 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextSpeech: Expressive and Efficient Text-to-Speech for Paragraph Reading
Jul 03, 2023While state-of-the-art Text-to-Speech systems can generate natural speech of very high quality at sentence level, they still meet great challenges in speech generation for paragraph / long-form reading. Such deficiencies are due to i) ignorance of cross-sentence contextual information, and ii) high computation and memory cost for long-form synthesis. To address these issues, this work develops a lightweight yet effective TTS system, ContextSpeech. Specifically, we first design a memory-cached recurrence mechanism to incorporate global text and speech context into sentence encoding. Then we construct hierarchically-structured textual semantics to broaden the scope for global context enhancement. Additionally, we integrate linearized self-attention to improve model efficiency. Experiments show that ContextSpeech significantly improves the voice quality and prosody expressiveness in paragraph reading with competitive model efficiency. Audio samples are available at: https://contextspeech.github.io/demo/
A Multi-Stage Multi-Codebook VQ-VAE Approach to High-Performance Neural TTS
Sep 22, 2022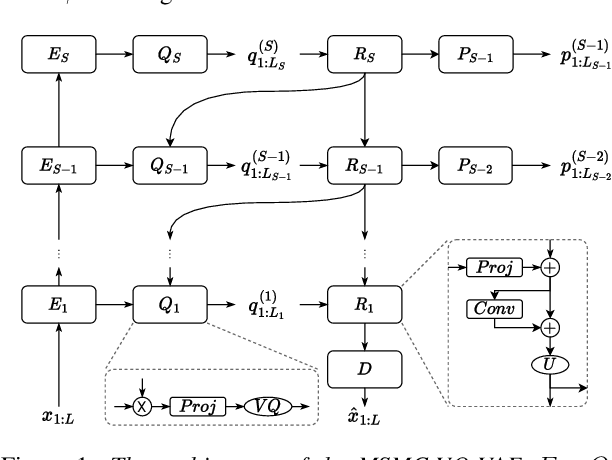
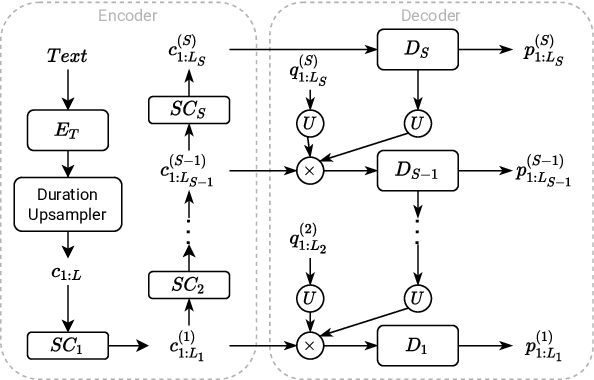
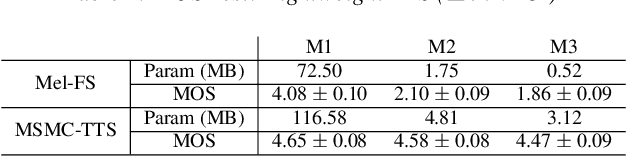
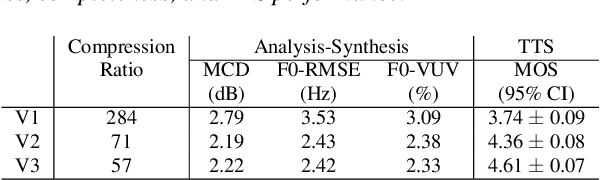
We propose a Multi-Stage, Multi-Codebook (MSMC) approach to high-performance neural TTS synthesis. A vector-quantized, variational autoencoder (VQ-VAE) based feature analyzer is used to encode Mel spectrograms of speech training data by down-sampling progressively in multiple stages into MSMC Representations (MSMCRs) with different time resolutions, and quantizing them with multiple VQ codebooks, respectively. Multi-stage predictors are trained to map the input text sequence to MSMCRs progressively by minimizing a combined loss of the reconstruction Mean Square Error (MSE) and "triplet loss". In synthesis, the neural vocoder converts the predicted MSMCRs into final speech waveforms. The proposed approach is trained and tested with an English TTS database of 16 hours by a female speaker. The proposed TTS achieves an MOS score of 4.41, which outperforms the baseline with an MOS of 3.62. Compact versions of the proposed TTS with much less parameters can still preserve high MOS scores. Ablation studies show that both multiple stages and multiple codebooks are effective for achieving high TTS performance.
ParaTTS: Learning Linguistic and Prosodic Cross-sentence Information in Paragraph-based TTS
Sep 14, 2022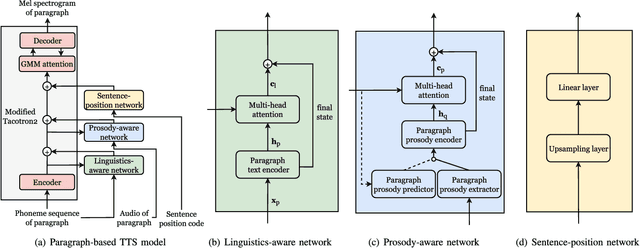


Recent advancements in neural end-to-end TTS models have shown high-quality, natural synthesized speech in a conventional sentence-based TTS. However, it is still challenging to reproduce similar high quality when a whole paragraph is considered in TTS, where a large amount of contextual information needs to be considered in building a paragraph-based TTS model. To alleviate the difficulty in training, we propose to model linguistic and prosodic information by considering cross-sentence, embedded structure in training. Three sub-modules, including linguistics-aware, prosody-aware and sentence-position networks, are trained together with a modified Tacotron2. Specifically, to learn the information embedded in a paragraph and the relations among the corresponding component sentences, we utilize linguistics-aware and prosody-aware networks. The information in a paragraph is captured by encoders and the inter-sentence information in a paragraph is learned with multi-head attention mechanisms. The relative sentence position in a paragraph is explicitly exploited by a sentence-position network. Trained on a storytelling audio-book corpus (4.08 hours), recorded by a female Mandarin Chinese speaker, the proposed TTS model demonstrates that it can produce rather natural and good-quality speech paragraph-wise. The cross-sentence contextual information, such as break and prosodic variations between consecutive sentences, can be better predicted and rendered than the sentence-based model. Tested on paragraph texts, of which the lengths are similar to, longer than, or much longer than the typical paragraph length of the training data, the TTS speech produced by the new model is consistently preferred over the sentence-based model in subjective tests and confirmed in objective measures.
Disentangling Style and Speaker Attributes for TTS Style Transfer
Jan 24, 2022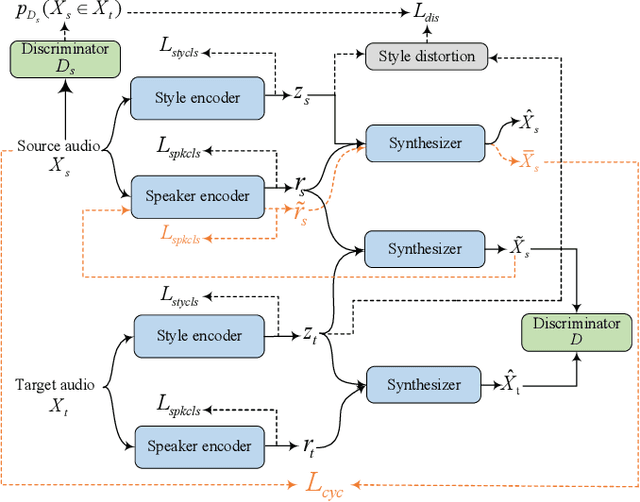
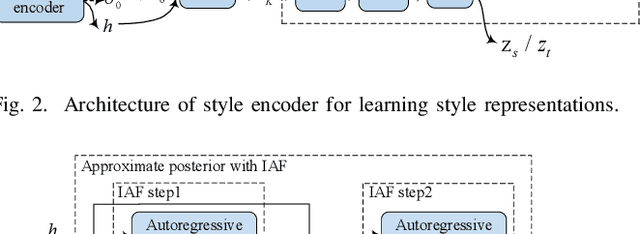
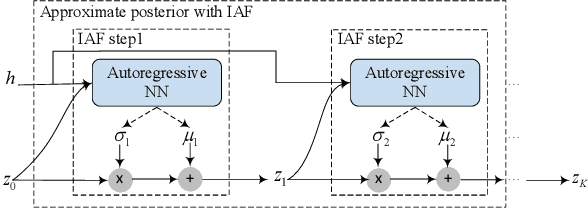

End-to-end neural TTS has shown improved performance in speech style transfer. However, the improvement is still limited by the available training data in both target styles and speakers. Additionally, degenerated performance is observed when the trained TTS tries to transfer the speech to a target style from a new speaker with an unknown, arbitrary style. In this paper, we propose a new approach to seen and unseen style transfer training on disjoint, multi-style datasets, i.e., datasets of different styles are recorded, one individual style by one speaker in multiple utterances. An inverse autoregressive flow (IAF) technique is first introduced to improve the variational inference for learning an expressive style representation. A speaker encoder network is then developed for learning a discriminative speaker embedding, which is jointly trained with the rest neural TTS modules. The proposed approach of seen and unseen style transfer is effectively trained with six specifically-designed objectives: reconstruction loss, adversarial loss, style distortion loss, cycle consistency loss, style classification loss, and speaker classification loss. Experiments demonstrate, both objectively and subjectively, the effectiveness of the proposed approach for seen and unseen style transfer tasks. The performance of our approach is superior to and more robust than those of four other reference systems of prior art.
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge
Oct 19, 2021
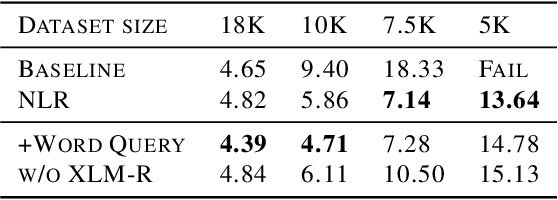
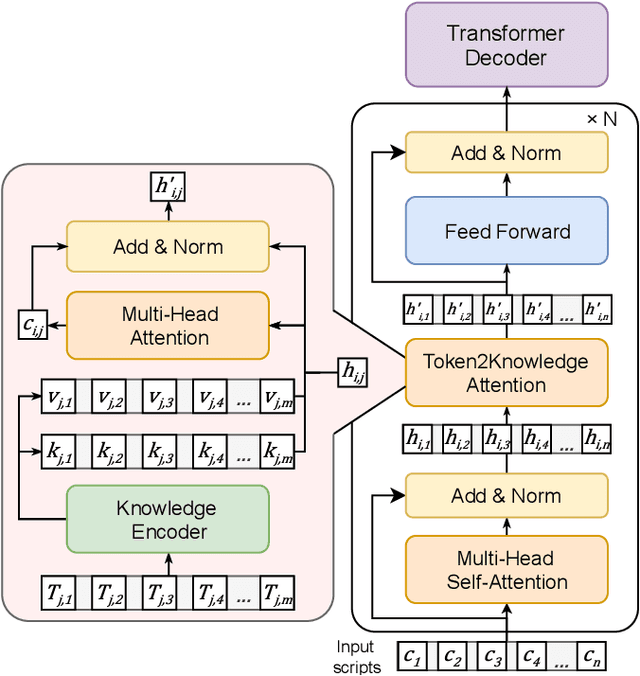
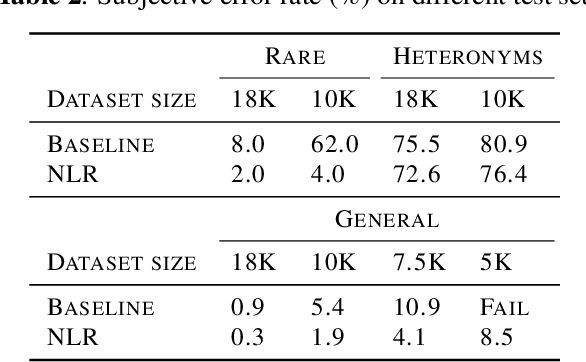
End-to-end TTS suffers from high data requirements as it is difficult for both costly speech corpora to cover all necessary knowledge and neural models to learn the knowledge, hence additional knowledge needs to be injected manually. For example, to capture pronunciation knowledge on languages without regular orthography, a complicated grapheme-to-phoneme pipeline needs to be built based on a structured, large pronunciation lexicon, leading to extra, sometimes high, costs to extend neural TTS to such languages. In this paper, we propose a framework to learn to extract knowledge from unstructured external resources using Token2Knowledge attention modules. The framework is applied to build a novel end-to-end TTS model named Neural Lexicon Reader that extracts pronunciations from raw lexicon texts. Experiments support the potential of our framework that the model significantly reduces pronunciation errors in low-resource, end-to-end Chinese TTS, and the lexicon-reading capability can be transferred to other languages with a smaller amount of data.
Improving Performance of Seen and Unseen Speech Style Transfer in End-to-end Neural TTS
Jun 18, 2021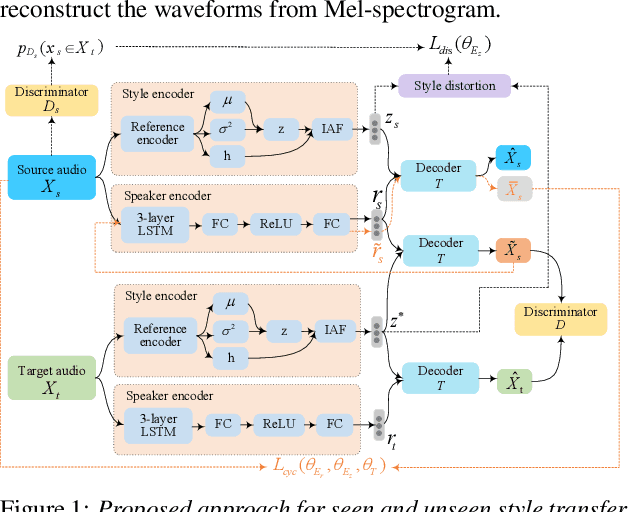
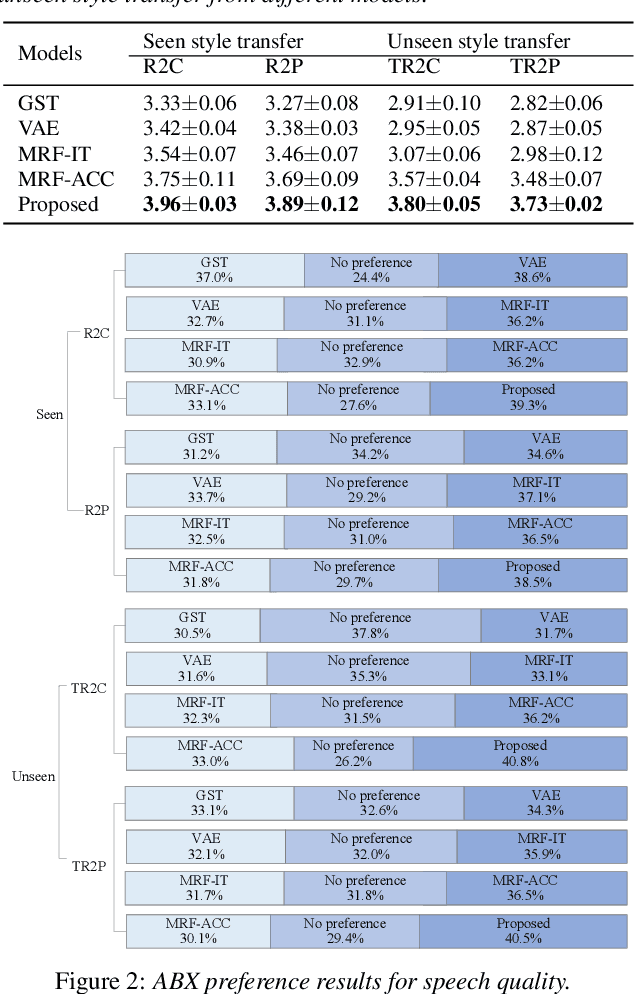
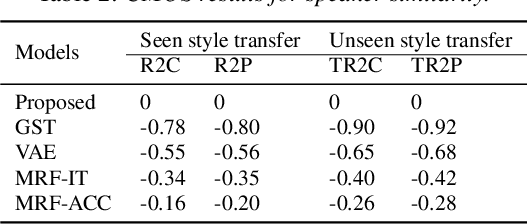

End-to-end neural TTS training has shown improved performance in speech style transfer. However, the improvement is still limited by the training data in both target styles and speakers. Inadequate style transfer performance occurs when the trained TTS tries to transfer the speech to a target style from a new speaker with an unknown, arbitrary style. In this paper, we propose a new approach to style transfer for both seen and unseen styles, with disjoint, multi-style datasets, i.e., datasets of different styles are recorded, each individual style is by one speaker with multiple utterances. To encode the style information, we adopt an inverse autoregressive flow (IAF) structure to improve the variational inference. The whole system is optimized to minimize a weighed sum of four different loss functions: 1) a reconstruction loss to measure the distortions in both source and target reconstructions; 2) an adversarial loss to "fool" a well-trained discriminator; 3) a style distortion loss to measure the expected style loss after the transfer; 4) a cycle consistency loss to preserve the speaker identity of the source after the transfer. Experiments demonstrate, both objectively and subjectively, the effectiveness of the proposed approach for seen and unseen style transfer tasks. The performance of the new approach is better and more robust than those of four baseline systems of the prior art.
Speech BERT Embedding For Improving Prosody in Neural TTS
Jun 15, 2021
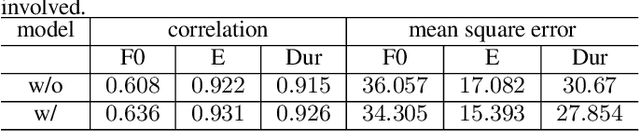
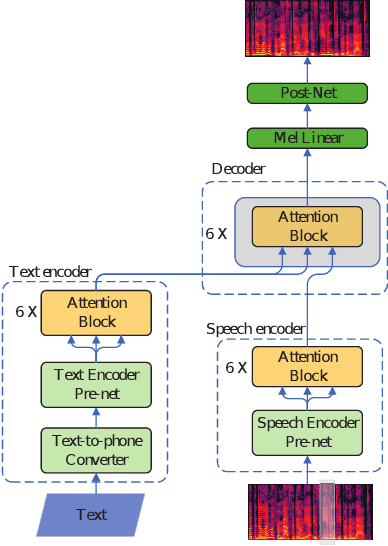
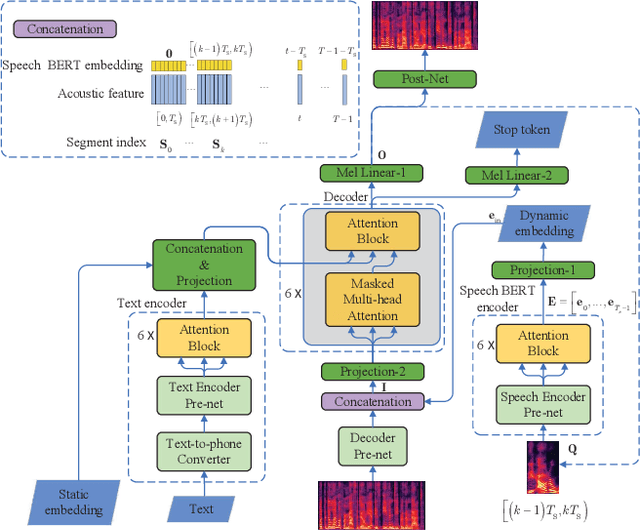
This paper presents a speech BERT model to extract embedded prosody information in speech segments for improving the prosody of synthesized speech in neural text-to-speech (TTS). As a pre-trained model, it can learn prosody attributes from a large amount of speech data, which can utilize more data than the original training data used by the target TTS. The embedding is extracted from the previous segment of a fixed length in the proposed BERT. The extracted embedding is then used together with the mel-spectrogram to predict the following segment in the TTS decoder. Experimental results obtained by the Transformer TTS show that the proposed BERT can extract fine-grained, segment-level prosody, which is complementary to utterance-level prosody to improve the final prosody of the TTS speech. The objective distortions measured on a single speaker TTS are reduced between the generated speech and original recordings. Subjective listening tests also show that the proposed approach is favorably preferred over the TTS without the BERT prosody embedding module, for both in-domain and out-of-domain applications. For Microsoft professional, single/multiple speakers and the LJ Speaker in the public database, subjective preference is similarly confirmed with the new BERT prosody embedding. TTS demo audio samples are in https://judy44chen.github.io/TTSSpeechBERT/.
Forward-Backward Decoding for Regularizing End-to-End TTS
Jul 18, 2019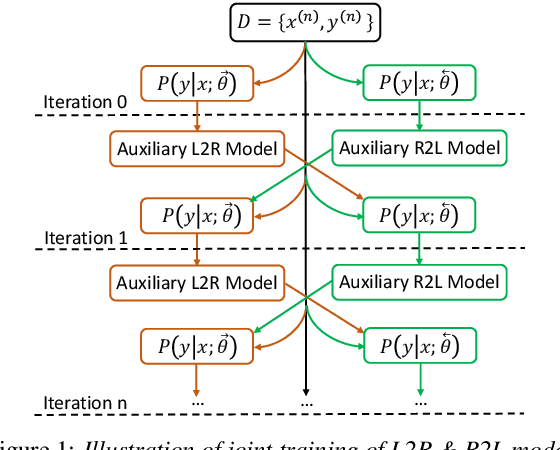
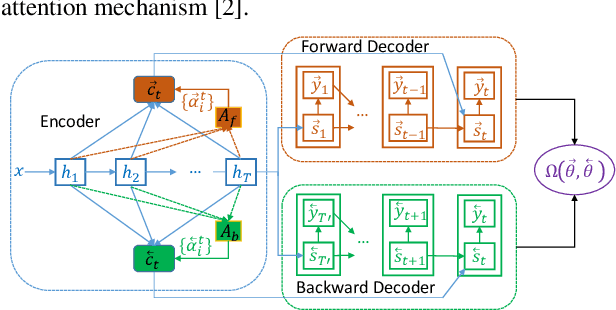
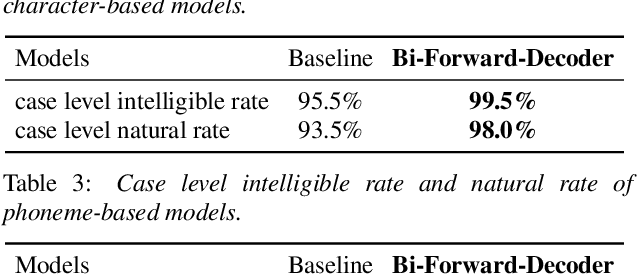

Neural end-to-end TTS can generate very high-quality synthesized speech, and even close to human recording within similar domain text. However, it performs unsatisfactory when scaling it to challenging test sets. One concern is that the encoder-decoder with attention-based network adopts autoregressive generative sequence model with the limitation of "exposure bias" To address this issue, we propose two novel methods, which learn to predict future by improving agreement between forward and backward decoding sequence. The first one is achieved by introducing divergence regularization terms into model training objective to reduce the mismatch between two directional models, namely L2R and R2L (which generates targets from left-to-right and right-to-left, respectively). While the second one operates on decoder-level and exploits the future information during decoding. In addition, we employ a joint training strategy to allow forward and backward decoding to improve each other in an interactive process. Experimental results show our proposed methods especially the second one (bidirectional decoder regularization), leads a significantly improvement on both robustness and overall naturalness, as outperforming baseline (the revised version of Tacotron2) with a MOS gap of 0.14 in a challenging test, and achieving close to human quality (4.42 vs. 4.49 in MOS) on general test.
A New GAN-based End-to-End TTS Training Algorithm
Apr 09, 2019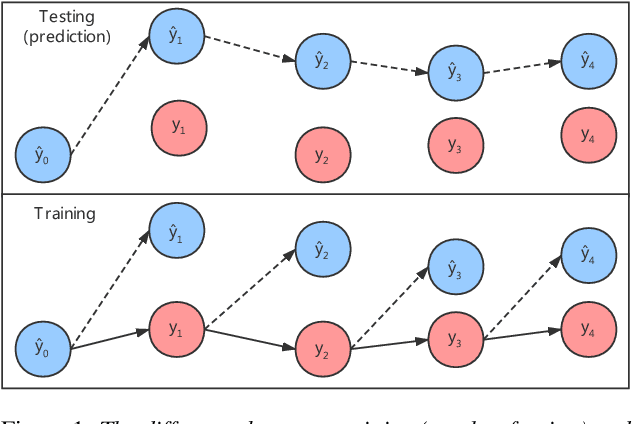
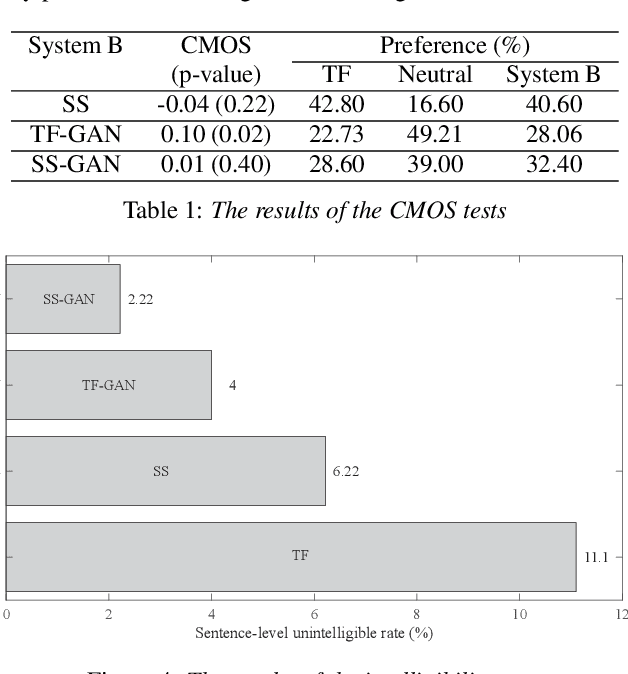
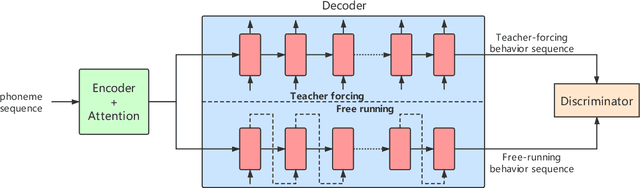
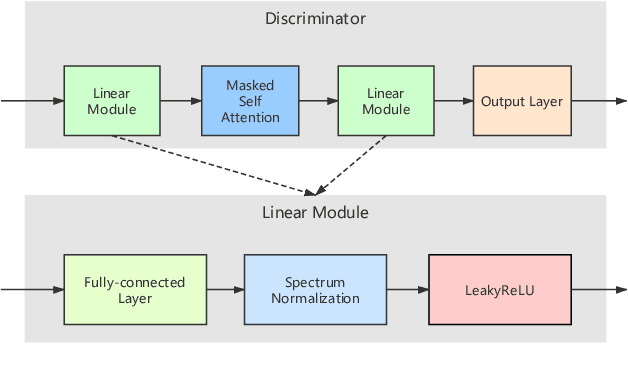
End-to-end, autoregressive model-based TTS has shown significant performance improvements over the conventional one. However, the autoregressive module training is affected by the exposure bias, or the mismatch between the different distributions of real and predicted data. While real data is available in training, but in testing, only predicted data is available to feed the autoregressive module. By introducing both real and generated data sequences in training, we can alleviate the effects of the exposure bias. We propose to use Generative Adversarial Network (GAN) along with the key idea of Professor Forcing in training. A discriminator in GAN is jointly trained to equalize the difference between real and predicted data. In AB subjective listening test, the results show that the new approach is preferred over the standard transfer learning with a CMOS improvement of 0.1. Sentence level intelligibility tests show significant improvement in a pathological test set. The GAN-trained new model is also more stable than the baseline to produce better alignments for the Tacotron output.
Exploiting Syntactic Features in a Parsed Tree to Improve End-to-End TTS
Apr 09, 2019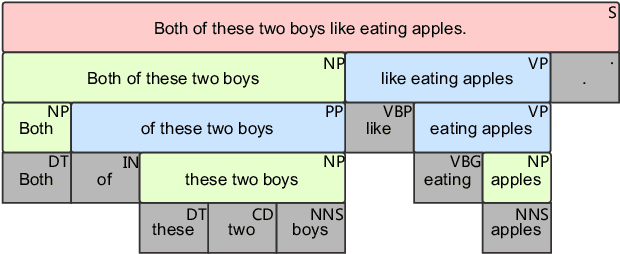
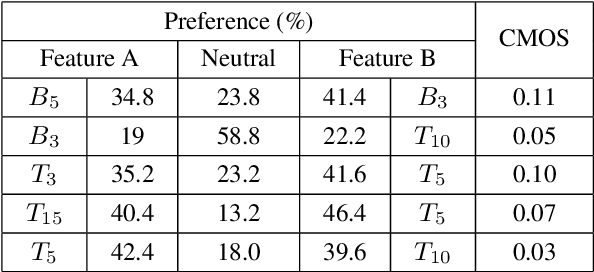


The end-to-end TTS, which can predict speech directly from a given sequence of graphemes or phonemes, has shown improved performance over the conventional TTS. However, its predicting capability is still limited by the acoustic/phonetic coverage of the training data, usually constrained by the training set size. To further improve the TTS quality in pronunciation, prosody and perceived naturalness, we propose to exploit the information embedded in a syntactically parsed tree where the inter-phrase/word information of a sentence is organized in a multilevel tree structure. Specifically, two key features: phrase structure and relations between adjacent words are investigated. Experimental results in subjective listening, measured on three test sets, show that the proposed approach is effective to improve the pronunciation clarity, prosody and naturalness of the synthesized speech of the baseline system.