 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Interpreter Understands Your Meaning: End-to-end Spoken Language Understanding Aided by Speech Translation
Paper and Code
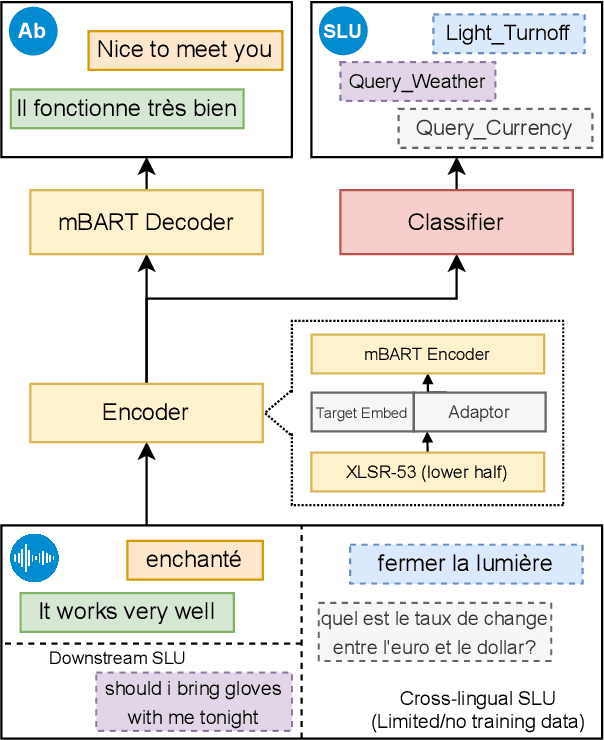
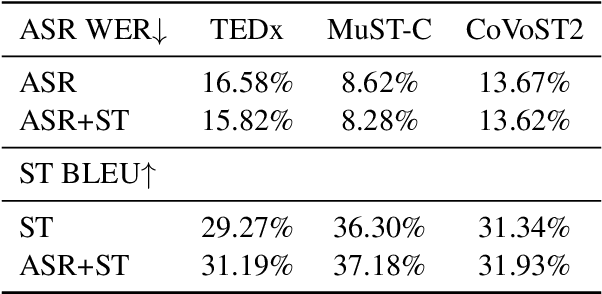
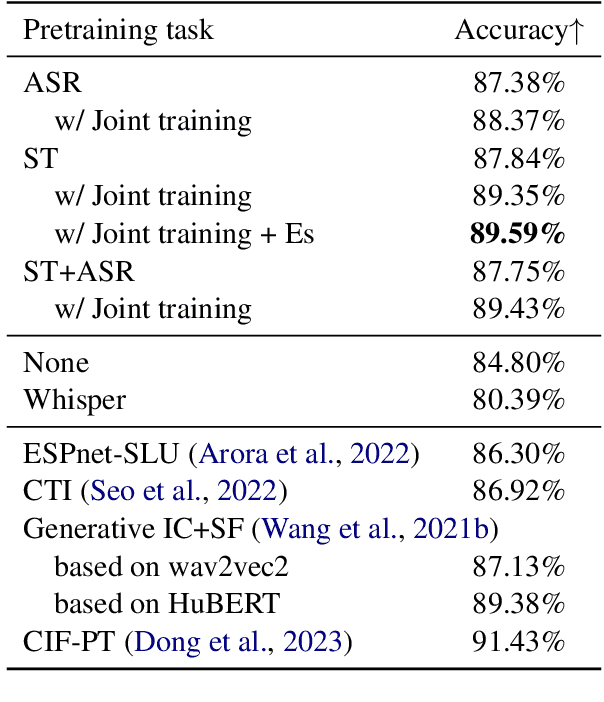
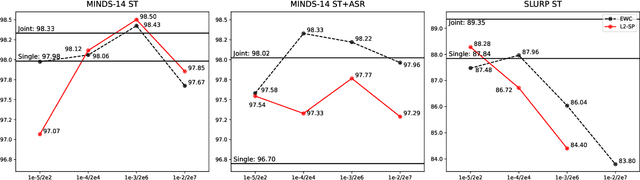
End-to-end spoken language understanding (SLU) remains elusive even with current large pretrained language models on text and speech, especially in multilingual cases. Machine translation has been established as a powerful pretraining objective on text as it enables the model to capture high-level semantics of the input utterance and associations between different languages, which is desired for speech models that work on lower-level acoustic frames. Motivated particularly by the task of cross-lingual SLU, we demonstrate that the task of speech translation (ST) is a good means of pretraining speech models for end-to-end SLU on both monolingual and cross-lingual scenarios. By introducing ST, our models give higher performance over current baselines on monolingual and multilingual intent classification as well as spoken question answering using SLURP, MINDS-14, and NMSQA benchmarks. To verify the effectiveness of our methods, we also release two new benchmark datasets from both synthetic and real sources, for the tasks of abstractive summarization from speech and low-resource or zero-shot transfer from English to French. We further show the value of preserving knowledge from the pretraining task, and explore Bayesian transfer learning on pretrained speech models based on continual learning regularizers for that.