 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction-Oriented Preference Alignment for Enhancing Multi-Modal Comprehension Capability of MLLMs
Paper and Code
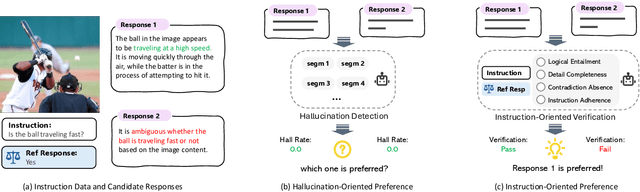
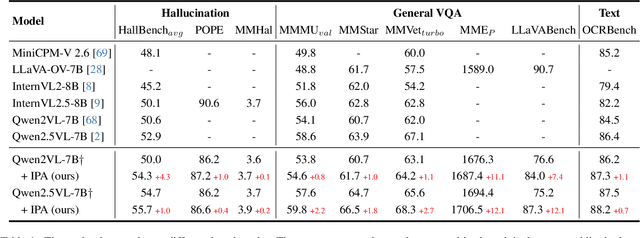
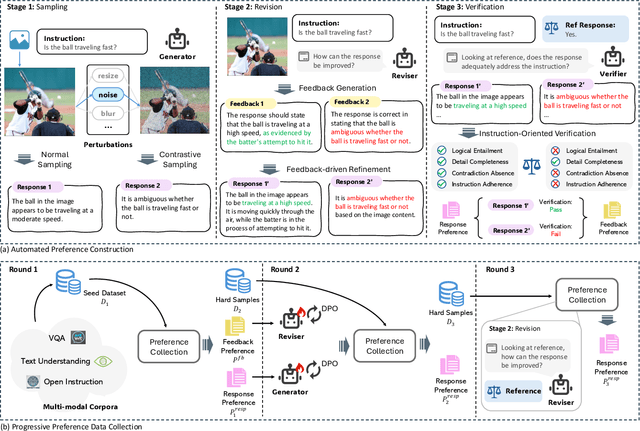
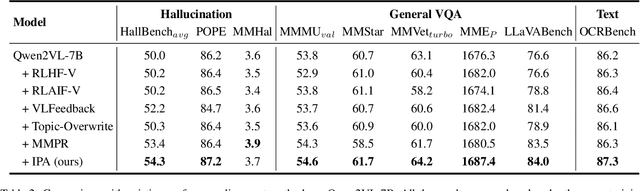
Preference alignment has emerged as an effective strategy to enhance the performance of Multimodal Large Language Models (MLLMs) following supervised fine-tuning. While existing preference alignment methods predominantly target hallucination factors, they overlook the factors essential for multi-modal comprehension capabilities, often narrowing their improvements on hallucination mitigation. To bridge this gap, we propose Instruction-oriented Preference Alignment (IPA), a scalable framework designed to automatically construct alignment preferences grounded in instruction fulfillment efficacy. Our method involves an automated preference construction coupled with a dedicated verification process that identifies instruction-oriented factors, avoiding significant variability in response representations. Additionally, IPA incorporates a progressive preference collection pipeline, further recalling challenging samples through model self-evolution and reference-guided refinement. Experiments conducted on Qwen2VL-7B demonstrate IPA's effectiveness across multiple benchmarks, including hallucination evaluation, visual question answering, and text understanding tasks, highlighting its capability to enhance general comprehension.