 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviating Forgetfulness of Linear Attention by Hybrid Sparse Attention and Contextualized Learnable Token Eviction
Oct 23, 2025Linear-attention models that compress the entire input sequence into a fixed-size recurrent state offer an efficient alternative to Transformers, but their finite memory induces forgetfulness that harms retrieval-intensive tasks. To mitigate the issue, we explore a series of hybrid models that restore direct access to past tokens. We interleave token mixers with intermediate time and space complexity between linear and full attention, including sparse attention with token eviction, and the query-aware native sparse attention. Particularly, we propose a novel learnable token eviction approach. Combined with sliding-window attention, an end-to-end trainable lightweight CNN aggregates information from both past and future adjacent tokens to adaptively retain a limited set of critical KV-pairs per head, maintaining linear attention's constant time and space complexity. Efficient Triton kernels for the sparse attention mechanisms are provided. Empirical evaluations on retrieval-intensive benchmarks support the effectiveness of our approaches.
Joint Fine-tuning and Conversion of Pretrained Speech and Language Models towards Linear Complexity
Oct 09, 2024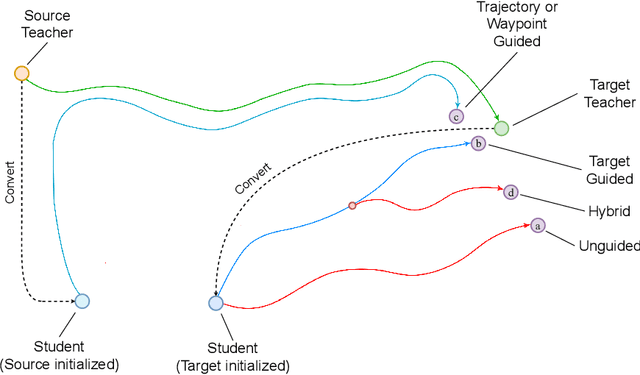
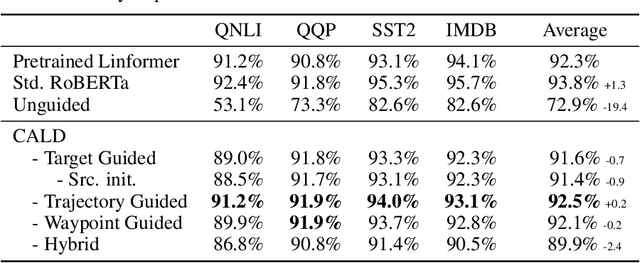
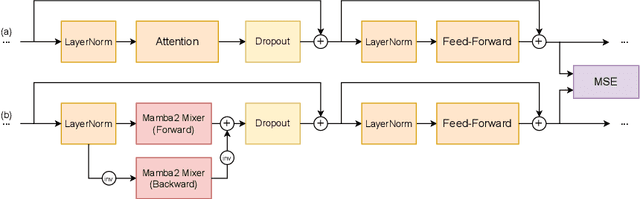
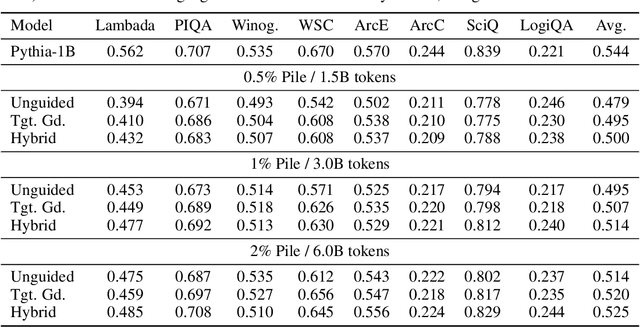
Architectures such as Linformer and Mamba have recently emerged as competitive linear time replacements for transformers. However, corresponding large pretrained models are often unavailable, especially in non-text domains. To remedy this, we present a Cross-Architecture Layerwise Distillation (CALD) approach that jointly converts a transformer model to a linear time substitute and fine-tunes it to a target task. We also compare several means to guide the fine-tuning to optimally retain the desired inference capability from the original model. The methods differ in their use of the target model and the trajectory of the parameters. In a series of empirical studies on language processing, language modeling, and speech processing, we show that CALD can effectively recover the result of the original model, and that the guiding strategy contributes to the result. Some reasons for the variation are suggested.
A Bayesian Interpretation of Adaptive Low-Rank Adaptation
Sep 16, 2024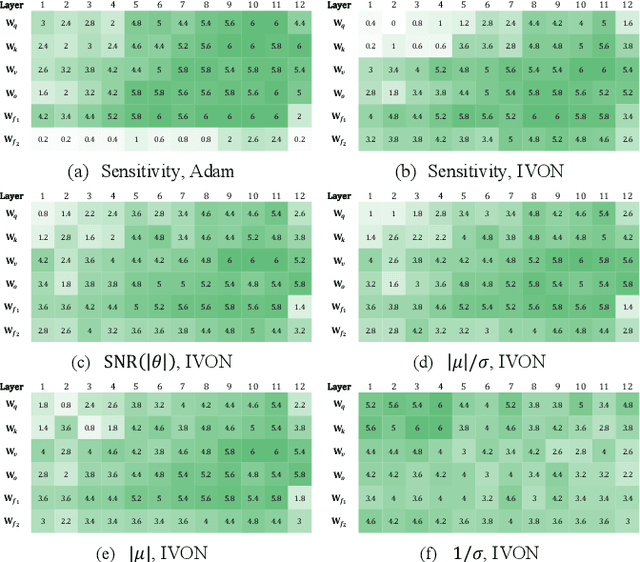
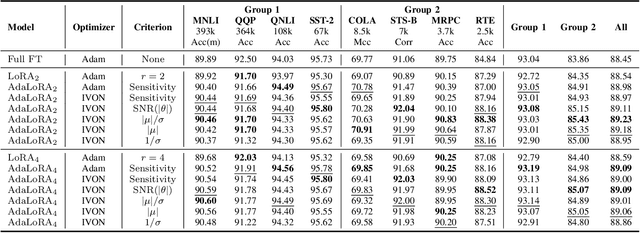
Motivated by the sensitivity-based importance score of the adaptive low-rank adaptation (AdaLoRA), we utilize more theoretically supported metrics, including the signal-to-noise ratio (SNR), along with the Improved Variational Online Newton (IVON) optimizer, for adaptive parameter budget allocation. The resulting Bayesian counterpart not only has matched or surpassed the performance of using the sensitivity-based importance metric but is also a faster alternative to AdaLoRA with Adam. Our theoretical analysis reveals a significant connection between the two metrics, providing a Bayesian perspective on the efficacy of sensitivity as an importance score. Furthermore, our findings suggest that the magnitude, rather than the variance, is the primary indicator of the importance of parameters.
An investigation of modularity for noise robustness in conformer-based ASR
Sep 09, 2024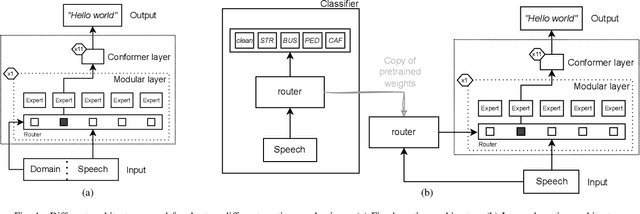
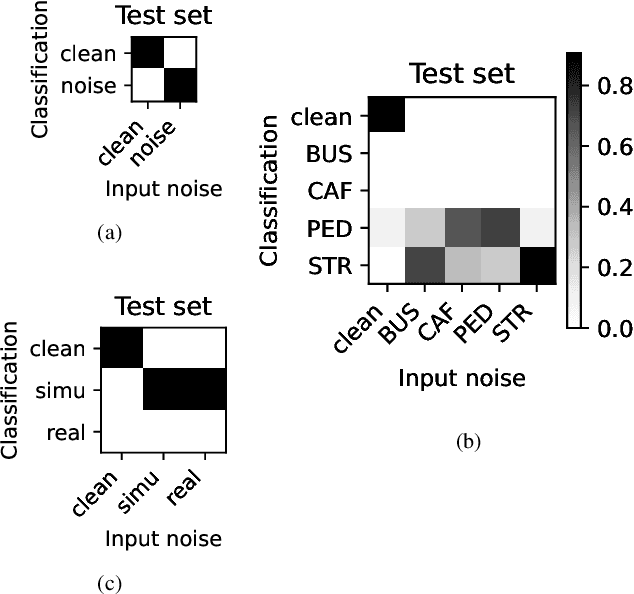


Whilst state of the art automatic speech recognition (ASR) can perform well, it still degrades when exposed to acoustic environments that differ from those used when training the model. Unfamiliar environments for a given model may well be known a-priori, but yield comparatively small amounts of adaptation data. In this experimental study, we investigate to what extent recent formalisations of modularity can aid adaptation of ASR to new acoustic environments. Using a conformer based model and fixed routing, we confirm that environment awareness can indeed lead to improved performance in known environments. However, at least on the (CHIME) datasets in the study, it is difficult for a classifier module to distinguish different noisy environments, a simpler distinction between noisy and clean speech being the optimal configuration. The results have clear implications for deploying large models in particular environments with or without a-priori knowledge of the environmental noise.
Exploring neural oscillations during speech perception via surrogate gradient spiking neural networks
Apr 22, 2024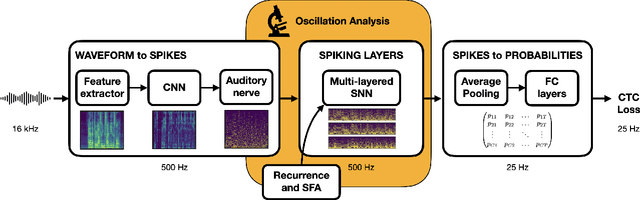
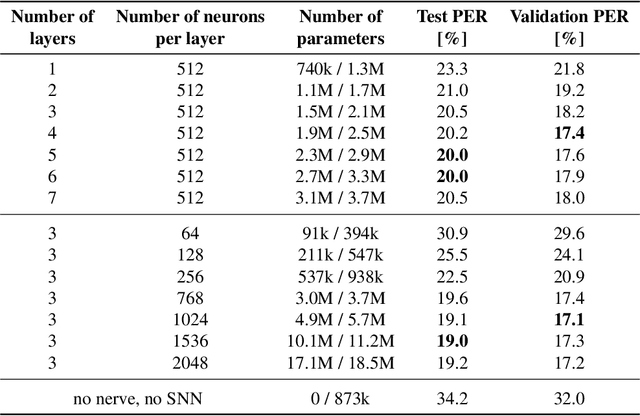

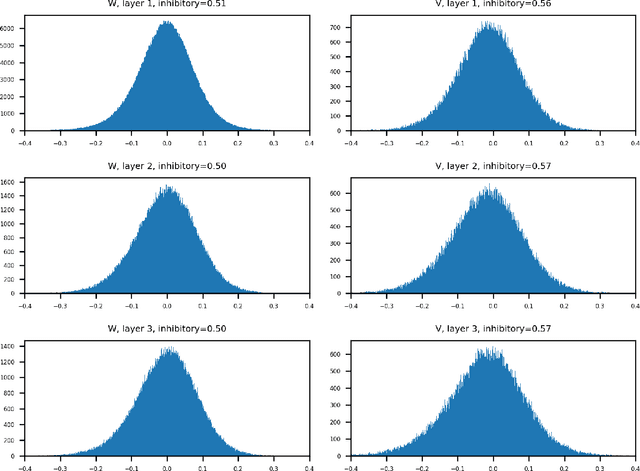
Understanding cognitive processes in the brain demands sophisticated models capable of replicating neural dynamics at large scales. We present a physiologically inspired speech recognition architecture, compatible and scalable with deep learning frameworks, and demonstrate that end-to-end gradient descent training leads to the emergence of neural oscillations in the central spiking neural network. Significant cross-frequency couplings, indicative of these oscillations, are measured within and across network layers during speech processing, whereas no such interactions are observed when handling background noise inputs. Furthermore, our findings highlight the crucial inhibitory role of feedback mechanisms, such as spike frequency adaptation and recurrent connections, in regulating and synchronising neural activity to improve recognition performance. Overall, on top of developing our understanding of synchronisation phenomena notably observed in the human auditory pathway, our architecture exhibits dynamic and efficient information processing, with relevance to neuromorphic technology.
Bayesian Parameter-Efficient Fine-Tuning for Overcoming Catastrophic Forgetting
Feb 19, 2024Although motivated by the adaptation of text-to-speech synthesis models, we argue that more generic parameter-efficient fine-tuning (PEFT) is an appropriate framework to do such adaptation. However, catastrophic forgetting remains an issue with PEFT, damaging the pre-trained model's inherent capabilities. We demonstrate that existing Bayesian learning techniques can be applied to PEFT to prevent catastrophic forgetting as long as the parameter shift of the fine-tuned layers can be calculated differentiably. In a principled series of experiments on language modeling and speech synthesis tasks, we utilize established Laplace approximations, including diagonal and Kronecker factored approaches, to regularize PEFT with the low-rank adaptation (LoRA) and compare their performance in pre-training knowledge preservation. Our results demonstrate that catastrophic forgetting can be overcome by our methods without degrading the fine-tuning performance, and using the Kronecker factored approximations produces a better preservation of the pre-training knowledge than the diagonal ones.
Vulnerability of Automatic Identity Recognition to Audio-Visual Deepfakes
Nov 29, 2023The task of deepfakes detection is far from being solved by speech or vision researchers. Several publicly available databases of fake synthetic video and speech were built to aid the development of detection methods. However, existing databases typically focus on visual or voice modalities and provide no proof that their deepfakes can in fact impersonate any real person. In this paper, we present the first realistic audio-visual database of deepfakes SWAN-DF, where lips and speech are well synchronized and video have high visual and audio qualities. We took the publicly available SWAN dataset of real videos with different identities to create audio-visual deepfakes using several models from DeepFaceLab and blending techniques for face swapping and HiFiVC, DiffVC, YourTTS, and FreeVC models for voice conversion. From the publicly available speech dataset LibriTTS, we also created a separate database of only audio deepfakes LibriTTS-DF using several latest text to speech methods: YourTTS, Adaspeech, and TorToiSe. We demonstrate the vulnerability of a state of the art speaker recognition system, such as ECAPA-TDNN-based model from SpeechBrain, to the synthetic voices. Similarly, we tested face recognition system based on the MobileFaceNet architecture to several variants of our visual deepfakes. The vulnerability assessment show that by tuning the existing pretrained deepfake models to specific identities, one can successfully spoof the face and speaker recognition systems in more than 90% of the time and achieve a very realistic looking and sounding fake video of a given person.
Can ChatGPT Detect Intent? Evaluating Large Language Models for Spoken Language Understanding
May 22, 2023
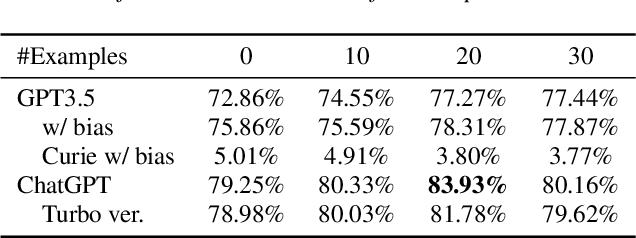
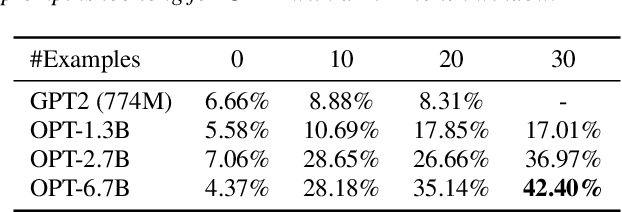
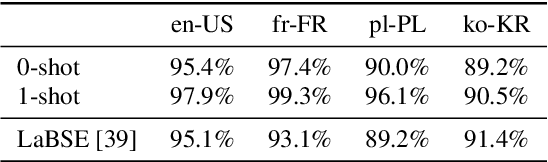
Recently, large pretrained language models have demonstrated strong language understanding capabilities. This is particularly reflected in their zero-shot and in-context learning abilities on downstream tasks through prompting. To assess their impact on spoken language understanding (SLU), we evaluate several such models like ChatGPT and OPT of different sizes on multiple benchmarks. We verify the emergent ability unique to the largest models as they can reach intent classification accuracy close to that of supervised models with zero or few shots on various languages given oracle transcripts. By contrast, the results for smaller models fitting a single GPU fall far behind. We note that the error cases often arise from the annotation scheme of the dataset; responses from ChatGPT are still reasonable. We show, however, that the model is worse at slot filling, and its performance is sensitive to ASR errors, suggesting serious challenges for the application of those textual models on SLU.
The Interpreter Understands Your Meaning: End-to-end Spoken Language Understanding Aided by Speech Translation
May 16, 2023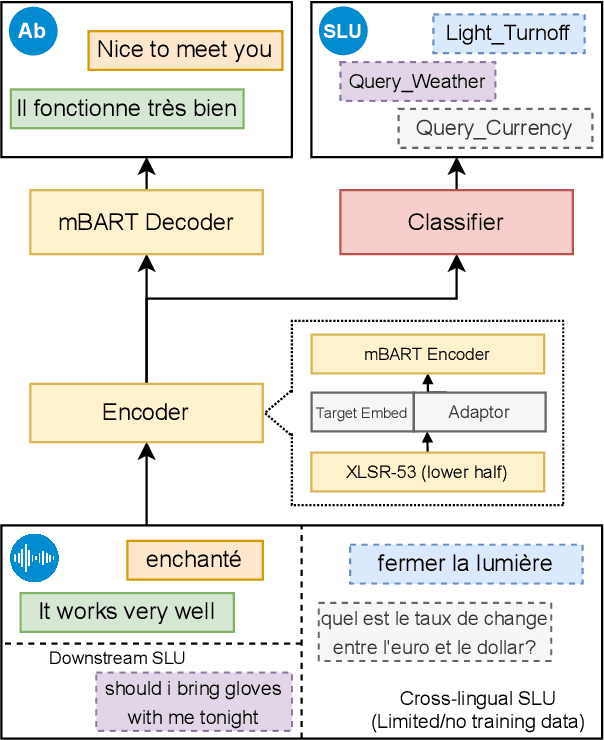
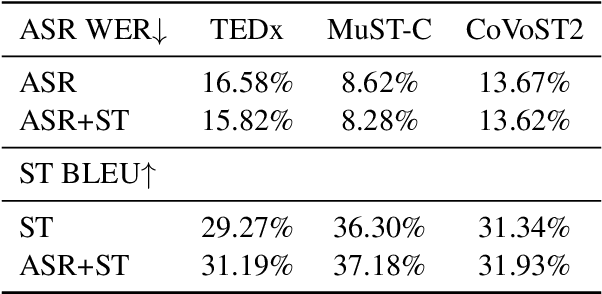
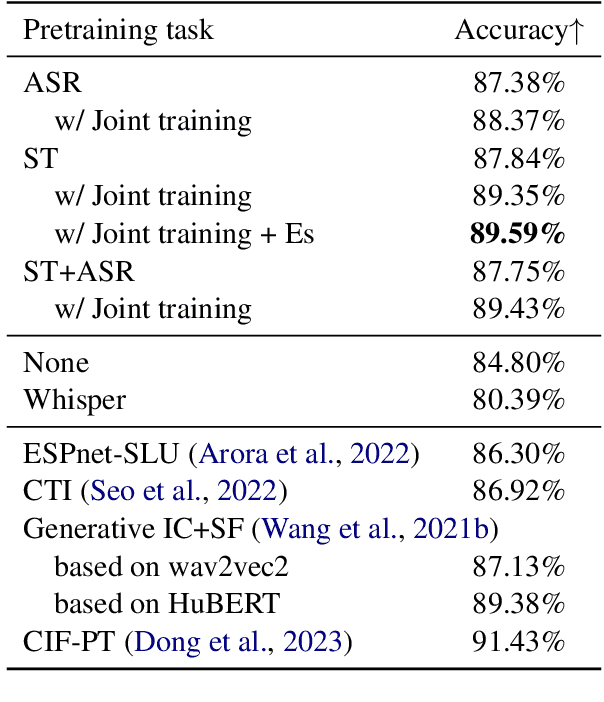
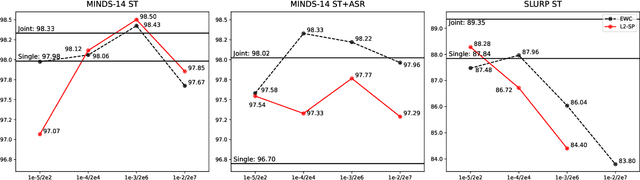
End-to-end spoken language understanding (SLU) remains elusive even with current large pretrained language models on text and speech, especially in multilingual cases. Machine translation has been established as a powerful pretraining objective on text as it enables the model to capture high-level semantics of the input utterance and associations between different languages, which is desired for speech models that work on lower-level acoustic frames. Motivated particularly by the task of cross-lingual SLU, we demonstrate that the task of speech translation (ST) is a good means of pretraining speech models for end-to-end SLU on both monolingual and cross-lingual scenarios. By introducing ST, our models give higher performance over current baselines on monolingual and multilingual intent classification as well as spoken question answering using SLURP, MINDS-14, and NMSQA benchmarks. To verify the effectiveness of our methods, we also release two new benchmark datasets from both synthetic and real sources, for the tasks of abstractive summarization from speech and low-resource or zero-shot transfer from English to French. We further show the value of preserving knowledge from the pretraining task, and explore Bayesian transfer learning on pretrained speech models based on continual learning regularizers for that.
An investigation into the adaptability of a diffusion-based TTS model
Mar 03, 2023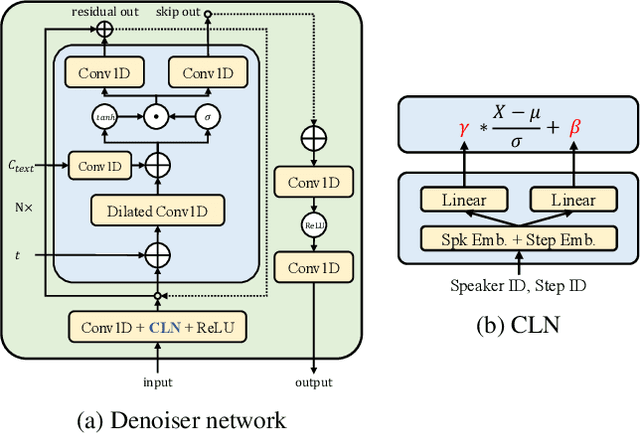
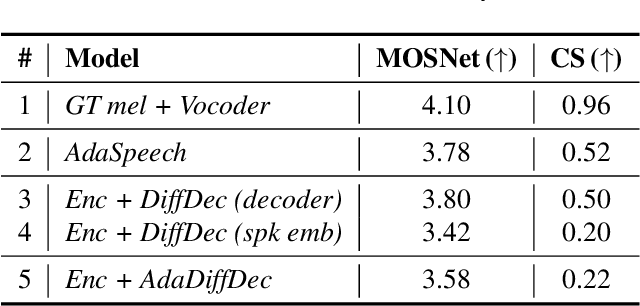
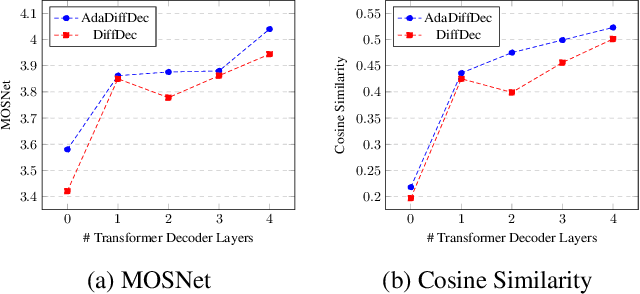
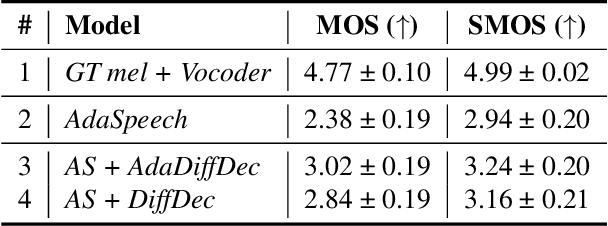
Given the recent success of diffusion in producing natural-sounding synthetic speech, we investigate how diffusion can be used in speaker adaptive TTS. Taking cues from more traditional adaptation approaches, we show that adaptation can be included in a diffusion pipeline using conditional layer normalization with a step embedding. However, we show experimentally that, whilst the approach has merit, such adaptation alone cannot approach the performance of Transformer-based techniques. In a second experiment, we show that diffusion can be optimally combined with Transformer, with the latter taking the bulk of the adaptation load and the former contributing to improved naturalness.