 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviating Forgetfulness of Linear Attention by Hybrid Sparse Attention and Contextualized Learnable Token Eviction
Oct 23, 2025Linear-attention models that compress the entire input sequence into a fixed-size recurrent state offer an efficient alternative to Transformers, but their finite memory induces forgetfulness that harms retrieval-intensive tasks. To mitigate the issue, we explore a series of hybrid models that restore direct access to past tokens. We interleave token mixers with intermediate time and space complexity between linear and full attention, including sparse attention with token eviction, and the query-aware native sparse attention. Particularly, we propose a novel learnable token eviction approach. Combined with sliding-window attention, an end-to-end trainable lightweight CNN aggregates information from both past and future adjacent tokens to adaptively retain a limited set of critical KV-pairs per head, maintaining linear attention's constant time and space complexity. Efficient Triton kernels for the sparse attention mechanisms are provided. Empirical evaluations on retrieval-intensive benchmarks support the effectiveness of our approaches.
DEL-Ranking: Ranking-Correction Denoising Framework for Elucidating Molecular Affinities in DNA-Encoded Libraries
Oct 19, 2024



DNA-encoded library (DEL) screening has revolutionized the detection of protein-ligand interactions through read counts, enabling rapid exploration of vast chemical spaces. However, noise in read counts, stemming from nonspecific interactions, can mislead this exploration process. We present DEL-Ranking, a novel distribution-correction denoising framework that addresses these challenges. Our approach introduces two key innovations: (1) a novel ranking loss that rectifies relative magnitude relationships between read counts, enabling the learning of causal features determining activity levels, and (2) an iterative algorithm employing self-training and consistency loss to establish model coherence between activity label and read count predictions. Furthermore, we contribute three new DEL screening datasets, the first to comprehensively include multi-dimensional molecular representations, protein-ligand enrichment values, and their activity labels. These datasets mitigate data scarcity issues in AI-driven DEL screening research. Rigorous evaluation on diverse DEL datasets demonstrates DEL-Ranking's superior performance across multiple correlation metrics, with significant improvements in binding affinity prediction accuracy. Our model exhibits zero-shot generalization ability across different protein targets and successfully identifies potential motifs determining compound binding affinity. This work advances DEL screening analysis and provides valuable resources for future research in this area.
Joint Fine-tuning and Conversion of Pretrained Speech and Language Models towards Linear Complexity
Oct 09, 2024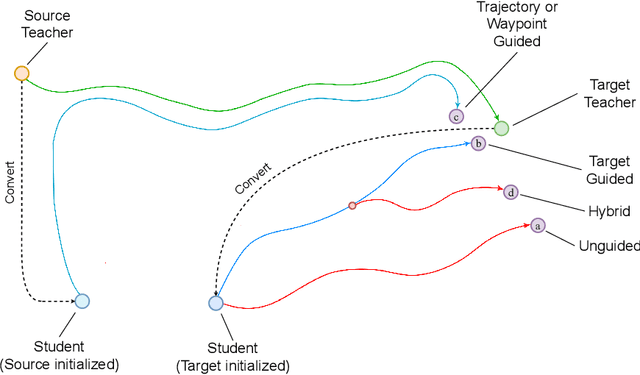
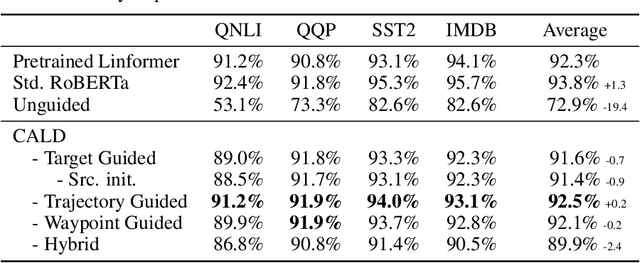
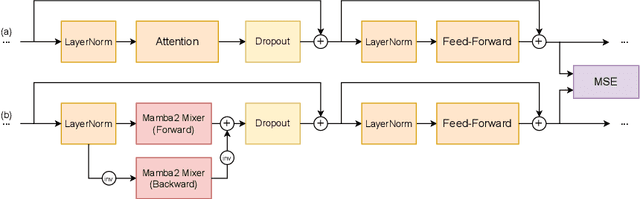
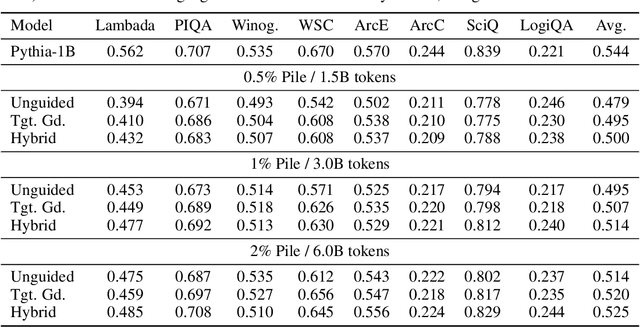
Architectures such as Linformer and Mamba have recently emerged as competitive linear time replacements for transformers. However, corresponding large pretrained models are often unavailable, especially in non-text domains. To remedy this, we present a Cross-Architecture Layerwise Distillation (CALD) approach that jointly converts a transformer model to a linear time substitute and fine-tunes it to a target task. We also compare several means to guide the fine-tuning to optimally retain the desired inference capability from the original model. The methods differ in their use of the target model and the trajectory of the parameters. In a series of empirical studies on language processing, language modeling, and speech processing, we show that CALD can effectively recover the result of the original model, and that the guiding strategy contributes to the result. Some reasons for the variation are suggested.
Unlocking Potential Binders: Multimodal Pretraining DEL-Fusion for Denoising DNA-Encoded Libraries
Sep 07, 2024



In the realm of drug discovery, DNA-encoded library (DEL) screening technology has emerged as an efficient method for identifying high-affinity compounds. However, DEL screening faces a significant challenge: noise arising from nonspecific interactions within complex biological systems. Neural networks trained on DEL libraries have been employed to extract compound features, aiming to denoise the data and uncover potential binders to the desired therapeutic target. Nevertheless, the inherent structure of DEL, constrained by the limited diversity of building blocks, impacts the performance of compound encoders. Moreover, existing methods only capture compound features at a single level, further limiting the effectiveness of the denoising strategy. To mitigate these issues, we propose a Multimodal Pretraining DEL-Fusion model (MPDF) that enhances encoder capabilities through pretraining and integrates compound features across various scales. We develop pretraining tasks applying contrastive objectives between different compound representations and their text descriptions, enhancing the compound encoders' ability to acquire generic features. Furthermore, we propose a novel DEL-fusion framework that amalgamates compound information at the atomic, submolecular, and molecular levels, as captured by various compound encoders. The synergy of these innovations equips MPDF with enriched, multi-scale features, enabling comprehensive downstream denoising. Evaluated on three DEL datasets, MPDF demonstrates superior performance in data processing and analysis for validation tasks. Notably, MPDF offers novel insights into identifying high-affinity molecules, paving the way for improved DEL utility in drug discovery.
Can ChatGPT Detect Intent? Evaluating Large Language Models for Spoken Language Understanding
May 22, 2023
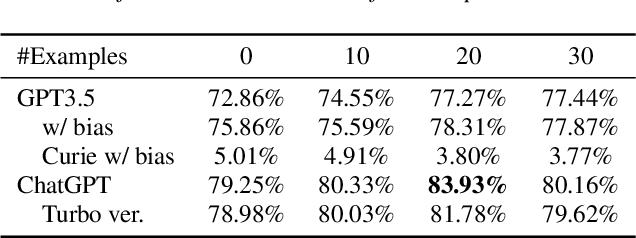
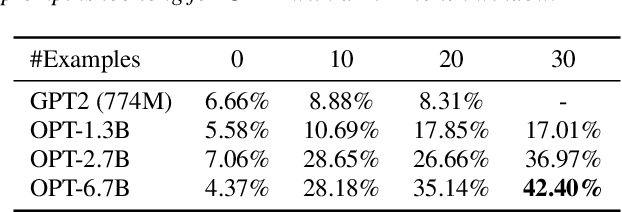
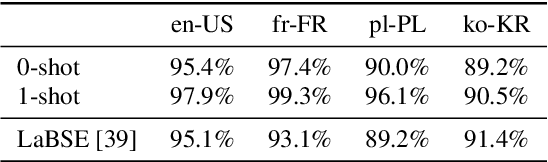
Recently, large pretrained language models have demonstrated strong language understanding capabilities. This is particularly reflected in their zero-shot and in-context learning abilities on downstream tasks through prompting. To assess their impact on spoken language understanding (SLU), we evaluate several such models like ChatGPT and OPT of different sizes on multiple benchmarks. We verify the emergent ability unique to the largest models as they can reach intent classification accuracy close to that of supervised models with zero or few shots on various languages given oracle transcripts. By contrast, the results for smaller models fitting a single GPU fall far behind. We note that the error cases often arise from the annotation scheme of the dataset; responses from ChatGPT are still reasonable. We show, however, that the model is worse at slot filling, and its performance is sensitive to ASR errors, suggesting serious challenges for the application of those textual models on SLU.
The Interpreter Understands Your Meaning: End-to-end Spoken Language Understanding Aided by Speech Translation
May 16, 2023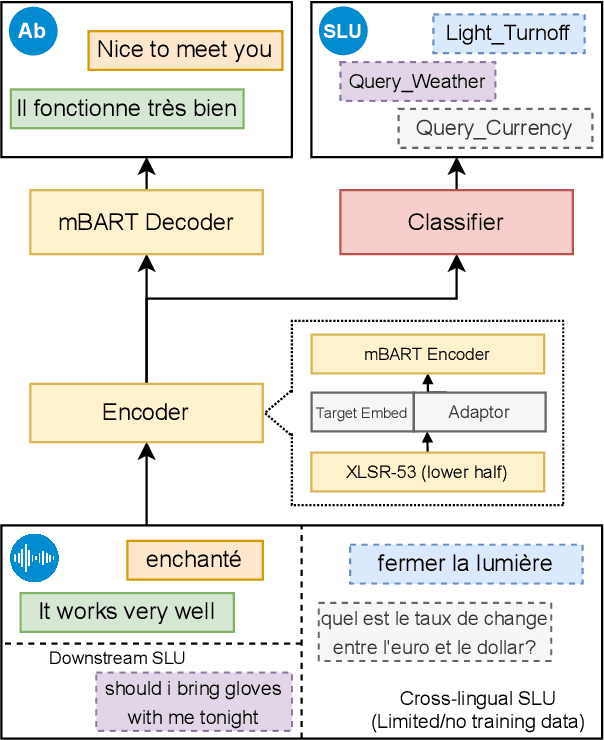
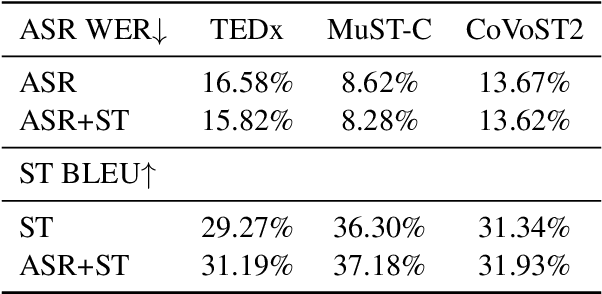
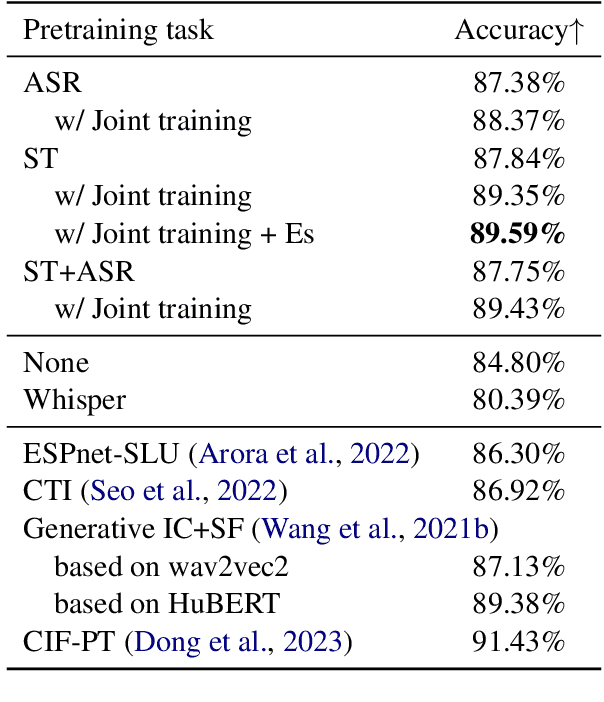
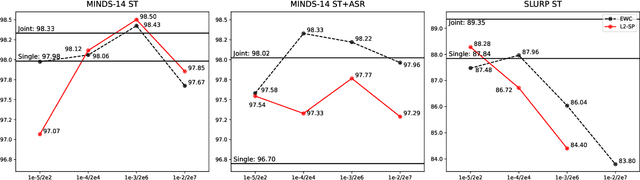
End-to-end spoken language understanding (SLU) remains elusive even with current large pretrained language models on text and speech, especially in multilingual cases. Machine translation has been established as a powerful pretraining objective on text as it enables the model to capture high-level semantics of the input utterance and associations between different languages, which is desired for speech models that work on lower-level acoustic frames. Motivated particularly by the task of cross-lingual SLU, we demonstrate that the task of speech translation (ST) is a good means of pretraining speech models for end-to-end SLU on both monolingual and cross-lingual scenarios. By introducing ST, our models give higher performance over current baselines on monolingual and multilingual intent classification as well as spoken question answering using SLURP, MINDS-14, and NMSQA benchmarks. To verify the effectiveness of our methods, we also release two new benchmark datasets from both synthetic and real sources, for the tasks of abstractive summarization from speech and low-resource or zero-shot transfer from English to French. We further show the value of preserving knowledge from the pretraining task, and explore Bayesian transfer learning on pretrained speech models based on continual learning regularizers for that.
Acquiring and Modelling Abstract Commonsense Knowledge via Conceptualization
Jun 03, 2022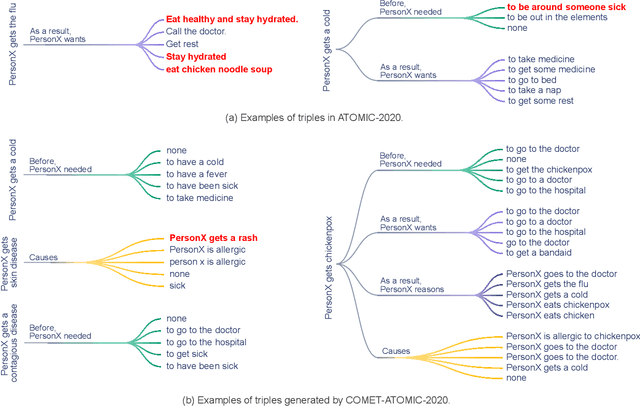

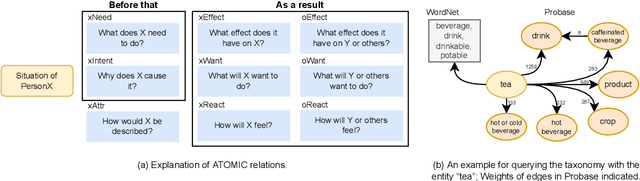
Conceptualization, or viewing entities and situations as instances of abstract concepts in mind and making inferences based on that, is a vital component in human intelligence for commonsense reasoning. Although recent artificial intelligence has made progress in acquiring and modelling commonsense, attributed to large neural language models and commonsense knowledge graphs (CKGs), conceptualization is yet to thoroughly be introduced, making current approaches ineffective to cover knowledge about countless diverse entities and situations in the real world. To address the problem, we thoroughly study the possible role of conceptualization in commonsense reasoning, and formulate a framework to replicate human conceptual induction from acquiring abstract knowledge about abstract concepts. Aided by the taxonomy Probase, we develop tools for contextualized conceptualization on ATOMIC, a large-scale human annotated CKG. We annotate a dataset for the validity of conceptualizations for ATOMIC on both event and triple level, develop a series of heuristic rules based on linguistic features, and train a set of neural models, so as to generate and verify abstract knowledge. Based on these components, a pipeline to acquire abstract knowledge is built. A large abstract CKG upon ATOMIC is then induced, ready to be instantiated to infer about unseen entities or situations. Furthermore, experiments find directly augmenting data with abstract triples to be helpful in commonsense modelling.
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge
Oct 19, 2021
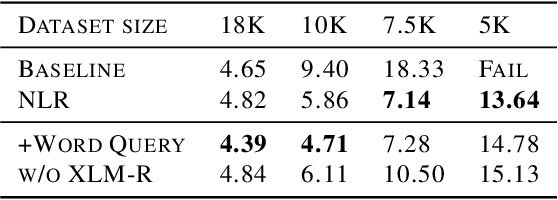
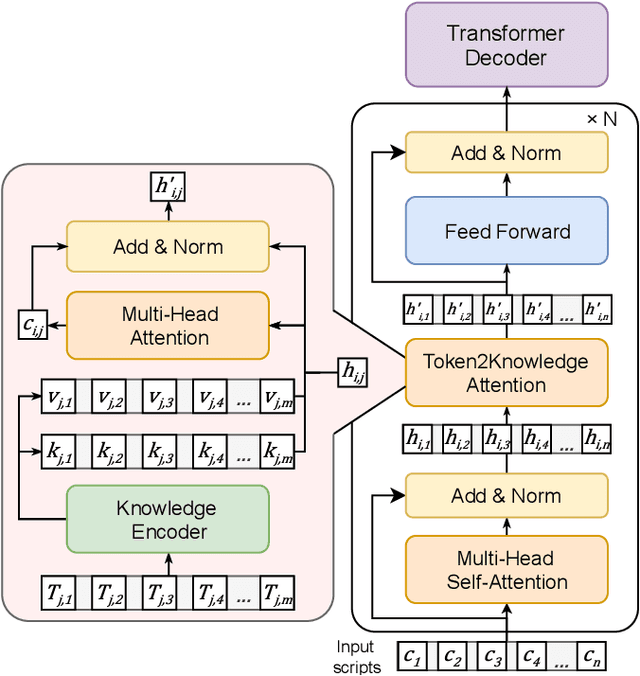
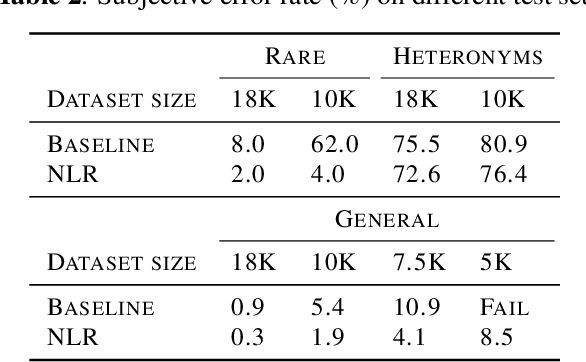
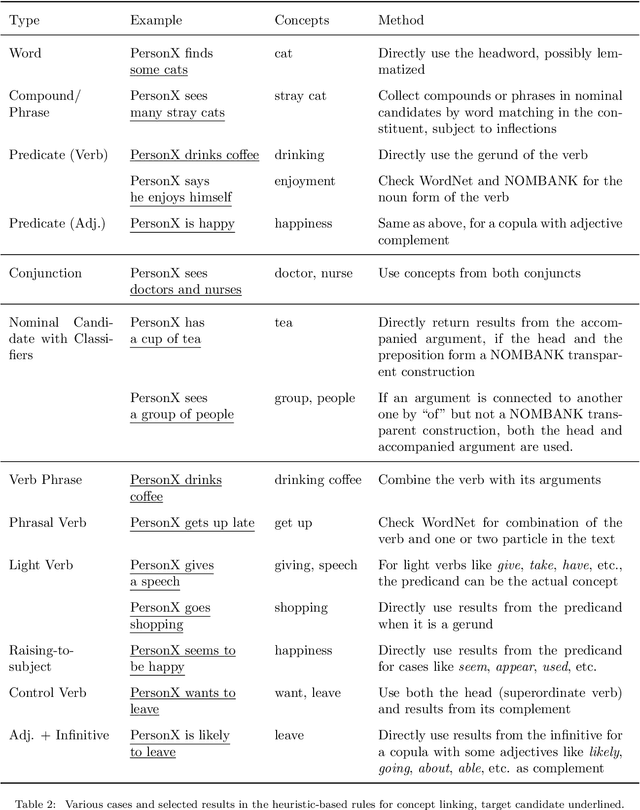
End-to-end TTS suffers from high data requirements as it is difficult for both costly speech corpora to cover all necessary knowledge and neural models to learn the knowledge, hence additional knowledge needs to be injected manually. For example, to capture pronunciation knowledge on languages without regular orthography, a complicated grapheme-to-phoneme pipeline needs to be built based on a structured, large pronunciation lexicon, leading to extra, sometimes high, costs to extend neural TTS to such languages. In this paper, we propose a framework to learn to extract knowledge from unstructured external resources using Token2Knowledge attention modules. The framework is applied to build a novel end-to-end TTS model named Neural Lexicon Reader that extracts pronunciations from raw lexicon texts. Experiments support the potential of our framework that the model significantly reduces pronunciation errors in low-resource, end-to-end Chinese TTS, and the lexicon-reading capability can be transferred to other languages with a smaller amount of data.
Multilingual Byte2Speech Text-To-Speech Models Are Few-shot Spoken Language Learners
Mar 05, 2021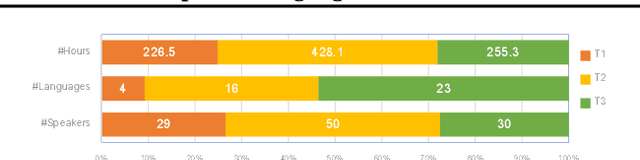

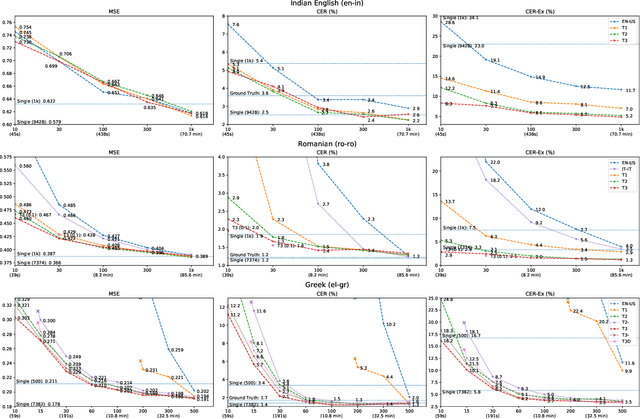

We present a multilingual end-to-end Text-To-Speech framework that maps byte inputs to spectrograms, thus allowing arbitrary input scripts. Besides strong results on 40+ languages, the framework demonstrates capabilities to adapt to various new languages under extreme low-resource and even few-shot scenarios of merely 40s transcribed recording without the need of lexicon, extra corpus, auxiliary models, or particular linguistic expertise, while retains satisfactory intelligibility and naturalness matching rich-resource models. Exhaustive comparative studies are performed to reveal the potential of the framework for low-resource application and the impact of various factors contributory to adaptation. Furthermore, we propose a novel method to extract language-specific sub-networks for a better understanding of the mechanism of multilingual models.
On the Role of Conceptualization in Commonsense Knowledge Graph Construction
Apr 07, 2020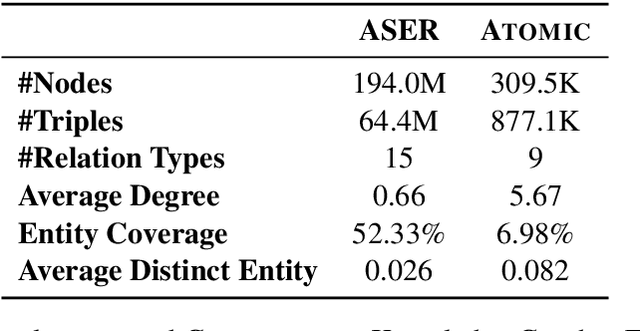

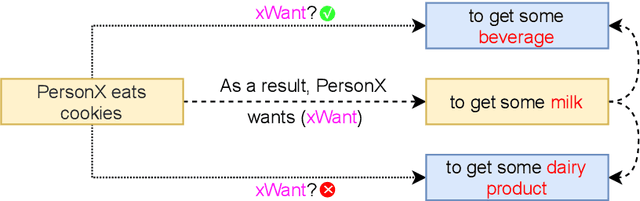
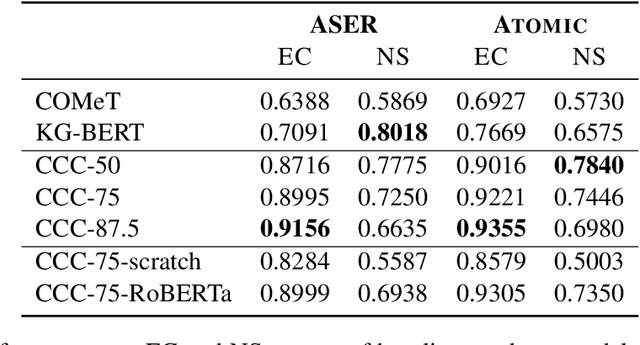
Commonsense knowledge graphs (CKGs) like Atomic and ASER are substantially different from conventional KGs as they consist of much larger number of nodes formed by loosely-structured text, which, though, enables them to handle highly diverse queries in natural language related to commonsense, leads to unique challenges for automatic KG construction methods. Besides identifying relations absent from the KG between nodes, such methods are also expected to explore absent nodes represented by text, in which different real-world things, or entities, may appear. To deal with the innumerable entities involved with commonsense in the real world, we introduce to CKG construction methods conceptualization, i.e., to view entities mentioned in text as instances of specific concepts or vice versa. We build synthetic triples by conceptualization, and further formulate the task as triple classification, handled by a discriminatory model with knowledge transferred from pretrained language models and fine-tuned by negative sampling. Experiments demonstrate that our methods can effectively identify plausible triples and expand the KG by triples of both new nodes and edges of high diversity and novelty.