 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Large Multimodal Models for Automatic Pronunciation Assessment
Sep 19, 2025Automatic Pronunciation Assessment (APA) is critical for Computer-Assisted Language Learning (CALL), requiring evaluation across multiple granularities and aspects. Large Multimodal Models (LMMs) present new opportunities for APA, but their effectiveness in fine-grained assessment remains uncertain. This work investigates fine-tuning LMMs for APA using the Speechocean762 dataset and a private corpus. Fine-tuning significantly outperforms zero-shot settings and achieves competitive results on single-granularity tasks compared to public and commercial systems. The model performs well at word and sentence levels, while phoneme-level assessment remains challenging. We also observe that the Pearson Correlation Coefficient (PCC) reaches 0.9, whereas Spearman's rank Correlation Coefficient (SCC) remains around 0.6, suggesting that SCC better reflects ordinal consistency. These findings highlight both the promise and limitations of LMMs for APA and point to future work on fine-grained modeling and rank-aware evaluation.
Exploring the Potential of Large Multimodal Models as Effective Alternatives for Pronunciation Assessment
Mar 14, 2025Large Multimodal Models (LMMs) have demonstrated exceptional performance across a wide range of domains. This paper explores their potential in pronunciation assessment tasks, with a particular focus on evaluating the capabilities of the Generative Pre-trained Transformer (GPT) model, specifically GPT-4o. Our study investigates its ability to process speech and audio for pronunciation assessment across multiple levels of granularity and dimensions, with an emphasis on feedback generation and scoring. For our experiments, we use the publicly available Speechocean762 dataset. The evaluation focuses on two key aspects: multi-level scoring and the practicality of the generated feedback. Scoring results are compared against the manual scores provided in the Speechocean762 dataset, while feedback quality is assessed using Large Language Models (LLMs). The findings highlight the effectiveness of integrating LMMs with traditional methods for pronunciation assessment, offering insights into the model's strengths and identifying areas for further improvement.
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
Mar 13, 2025Large Language Models have demonstrated remarkable reasoning capability in complex textual tasks. However, multimodal reasoning, which requires integrating visual and textual information, remains a significant challenge. Existing visual-language models often struggle to effectively analyze and reason visual content, resulting in suboptimal performance on complex reasoning tasks. Moreover, the absence of comprehensive benchmarks hinders the accurate assessment of multimodal reasoning capabilities. In this paper, we introduce R1-Onevision, a multimodal reasoning model designed to bridge the gap between visual perception and deep reasoning. To achieve this, we propose a cross-modal reasoning pipeline that transforms images into formal textural representations, enabling precise language-based reasoning. Leveraging this pipeline, we construct the R1-Onevision dataset which provides detailed, step-by-step multimodal reasoning annotations across diverse domains. We further develop the R1-Onevision model through supervised fine-tuning and reinforcement learning to cultivate advanced reasoning and robust generalization abilities. To comprehensively evaluate multimodal reasoning performance across different grades, we introduce R1-Onevision-Bench, a benchmark aligned with human educational stages, covering exams from junior high school to university and beyond. Experimental results show that R1-Onevision achieves state-of-the-art performance, outperforming models such as GPT-4o and Qwen2.5-VL on multiple challenging multimodal reasoning benchmarks.
Assessing Phrase Break of ESL Speech with Pre-trained Language Models and Large Language Models
Jun 08, 2023



This work introduces approaches to assessing phrase breaks in ESL learners' speech using pre-trained language models (PLMs) and large language models (LLMs). There are two tasks: overall assessment of phrase break for a speech clip and fine-grained assessment of every possible phrase break position. To leverage NLP models, speech input is first force-aligned with texts, and then pre-processed into a token sequence, including words and phrase break information. To utilize PLMs, we propose a pre-training and fine-tuning pipeline with the processed tokens. This process includes pre-training with a replaced break token detection module and fine-tuning with text classification and sequence labeling. To employ LLMs, we design prompts for ChatGPT. The experiments show that with the PLMs, the dependence on labeled training data has been greatly reduced, and the performance has improved. Meanwhile, we verify that ChatGPT, a renowned LLM, has potential for further advancement in this area.
Speech BERT Embedding For Improving Prosody in Neural TTS
Jun 15, 2021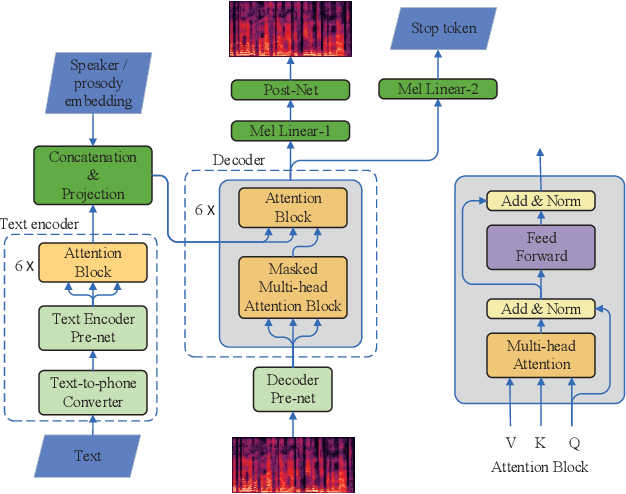
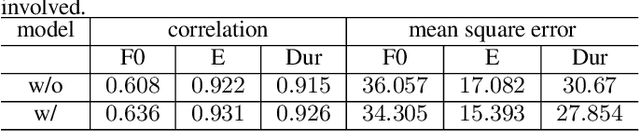
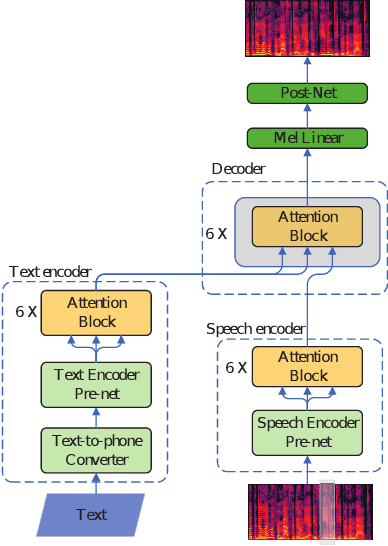
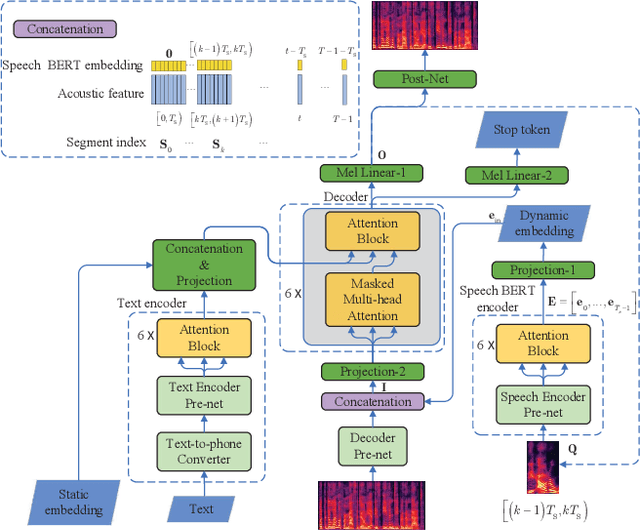
This paper presents a speech BERT model to extract embedded prosody information in speech segments for improving the prosody of synthesized speech in neural text-to-speech (TTS). As a pre-trained model, it can learn prosody attributes from a large amount of speech data, which can utilize more data than the original training data used by the target TTS. The embedding is extracted from the previous segment of a fixed length in the proposed BERT. The extracted embedding is then used together with the mel-spectrogram to predict the following segment in the TTS decoder. Experimental results obtained by the Transformer TTS show that the proposed BERT can extract fine-grained, segment-level prosody, which is complementary to utterance-level prosody to improve the final prosody of the TTS speech. The objective distortions measured on a single speaker TTS are reduced between the generated speech and original recordings. Subjective listening tests also show that the proposed approach is favorably preferred over the TTS without the BERT prosody embedding module, for both in-domain and out-of-domain applications. For Microsoft professional, single/multiple speakers and the LJ Speaker in the public database, subjective preference is similarly confirmed with the new BERT prosody embedding. TTS demo audio samples are in https://judy44chen.github.io/TTSSpeechBERT/.
Exploring Machine Speech Chain for Domain Adaptation and Few-Shot Speaker Adaptation
Apr 08, 2021



Machine Speech Chain, which integrates both end-to-end (E2E) automatic speech recognition (ASR) and text-to-speech (TTS) into one circle for joint training, has been proven to be effective in data augmentation by leveraging large amounts of unpaired data. In this paper, we explore the TTS->ASR pipeline in speech chain to do domain adaptation for both neural TTS and E2E ASR models, with only text data from target domain. We conduct experiments by adapting from audiobook domain (LibriSpeech) to presentation domain (TED-LIUM), there is a relative word error rate (WER) reduction of 10% for the E2E ASR model on the TED-LIUM test set, and a relative WER reduction of 51.5% in synthetic speech generated by neural TTS in the presentation domain. Further, we apply few-shot speaker adaptation for the E2E ASR by using a few utterances from target speakers in an unsupervised way, results in additional gains.
Robust Sequence-to-Sequence Acoustic Modeling with Stepwise Monotonic Attention for Neural TTS
Jun 03, 2019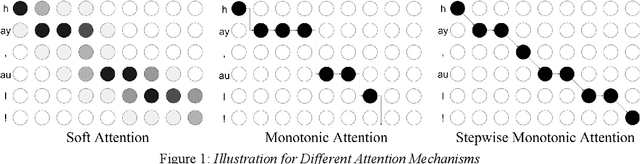
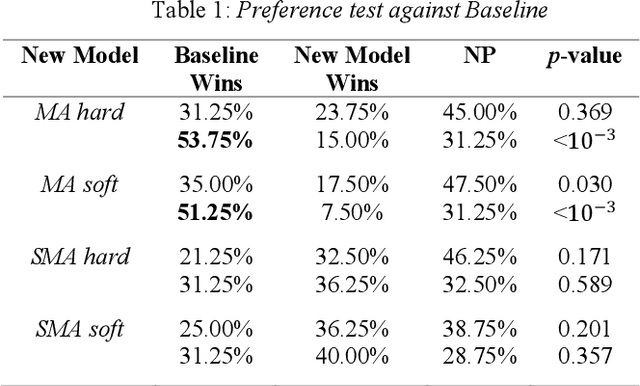

Neural TTS has demonstrated strong capabilities to generate human-like speech with high quality and naturalness, while its generalization to out-of-domain texts is still a challenging task, with regard to the design of attention-based sequence-to-sequence acoustic modeling. Various errors occur in those texts with unseen context, including attention collapse, skipping, repeating, etc., which limits the broader applications. In this paper, we propose a novel stepwise monotonic attention method in sequence-to-sequence acoustic modeling to improve the robustness on out-of-domain texts. The method utilizes the strict monotonic property in TTS with extra constraints on monotonic attention that the alignments between inputs and outputs sequence must be not only monotonic but also allowing no skipping on the inputs. In inference, soft attention could be used to evade mismatch between training and test in monotonic hard attention. The experimental results show that the proposed method could achieve significant improvements in robustness on various out-of-domain scenarios, without any regression on the in-domain test set.
Modeling Multi-speaker Latent Space to Improve Neural TTS: Quick Enrolling New Speaker and Enhancing Premium Voice
Dec 18, 2018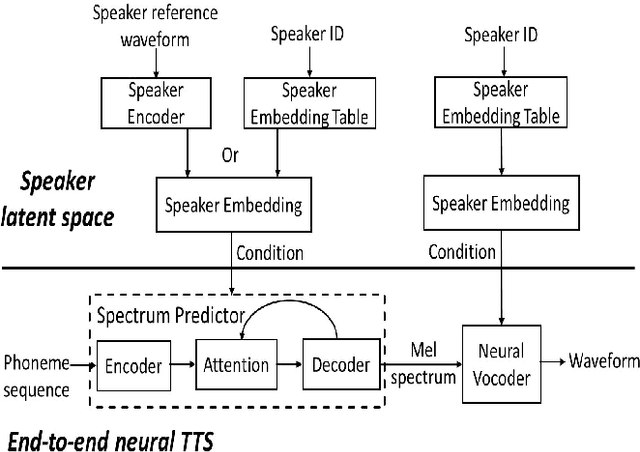

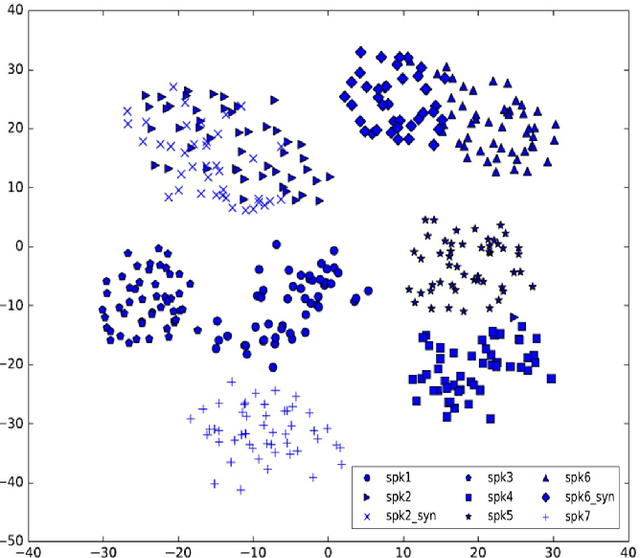

Neural TTS has shown it can generate high quality synthesized speech. In this paper, we investigate the multi-speaker latent space to improve neural TTS for adapting the system to new speakers with only several minutes of speech or enhancing a premium voice by utilizing the data from other speakers for richer contextual coverage and better generalization. A multi-speaker neural TTS model is built with the embedded speaker information in both spectral and speaker latent space. The experimental results show that, with less than 5 minutes of training data from a new speaker, the new model can achieve an MOS score of 4.16 in naturalness and 4.64 in speaker similarity close to human recordings (4.74). For a well-trained premium voice, we can achieve an MOS score of 4.5 for out-of-domain texts, which is comparable to an MOS of 4.58 for professional recordings, and significantly outperforms single speaker result of 4.28.