 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan ChatGPT Detect Intent? Evaluating Large Language Models for Spoken Language Understanding
Paper and Code

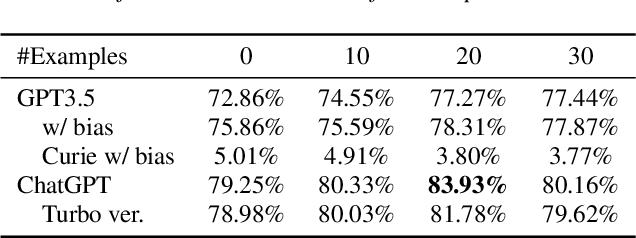
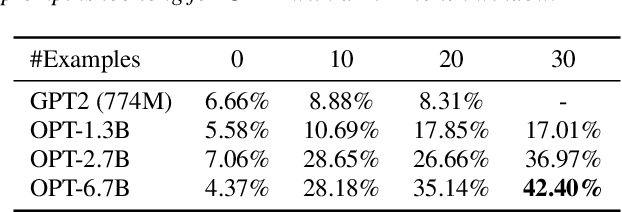
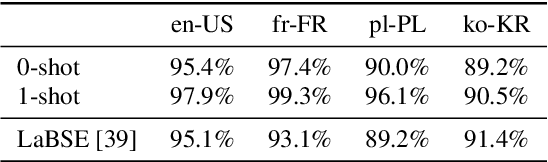
Recently, large pretrained language models have demonstrated strong language understanding capabilities. This is particularly reflected in their zero-shot and in-context learning abilities on downstream tasks through prompting. To assess their impact on spoken language understanding (SLU), we evaluate several such models like ChatGPT and OPT of different sizes on multiple benchmarks. We verify the emergent ability unique to the largest models as they can reach intent classification accuracy close to that of supervised models with zero or few shots on various languages given oracle transcripts. By contrast, the results for smaller models fitting a single GPU fall far behind. We note that the error cases often arise from the annotation scheme of the dataset; responses from ChatGPT are still reasonable. We show, however, that the model is worse at slot filling, and its performance is sensitive to ASR errors, suggesting serious challenges for the application of those textual models on SLU.