 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge
Oct 19, 2021
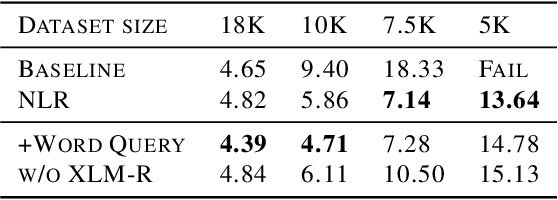
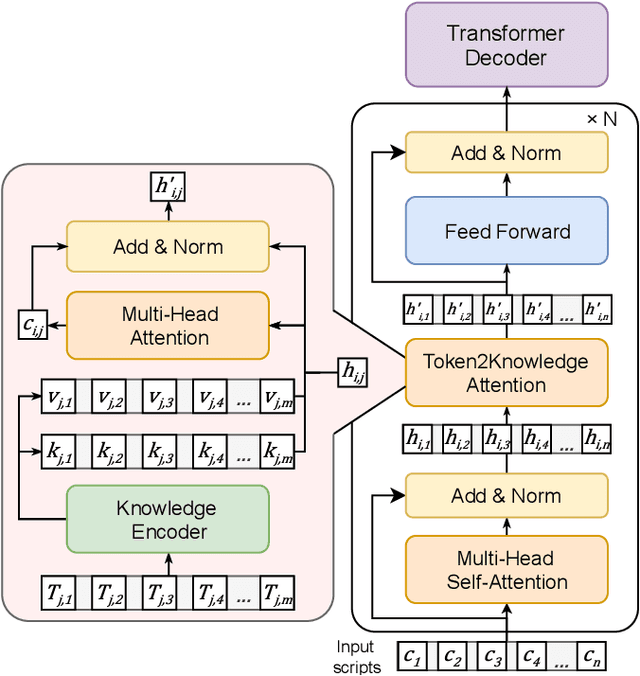
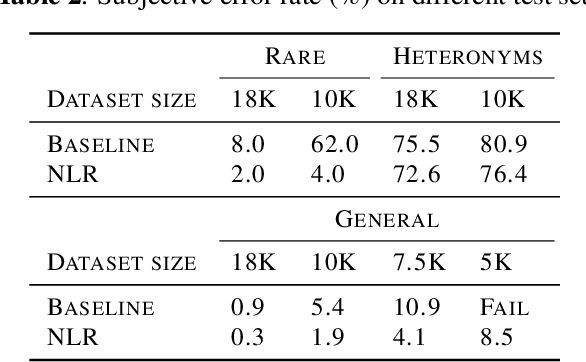
End-to-end TTS suffers from high data requirements as it is difficult for both costly speech corpora to cover all necessary knowledge and neural models to learn the knowledge, hence additional knowledge needs to be injected manually. For example, to capture pronunciation knowledge on languages without regular orthography, a complicated grapheme-to-phoneme pipeline needs to be built based on a structured, large pronunciation lexicon, leading to extra, sometimes high, costs to extend neural TTS to such languages. In this paper, we propose a framework to learn to extract knowledge from unstructured external resources using Token2Knowledge attention modules. The framework is applied to build a novel end-to-end TTS model named Neural Lexicon Reader that extracts pronunciations from raw lexicon texts. Experiments support the potential of our framework that the model significantly reduces pronunciation errors in low-resource, end-to-end Chinese TTS, and the lexicon-reading capability can be transferred to other languages with a smaller amount of data.
Multilingual Byte2Speech Text-To-Speech Models Are Few-shot Spoken Language Learners
Mar 05, 2021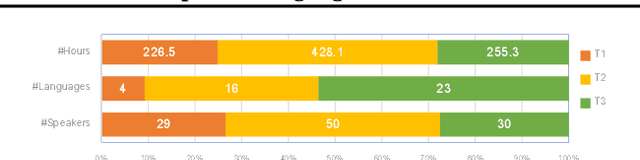

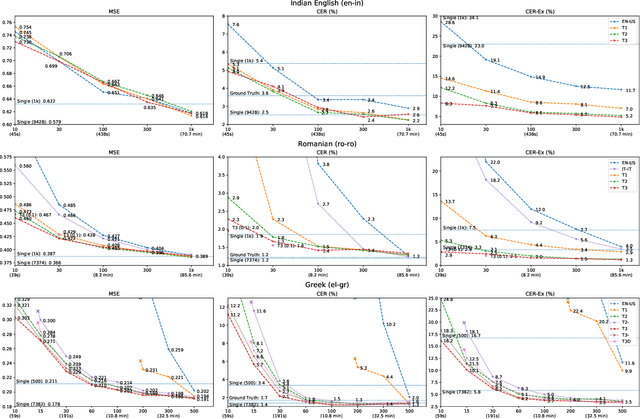

We present a multilingual end-to-end Text-To-Speech framework that maps byte inputs to spectrograms, thus allowing arbitrary input scripts. Besides strong results on 40+ languages, the framework demonstrates capabilities to adapt to various new languages under extreme low-resource and even few-shot scenarios of merely 40s transcribed recording without the need of lexicon, extra corpus, auxiliary models, or particular linguistic expertise, while retains satisfactory intelligibility and naturalness matching rich-resource models. Exhaustive comparative studies are performed to reveal the potential of the framework for low-resource application and the impact of various factors contributory to adaptation. Furthermore, we propose a novel method to extract language-specific sub-networks for a better understanding of the mechanism of multilingual models.