 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStage-adaptive Token Selection for Efficient Omni-modal LLMs
May 19, 2026Omni-modal large language models (om-LLMs) achieve unified audio-visual understanding by encoding video and audio into temporally aligned token sequences interleaved at the window level. However, processing these dense non-textual tokens throughout the LLM incurs substantial computational overhead. Although training-free token selection can reduce this cost, existing methods either focus on visual-only inputs or prune om-LLM tokens only before the LLM with fixed per-modality ratios, failing to capture how cross-modal token importance evolves across layers. To address this limitation, we first analyze the layer-wise token dependency of om-LLMs. We find that visual and audio dependencies follow a block-wise pattern and gradually weaken with depth, indicating that many late-layer non-textual tokens become redundant after cross-modal fusion. Motivated by this observation, we propose SEATS, a training-free, stage-adaptive token selection method for efficient om-LLM inference. Before the LLM, SEATS removes spatiotemporal redundancy via attention-weighted diversity selection. Inside the LLM, it progressively prunes tokens across blocks and dynamically allocates the retention budget from temporal windows to modalities using query relevance scores. In late layers, it removes all remaining non-textual tokens once cross-modal fusion is complete. Experiments on Qwen2.5-Omni and Qwen3-Omni demonstrate that SEATS effectively improves inference efficiency. Retaining only 10% of visual and audio tokens, it achieves a 9.3x FLOPs reduction and a 4.8x prefill speedup while preserving 96.3% of the original performance.
Semantic-Enriched Latent Visual Reasoning
May 19, 2026Multimodal latent-space reasoning aims to replace explicit thinking with images by performing visual reasoning directly in a compact latent space. However, existing approaches largely rely on visual supervision and produce latent representations that lack sufficient semantic richness, limiting their ability to support diverse region-level reasoning tasks. In this work, we introduce Semantic-Enriched Latent Visual Reasoning (SLVR), a two-stage learning framework that enriches latent representations with attribute-level visual semantics and aligns them with diverse reasoning objectives. In the first stage, SLVR learns semantically enriched region-centric latents under fine-grained attribute supervision. In the second stage, we design Multi-query Group Relative Policy Optimization (M-GRPO) to align latent representations across multiple queries grounded in the same region. To support this framework, we construct SLV-Set, comprising approximately 400K region-level attribute annotations and 800K multi-query question answering samples, and introduce SV-QA, a benchmark that evaluates latent reasoning under semantic variation. Experiments demonstrate that SLVR improves the robustness and semantic consistency of latent visual reasoning compared to existing baselines.
OmniPro: A Comprehensive Benchmark for Omni-Proactive Streaming Video Understanding
May 18, 2026Omni-proactive streaming video understanding, i.e., autonomously deciding when to speak and what to say from continuous audio-visual streams, is an emerging capability of omni-modal large language models. Existing benchmarks fall short in three key aspects: they rely primarily on visual signals, adopt polling or fixed-timestamp protocols instead of true proactive evaluation, and cover only a limited range of tasks, preventing reliable assessment and differentiation of omni-proactive streaming models. We present OmniPro, the first benchmark to jointly evaluate omni-modal perception, proactive responding, and diverse video understanding tasks. It comprises 2,700 human-verified samples spanning 9 sub-tasks and 3 cognitive levels, covering 6 basic video understanding capabilities. Notably, 84% of samples require audio signals (speech or non-speech), and each sample is annotated with modality-isolation labels to enable fine-grained multimodal analysis. We further introduce a dual-mode evaluation protocol: Probe mode assesses content understanding by querying the model before and after each ground-truth trigger, while Online mode evaluates full proactive ability by requiring models to autonomously decide when to respond in streaming input. Evaluating 11 representative models reveals three key findings: (1) audio provides consistent gains but with highly variable utilization across models, (2) performance degrades significantly over time, indicating limited long-horizon robustness, and (3) non-speech audio perception remains the weakest dimension.
Beyond Chain-of-Thought: Rewrite as a Universal Interface for Generative Multimodal Embeddings
Apr 24, 2026Multimodal Large Language Models (MLLMs) have emerged as a promising foundation for universal multimodal embeddings. Recent studies have shown that reasoning-driven generative multimodal embeddings can outperform discriminative embeddings on several embedding tasks. However, Chain-of-Thought (CoT) reasoning tends to generate redundant thinking steps and introduce semantic ambiguity in the summarized answers in broader retrieval scenarios. To address this limitation, we propose Rewrite-driven Multimodal Embedding (RIME), a unified framework that jointly optimizes generation and embedding through a retrieval-friendly rewrite. Meanwhile, we present the Cross-Mode Alignment (CMA) to bridge the generative and discriminative embedding spaces, enabling flexible mutual retrieval to trade off efficiency and accuracy. Based on this, we also introduce Refine Reinforcement Learning (Refine-RL) that treats discriminative embeddings as stable semantic anchors to guide the rewrite optimization. Extensive experiments on MMEB-V2, MRMR and UVRB demonstrate that RIME substantially outperforms prior generative embedding models while significantly reducing the length of thinking.
AdaMem: Adaptive User-Centric Memory for Long-Horizon Dialogue Agents
Mar 17, 2026Large language model (LLM) agents increasingly rely on external memory to support long-horizon interaction, personalized assistance, and multi-step reasoning. However, existing memory systems still face three core challenges: they often rely too heavily on semantic similarity, which can miss evidence crucial for user-centric understanding; they frequently store related experiences as isolated fragments, weakening temporal and causal coherence; and they typically use static memory granularities that do not adapt well to the requirements of different questions. We propose AdaMem, an adaptive user-centric memory framework for long-horizon dialogue agents. AdaMem organizes dialogue history into working, episodic, persona, and graph memories, enabling the system to preserve recent context, structured long-term experiences, stable user traits, and relation-aware connections within a unified framework. At inference time, AdaMem first resolves the target participant, then builds a question-conditioned retrieval route that combines semantic retrieval with relation-aware graph expansion only when needed, and finally produces the answer through a role-specialized pipeline for evidence synthesis and response generation. We evaluate AdaMem on the LoCoMo and PERSONAMEM benchmarks for long-horizon reasoning and user modeling. Experimental results show that AdaMem achieves state-of-the-art performance on both benchmarks. The code will be released upon acceptance.
Learning Cross-View Object Correspondence via Cycle-Consistent Mask Prediction
Feb 22, 2026We study the task of establishing object-level visual correspondence across different viewpoints in videos, focusing on the challenging egocentric-to-exocentric and exocentric-to-egocentric scenarios. We propose a simple yet effective framework based on conditional binary segmentation, where an object query mask is encoded into a latent representation to guide the localization of the corresponding object in a target video. To encourage robust, view-invariant representations, we introduce a cycle-consistency training objective: the predicted mask in the target view is projected back to the source view to reconstruct the original query mask. This bidirectional constraint provides a strong self-supervisory signal without requiring ground-truth annotations and enables test-time training (TTT) at inference. Experiments on the Ego-Exo4D and HANDAL-X benchmarks demonstrate the effectiveness of our optimization objective and TTT strategy, achieving state-of-the-art performance. The code is available at https://github.com/shannany0606/CCMP.
D-ORCA: Dialogue-Centric Optimization for Robust Audio-Visual Captioning
Feb 08, 2026Spoken dialogue is a primary source of information in videos; therefore, accurately identifying who spoke what and when is essential for deep video understanding. We introduce D-ORCA, a \textbf{d}ialogue-centric \textbf{o}mni-modal large language model optimized for \textbf{r}obust audio-visual \textbf{ca}ptioning. We further curate DVD, a large-scale, high-quality bilingual dataset comprising nearly 40,000 multi-party dialogue videos for training and 2000 videos for evaluation in English and Mandarin, addressing a critical gap in the open-source ecosystem. To ensure fine-grained captioning accuracy, we adopt group relative policy optimization with three novel reward functions that assess speaker attribution accuracy, global speech content accuracy, and sentence-level temporal boundary alignment. These rewards are derived from evaluation metrics widely used in speech processing and, to our knowledge, are applied for the first time as reinforcement learning objectives for audio-visual captioning. Extensive experiments demonstrate that D-ORCA substantially outperforms existing open-source models in speaker identification, speech recognition, and temporal grounding. Notably, despite having only 8 billion parameters, D-ORCA achieves performance competitive with Qwen3-Omni across several general-purpose audio-visual understanding benchmarks. Demos are available at \href{https://d-orca-llm.github.io/}{https://d-orca-llm.github.io/}. Our code, data, and checkpoints will be available at \href{https://github.com/WeChatCV/D-ORCA/}{https://github.com/WeChatCV/D-ORCA/}.
SAIL: Self-Amplified Iterative Learning for Diffusion Model Alignment with Minimal Human Feedback
Feb 05, 2026Aligning diffusion models with human preferences remains challenging, particularly when reward models are unavailable or impractical to obtain, and collecting large-scale preference datasets is prohibitively expensive. \textit{This raises a fundamental question: can we achieve effective alignment using only minimal human feedback, without auxiliary reward models, by unlocking the latent capabilities within diffusion models themselves?} In this paper, we propose \textbf{SAIL} (\textbf{S}elf-\textbf{A}mplified \textbf{I}terative \textbf{L}earning), a novel framework that enables diffusion models to act as their own teachers through iterative self-improvement. Starting from a minimal seed set of human-annotated preference pairs, SAIL operates in a closed-loop manner where the model progressively generates diverse samples, self-annotates preferences based on its evolving understanding, and refines itself using this self-augmented dataset. To ensure robust learning and prevent catastrophic forgetting, we introduce a ranked preference mixup strategy that carefully balances exploration with adherence to initial human priors. Extensive experiments demonstrate that SAIL consistently outperforms state-of-the-art methods across multiple benchmarks while using merely 6\% of the preference data required by existing approaches, revealing that diffusion models possess remarkable self-improvement capabilities that, when properly harnessed, can effectively replace both large-scale human annotation and external reward models.
ObjEmbed: Towards Universal Multimodal Object Embeddings
Feb 03, 2026Aligning objects with corresponding textual descriptions is a fundamental challenge and a realistic requirement in vision-language understanding. While recent multimodal embedding models excel at global image-text alignment, they often struggle with fine-grained alignment between image regions and specific phrases. In this work, we present ObjEmbed, a novel MLLM embedding model that decomposes the input image into multiple regional embeddings, each corresponding to an individual object, along with global embeddings. It supports a wide range of visual understanding tasks like visual grounding, local image retrieval, and global image retrieval. ObjEmbed enjoys three key properties: (1) Object-Oriented Representation: It captures both semantic and spatial aspects of objects by generating two complementary embeddings for each region: an object embedding for semantic matching and an IoU embedding that predicts localization quality. The final object matching score combines semantic similarity with the predicted IoU, enabling more accurate retrieval. (2) Versatility: It seamlessly handles both region-level and image-level tasks. (3) Efficient Encoding: All objects in an image, along with the full image, are encoded in a single forward pass for high efficiency. Superior performance on 18 diverse benchmarks demonstrates its strong semantic discrimination.
MMhops-R1: Multimodal Multi-hop Reasoning
Dec 16, 2025


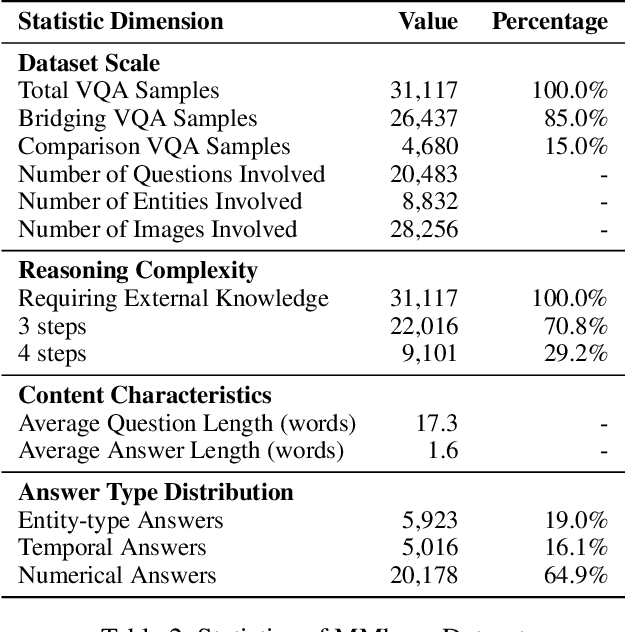
The ability to perform multi-modal multi-hop reasoning by iteratively integrating information across various modalities and external knowledge is critical for addressing complex real-world challenges. However, existing Multi-modal Large Language Models (MLLMs) are predominantly limited to single-step reasoning, as existing benchmarks lack the complexity needed to evaluate and drive multi-hop abilities. To bridge this gap, we introduce MMhops, a novel, large-scale benchmark designed to systematically evaluate and foster multi-modal multi-hop reasoning. MMhops dataset comprises two challenging task formats, Bridging and Comparison, which necessitate that models dynamically construct complex reasoning chains by integrating external knowledge. To tackle the challenges posed by MMhops, we propose MMhops-R1, a novel multi-modal Retrieval-Augmented Generation (mRAG) framework for dynamic reasoning. Our framework utilizes reinforcement learning to optimize the model for autonomously planning reasoning paths, formulating targeted queries, and synthesizing multi-level information. Comprehensive experiments demonstrate that MMhops-R1 significantly outperforms strong baselines on MMhops, highlighting that dynamic planning and multi-modal knowledge integration are crucial for complex reasoning. Moreover, MMhops-R1 demonstrates strong generalization to tasks requiring fixed-hop reasoning, underscoring the robustness of our dynamic planning approach. In conclusion, our work contributes a challenging new benchmark and a powerful baseline model, and we will release the associated code, data, and weights to catalyze future research in this critical area.