with FLUX.1 Kontext via a lightweight connector for enhanced multimodal understanding. A three-stage training curriculum enables progressive feature alignment, knowledge infusion, and reasoning-augmented generation, further boosted by an external reasoner at inference time. Finally, we introduce StructBench, a novel benchmark for generation and editing with over 1,700 challenging instances, and an accompanying evaluation metric, StructScore, which employs a multi-round Q\&A protocol to assess fine-grained factual accuracy. Evaluations of 15 models reveal that even leading closed-source systems remain far from satisfactory. Our model attains strong editing performance, and inference-time reasoning yields consistent gains across diverse architectures. By releasing the dataset, model, and benchmark, we aim to advance unified multimodal foundations for structured visuals.
SAIL-VL2 Technical Report
Sep 18, 2025We introduce SAIL-VL2, an open-suite vision-language foundation model (LVM) for comprehensive multimodal understanding and reasoning. As the successor to SAIL-VL, SAIL-VL2 achieves state-of-the-art performance at the 2B and 8B parameter scales across diverse image and video benchmarks, demonstrating strong capabilities from fine-grained perception to complex reasoning. Its effectiveness is driven by three core innovations. First, a large-scale data curation pipeline with scoring and filtering strategies enhances both quality and distribution across captioning, OCR, QA, and video data, improving training efficiency. Second, a progressive training framework begins with a powerful pre-trained vision encoder (SAIL-ViT), advances through multimodal pre-training, and culminates in a thinking-fusion SFT-RL hybrid paradigm that systematically strengthens model capabilities. Third, architectural advances extend beyond dense LLMs to efficient sparse Mixture-of-Experts (MoE) designs. With these contributions, SAIL-VL2 demonstrates competitive performance across 106 datasets and achieves state-of-the-art results on challenging reasoning benchmarks such as MMMU and MathVista. Furthermore, on the OpenCompass leaderboard, SAIL-VL2-2B ranks first among officially released open-source models under the 4B parameter scale, while serving as an efficient and extensible foundation for the open-source multimodal community.
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
Aug 07, 2025
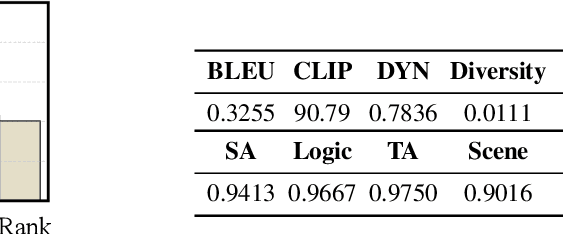

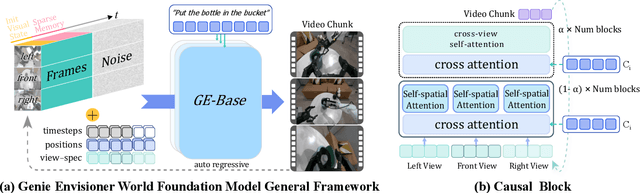
We introduce Genie Envisioner (GE), a unified world foundation platform for robotic manipulation that integrates policy learning, evaluation, and simulation within a single video-generative framework. At its core, GE-Base is a large-scale, instruction-conditioned video diffusion model that captures the spatial, temporal, and semantic dynamics of real-world robotic interactions in a structured latent space. Built upon this foundation, GE-Act maps latent representations to executable action trajectories through a lightweight, flow-matching decoder, enabling precise and generalizable policy inference across diverse embodiments with minimal supervision. To support scalable evaluation and training, GE-Sim serves as an action-conditioned neural simulator, producing high-fidelity rollouts for closed-loop policy development. The platform is further equipped with EWMBench, a standardized benchmark suite measuring visual fidelity, physical consistency, and instruction-action alignment. Together, these components establish Genie Envisioner as a scalable and practical foundation for instruction-driven, general-purpose embodied intelligence. All code, models, and benchmarks will be released publicly.
RoboCerebra: A Large-scale Benchmark for Long-horizon Robotic Manipulation Evaluation
Jun 07, 2025Recent advances in vision-language models (VLMs) have enabled instruction-conditioned robotic systems with improved generalization. However, most existing work focuses on reactive System 1 policies, underutilizing VLMs' strengths in semantic reasoning and long-horizon planning. These System 2 capabilities-characterized by deliberative, goal-directed thinking-remain under explored due to the limited temporal scale and structural complexity of current benchmarks. To address this gap, we introduce RoboCerebra, a benchmark for evaluating high-level reasoning in long-horizon robotic manipulation. RoboCerebra includes: (1) a large-scale simulation dataset with extended task horizons and diverse subtask sequences in household environments; (2) a hierarchical framework combining a high-level VLM planner with a low-level vision-language-action (VLA) controller; and (3) an evaluation protocol targeting planning, reflection, and memory through structured System 1-System 2 interaction. The dataset is constructed via a top-down pipeline, where GPT generates task instructions and decomposes them into subtask sequences. Human operators execute the subtasks in simulation, yielding high-quality trajectories with dynamic object variations. Compared to prior benchmarks, RoboCerebra features significantly longer action sequences and denser annotations. We further benchmark state-of-the-art VLMs as System 2 modules and analyze their performance across key cognitive dimensions, advancing the development of more capable and generalizable robotic planners.
UAV-Flow Colosseo: A Real-World Benchmark for Flying-on-a-Word UAV Imitation Learning
May 21, 2025Unmanned Aerial Vehicles (UAVs) are evolving into language-interactive platforms, enabling more intuitive forms of human-drone interaction. While prior works have primarily focused on high-level planning and long-horizon navigation, we shift attention to language-guided fine-grained trajectory control, where UAVs execute short-range, reactive flight behaviors in response to language instructions. We formalize this problem as the Flying-on-a-Word (Flow) task and introduce UAV imitation learning as an effective approach. In this framework, UAVs learn fine-grained control policies by mimicking expert pilot trajectories paired with atomic language instructions. To support this paradigm, we present UAV-Flow, the first real-world benchmark for language-conditioned, fine-grained UAV control. It includes a task formulation, a large-scale dataset collected in diverse environments, a deployable control framework, and a simulation suite for systematic evaluation. Our design enables UAVs to closely imitate the precise, expert-level flight trajectories of human pilots and supports direct deployment without sim-to-real gap. We conduct extensive experiments on UAV-Flow, benchmarking VLN and VLA paradigms. Results show that VLA models are superior to VLN baselines and highlight the critical role of spatial grounding in the fine-grained Flow setting.
RBF++: Quantifying and Optimizing Reasoning Boundaries across Measurable and Unmeasurable Capabilities for Chain-of-Thought Reasoning
May 19, 2025Chain-of-Thought (CoT) reasoning has proven effective in enhancing large language models (LLMs) on complex tasks, spurring research into its underlying mechanisms. However, two primary challenges remain for real-world applications: (1) the lack of quantitative metrics and actionable guidelines for evaluating and optimizing measurable boundaries of CoT capability, and (2) the absence of methods to assess boundaries of unmeasurable CoT capability, such as multimodal perception. To address these gaps, we introduce the Reasoning Boundary Framework++ (RBF++). To tackle the first challenge, we define the reasoning boundary (RB) as the maximum limit of CoT performance. We also propose a combination law for RBs, enabling quantitative analysis and offering actionable guidance across various CoT tasks. For the second challenge, particularly in multimodal scenarios, we introduce a constant assumption, which replaces unmeasurable RBs with scenario-specific constants. Additionally, we propose the reasoning boundary division mechanism, which divides unmeasurable RBs into two sub-boundaries, facilitating the quantification and optimization of both unmeasurable domain knowledge and multimodal perception capabilities. Extensive experiments involving 38 models across 13 tasks validate the feasibility of our framework in cross-modal settings. Additionally, we evaluate 10 CoT strategies, offer insights into optimization and decay from two complementary perspectives, and expand evaluation benchmarks for measuring RBs in LLM reasoning. We hope this work advances the understanding of RBs and optimization strategies in LLMs. Code and data are available at https://github.com/LightChen233/reasoning-boundary.
EnerVerse-AC: Envisioning Embodied Environments with Action Condition
May 14, 2025Robotic imitation learning has advanced from solving static tasks to addressing dynamic interaction scenarios, but testing and evaluation remain costly and challenging due to the need for real-time interaction with dynamic environments. We propose EnerVerse-AC (EVAC), an action-conditional world model that generates future visual observations based on an agent's predicted actions, enabling realistic and controllable robotic inference. Building on prior architectures, EVAC introduces a multi-level action-conditioning mechanism and ray map encoding for dynamic multi-view image generation while expanding training data with diverse failure trajectories to improve generalization. As both a data engine and evaluator, EVAC augments human-collected trajectories into diverse datasets and generates realistic, action-conditioned video observations for policy testing, eliminating the need for physical robots or complex simulations. This approach significantly reduces costs while maintaining high fidelity in robotic manipulation evaluation. Extensive experiments validate the effectiveness of our method. Code, checkpoints, and datasets can be found at <https://annaj2178.github.io/EnerverseAC.github.io>.
EWMBench: Evaluating Scene, Motion, and Semantic Quality in Embodied World Models
May 14, 2025Recent advances in creative AI have enabled the synthesis of high-fidelity images and videos conditioned on language instructions. Building on these developments, text-to-video diffusion models have evolved into embodied world models (EWMs) capable of generating physically plausible scenes from language commands, effectively bridging vision and action in embodied AI applications. This work addresses the critical challenge of evaluating EWMs beyond general perceptual metrics to ensure the generation of physically grounded and action-consistent behaviors. We propose the Embodied World Model Benchmark (EWMBench), a dedicated framework designed to evaluate EWMs based on three key aspects: visual scene consistency, motion correctness, and semantic alignment. Our approach leverages a meticulously curated dataset encompassing diverse scenes and motion patterns, alongside a comprehensive multi-dimensional evaluation toolkit, to assess and compare candidate models. The proposed benchmark not only identifies the limitations of existing video generation models in meeting the unique requirements of embodied tasks but also provides valuable insights to guide future advancements in the field. The dataset and evaluation tools are publicly available at https://github.com/AgibotTech/EWMBench.
From Reflection to Perfection: Scaling Inference-Time Optimization for Text-to-Image Diffusion Models via Reflection Tuning
Apr 22, 2025Recent text-to-image diffusion models achieve impressive visual quality through extensive scaling of training data and model parameters, yet they often struggle with complex scenes and fine-grained details. Inspired by the self-reflection capabilities emergent in large language models, we propose ReflectionFlow, an inference-time framework enabling diffusion models to iteratively reflect upon and refine their outputs. ReflectionFlow introduces three complementary inference-time scaling axes: (1) noise-level scaling to optimize latent initialization; (2) prompt-level scaling for precise semantic guidance; and most notably, (3) reflection-level scaling, which explicitly provides actionable reflections to iteratively assess and correct previous generations. To facilitate reflection-level scaling, we construct GenRef, a large-scale dataset comprising 1 million triplets, each containing a reflection, a flawed image, and an enhanced image. Leveraging this dataset, we efficiently perform reflection tuning on state-of-the-art diffusion transformer, FLUX.1-dev, by jointly modeling multimodal inputs within a unified framework. Experimental results show that ReflectionFlow significantly outperforms naive noise-level scaling methods, offering a scalable and compute-efficient solution toward higher-quality image synthesis on challenging tasks.