 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Preserving Aging and De-Aging of Faces in the StyleGAN Latent Space
Aug 12, 2025Face aging or de-aging with generative AI has gained significant attention for its applications in such fields like forensics, security, and media. However, most state of the art methods rely on conditional Generative Adversarial Networks (GANs), Diffusion-based models, or Visual Language Models (VLMs) to age or de-age faces based on predefined age categories and conditioning via loss functions, fine-tuning, or text prompts. The reliance on such conditioning leads to complex training requirements, increased data needs, and challenges in generating consistent results. Additionally, identity preservation is rarely taken into accountor evaluated on a single face recognition system without any control or guarantees on whether identity would be preserved in a generated aged/de-aged face. In this paper, we propose to synthesize aged and de-aged faces via editing latent space of StyleGAN2 using a simple support vector modeling of aging/de-aging direction and several feature selection approaches. By using two state-of-the-art face recognition systems, we empirically find the identity preserving subspace within the StyleGAN2 latent space, so that an apparent age of a given face can changed while preserving the identity. We then propose a simple yet practical formula for estimating the limits on aging/de-aging parameters that ensures identity preservation for a given input face. Using our method and estimated parameters we have generated a public dataset of synthetic faces at different ages that can be used for benchmarking cross-age face recognition, age assurance systems, or systems for detection of synthetic images. Our code and dataset are available at the project page https://www.idiap.ch/paper/agesynth/
FantasyID: A dataset for detecting digital manipulations of ID-documents
Jul 28, 2025Advancements in image generation led to the availability of easy-to-use tools for malicious actors to create forged images. These tools pose a serious threat to the widespread Know Your Customer (KYC) applications, requiring robust systems for detection of the forged Identity Documents (IDs). To facilitate the development of the detection algorithms, in this paper, we propose a novel publicly available (including commercial use) dataset, FantasyID, which mimics real-world IDs but without tampering with legal documents and, compared to previous public datasets, it does not contain generated faces or specimen watermarks. FantasyID contains ID cards with diverse design styles, languages, and faces of real people. To simulate a realistic KYC scenario, the cards from FantasyID were printed and captured with three different devices, constituting the bonafide class. We have emulated digital forgery/injection attacks that could be performed by a malicious actor to tamper the IDs using the existing generative tools. The current state-of-the-art forgery detection algorithms, such as TruFor, MMFusion, UniFD, and FatFormer, are challenged by FantasyID dataset. It especially evident, in the evaluation conditions close to practical, with the operational threshold set on validation set so that false positive rate is at 10%, leading to false negative rates close to 50% across the board on the test set. The evaluation experiments demonstrate that FantasyID dataset is complex enough to be used as an evaluation benchmark for detection algorithms.
Investigation of Accuracy and Bias in Face Recognition Trained with Synthetic Data
Jul 28, 2025Synthetic data has emerged as a promising alternative for training face recognition (FR) models, offering advantages in scalability, privacy compliance, and potential for bias mitigation. However, critical questions remain on whether both high accuracy and fairness can be achieved with synthetic data. In this work, we evaluate the impact of synthetic data on bias and performance of FR systems. We generate balanced face dataset, FairFaceGen, using two state of the art text-to-image generators, Flux.1-dev and Stable Diffusion v3.5 (SD35), and combine them with several identity augmentation methods, including Arc2Face and four IP-Adapters. By maintaining equal identity count across synthetic and real datasets, we ensure fair comparisons when evaluating FR performance on standard (LFW, AgeDB-30, etc.) and challenging IJB-B/C benchmarks and FR bias on Racial Faces in-the-Wild (RFW) dataset. Our results demonstrate that although synthetic data still lags behind the real datasets in the generalization on IJB-B/C, demographically balanced synthetic datasets, especially those generated with SD35, show potential for bias mitigation. We also observe that the number and quality of intra-class augmentations significantly affect FR accuracy and fairness. These findings provide practical guidelines for constructing fairer FR systems using synthetic data.
HintsOfTruth: A Multimodal Checkworthiness Detection Dataset with Real and Synthetic Claims
Feb 17, 2025
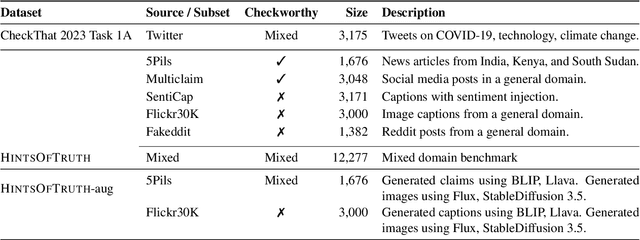
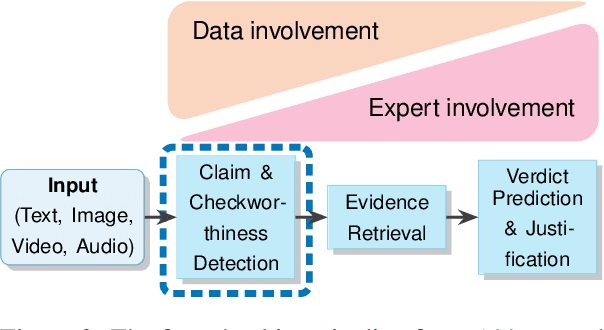
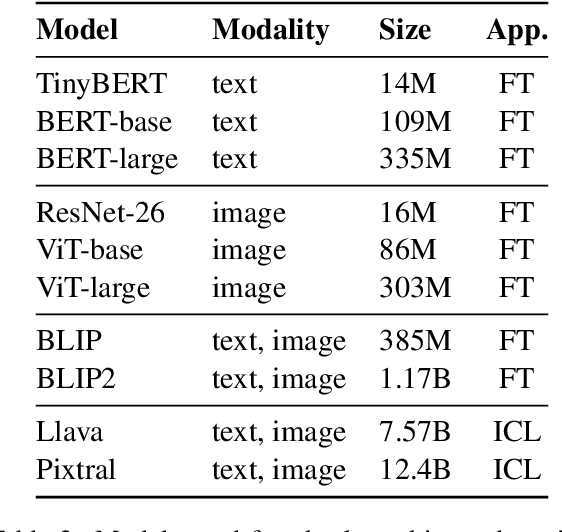
Misinformation can be countered with fact-checking, but the process is costly and slow. Identifying checkworthy claims is the first step, where automation can help scale fact-checkers' efforts. However, detection methods struggle with content that is 1) multimodal, 2) from diverse domains, and 3) synthetic. We introduce HintsOfTruth, a public dataset for multimodal checkworthiness detection with $27$K real-world and synthetic image/claim pairs. The mix of real and synthetic data makes this dataset unique and ideal for benchmarking detection methods. We compare fine-tuned and prompted Large Language Models (LLMs). We find that well-configured lightweight text-based encoders perform comparably to multimodal models but the first only focus on identifying non-claim-like content. Multimodal LLMs can be more accurate but come at a significant computational cost, making them impractical for large-scale applications. When faced with synthetic data, multimodal models perform more robustly
Vulnerability of Automatic Identity Recognition to Audio-Visual Deepfakes
Nov 29, 2023The task of deepfakes detection is far from being solved by speech or vision researchers. Several publicly available databases of fake synthetic video and speech were built to aid the development of detection methods. However, existing databases typically focus on visual or voice modalities and provide no proof that their deepfakes can in fact impersonate any real person. In this paper, we present the first realistic audio-visual database of deepfakes SWAN-DF, where lips and speech are well synchronized and video have high visual and audio qualities. We took the publicly available SWAN dataset of real videos with different identities to create audio-visual deepfakes using several models from DeepFaceLab and blending techniques for face swapping and HiFiVC, DiffVC, YourTTS, and FreeVC models for voice conversion. From the publicly available speech dataset LibriTTS, we also created a separate database of only audio deepfakes LibriTTS-DF using several latest text to speech methods: YourTTS, Adaspeech, and TorToiSe. We demonstrate the vulnerability of a state of the art speaker recognition system, such as ECAPA-TDNN-based model from SpeechBrain, to the synthetic voices. Similarly, we tested face recognition system based on the MobileFaceNet architecture to several variants of our visual deepfakes. The vulnerability assessment show that by tuning the existing pretrained deepfake models to specific identities, one can successfully spoof the face and speaker recognition systems in more than 90% of the time and achieve a very realistic looking and sounding fake video of a given person.
Are GAN-based Morphs Threatening Face Recognition?
May 05, 2022
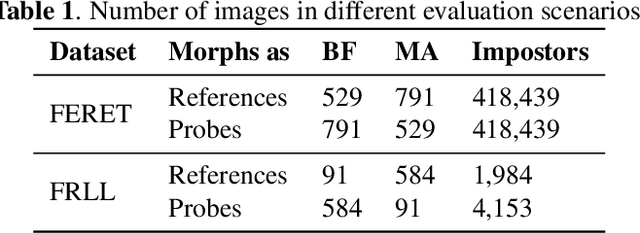
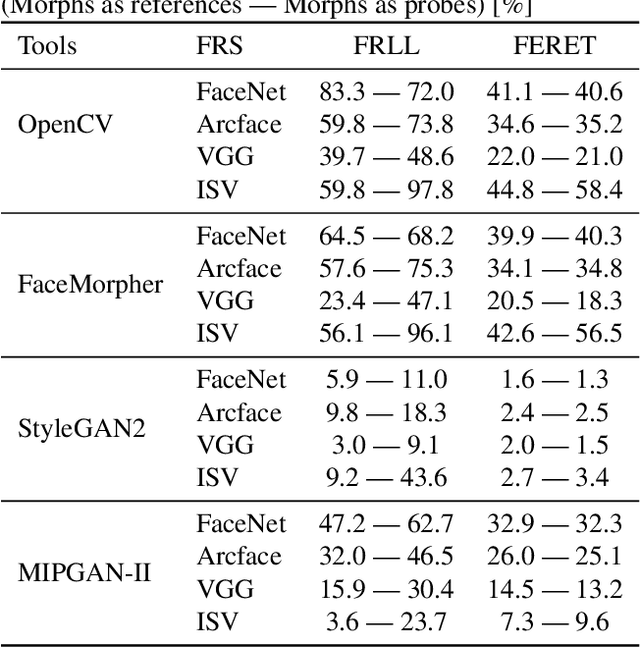
Morphing attacks are a threat to biometric systems where the biometric reference in an identity document can be altered. This form of attack presents an important issue in applications relying on identity documents such as border security or access control. Research in generation of face morphs and their detection is developing rapidly, however very few datasets with morphing attacks and open-source detection toolkits are publicly available. This paper bridges this gap by providing two datasets and the corresponding code for four types of morphing attacks: two that rely on facial landmarks based on OpenCV and FaceMorpher, and two that use StyleGAN 2 to generate synthetic morphs. We also conduct extensive experiments to assess the vulnerability of four state-of-the-art face recognition systems, including FaceNet, VGG-Face, ArcFace, and ISV. Surprisingly, the experiments demonstrate that, although visually more appealing, morphs based on StyleGAN 2 do not pose a significant threat to the state to face recognition systems, as these morphs were outmatched by the simple morphs that are based facial landmarks.
* arXiv admin note: substantial text overlap with arXiv:2012.05344
Vulnerability Analysis of Face Morphing Attacks from Landmarks and Generative Adversarial Networks
Dec 09, 2020
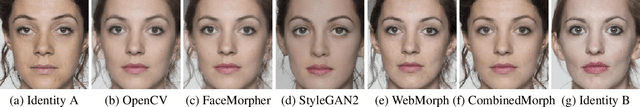
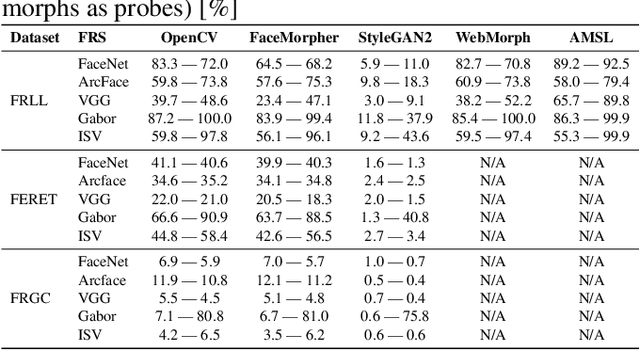
Morphing attacks is a threat to biometric systems where the biometric reference in an identity document can be altered. This form of attack presents an important issue in applications relying on identity documents such as border security or access control. Research in face morphing attack detection is developing rapidly, however very few datasets with several forms of attacks are publicly available. This paper bridges this gap by providing a new dataset with four different types of morphing attacks, based on OpenCV, FaceMorpher, WebMorph and a generative adversarial network (StyleGAN), generated with original face images from three public face datasets. We also conduct extensive experiments to assess the vulnerability of the state-of-the-art face recognition systems, notably FaceNet, VGG-Face, and ArcFace. The experiments demonstrate that VGG-Face, while being less accurate face recognition system compared to FaceNet, is also less vulnerable to morphing attacks. Also, we observed that na\"ive morphs generated with a StyleGAN do not pose a significant threat.
Deepfake detection: humans vs. machines
Sep 07, 2020



Deepfake videos, where a person's face is automatically swapped with a face of someone else, are becoming easier to generate with more realistic results. In response to the threat such manipulations can pose to our trust in video evidence, several large datasets of deepfake videos and many methods to detect them were proposed recently. However, it is still unclear how realistic deepfake videos are for an average person and whether the algorithms are significantly better than humans at detecting them. In this paper, we present a subjective study conducted in a crowdsourcing-like scenario, which systematically evaluates how hard it is for humans to see if the video is deepfake or not. For the evaluation, we used 120 different videos (60 deepfakes and 60 originals) manually pre-selected from the Facebook deepfake database, which was provided in the Kaggle's Deepfake Detection Challenge 2020. For each video, a simple question: "Is face of the person in the video real of fake?" was answered on average by 19 na\"ive subjects. The results of the subjective evaluation were compared with the performance of two different state of the art deepfake detection methods, based on Xception and EfficientNets (B4 variant) neural networks, which were pre-trained on two other large public databases: the Google's subset from FaceForensics++ and the recent Celeb-DF dataset. The evaluation demonstrates that while the human perception is very different from the perception of a machine, both successfully but in different ways are fooled by deepfakes. Specifically, algorithms struggle to detect those deepfake videos, which human subjects found to be very easy to spot.
The Speed Submission to DIHARD II: Contributions & Lessons Learned
Nov 06, 2019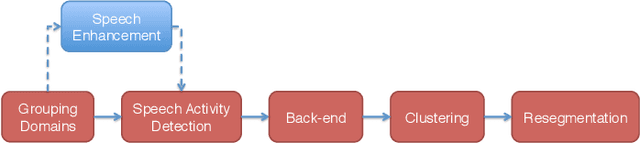
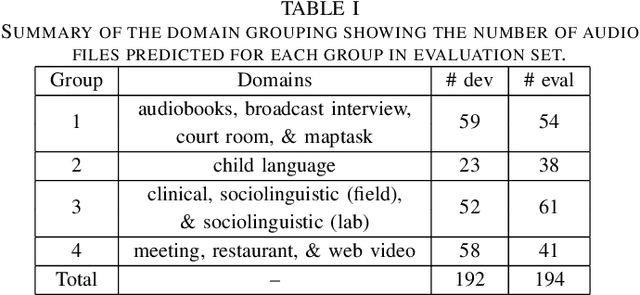


This paper describes the speaker diarization systems developed for the Second DIHARD Speech Diarization Challenge (DIHARD II) by the Speed team. Besides describing the system, which considerably outperformed the challenge baselines, we also focus on the lessons learned from numerous approaches that we tried for single and multi-channel systems. We present several components of our diarization system, including categorization of domains, speech enhancement, speech activity detection, speaker embeddings, clustering methods, resegmentation, and system fusion. We analyze and discuss the effect of each such component on the overall diarization performance within the realistic settings of the challenge.
Vulnerability of Face Recognition to Deep Morphing
Oct 03, 2019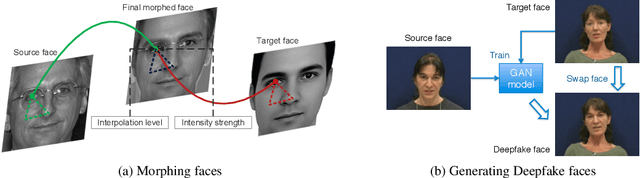

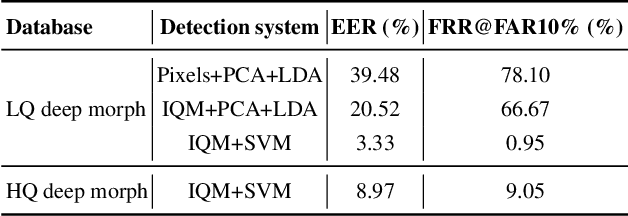

It is increasingly easy to automatically swap faces in images and video or morph two faces into one using generative adversarial networks (GANs). The high quality of the resulted deep-morph raises the question of how vulnerable the current face recognition systems are to such fake images and videos. It also calls for automated ways to detect these GAN-generated faces. In this paper, we present the publicly available dataset of the Deepfake videos with faces morphed with a GAN-based algorithm. To generate these videos, we used open source software based on GANs, and we emphasize that training and blending parameters can significantly impact the quality of the resulted videos. We show that the state of the art face recognition systems based on VGG and Facenet neural networks are vulnerable to the deep morph videos, with 85.62 and 95.00 false acceptance rates, respectively, which means methods for detecting these videos are necessary. We consider several baseline approaches for detecting deep morphs and find that the method based on visual quality metrics (often used in presentation attack detection domain) leads to the best performance with 8.97 equal error rate. Our experiments demonstrate that GAN-generated deep morph videos are challenging for both face recognition systems and existing detection methods, and the further development of deep morphing technologies will make it even more so.