Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn investigation into the adaptability of a diffusion-based TTS model
Paper and Code
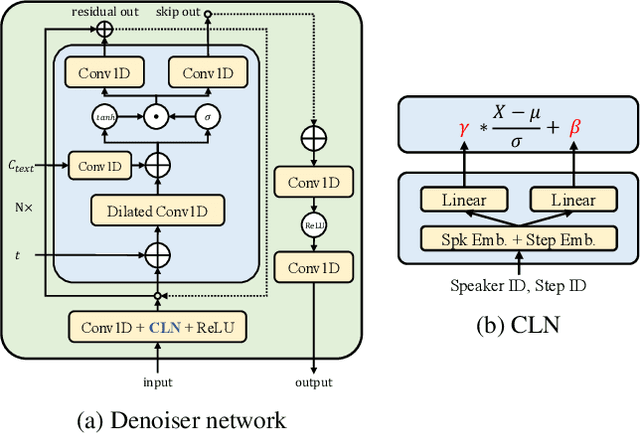
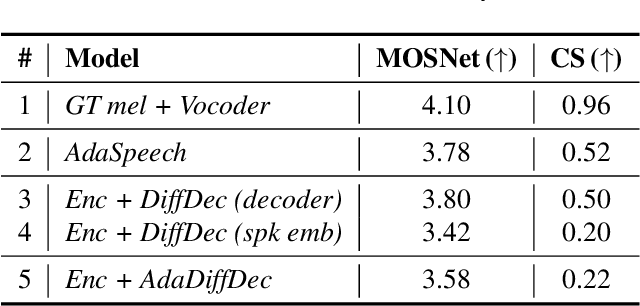
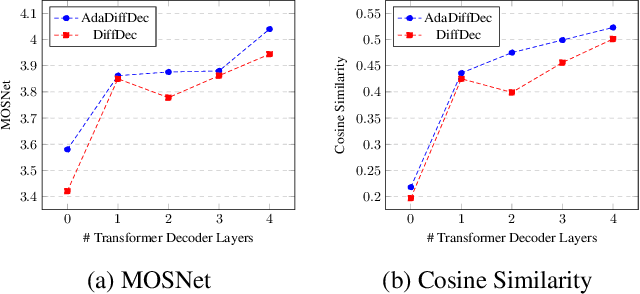
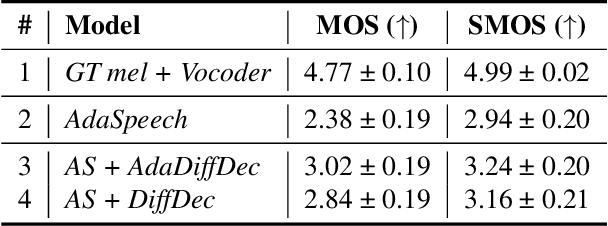
Given the recent success of diffusion in producing natural-sounding synthetic speech, we investigate how diffusion can be used in speaker adaptive TTS. Taking cues from more traditional adaptation approaches, we show that adaptation can be included in a diffusion pipeline using conditional layer normalization with a step embedding. However, we show experimentally that, whilst the approach has merit, such adaptation alone cannot approach the performance of Transformer-based techniques. In a second experiment, we show that diffusion can be optimally combined with Transformer, with the latter taking the bulk of the adaptation load and the former contributing to improved naturalness.
View paper on