 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASVspoof 2021: Towards Spoofed and Deepfake Speech Detection in the Wild
Oct 05, 2022
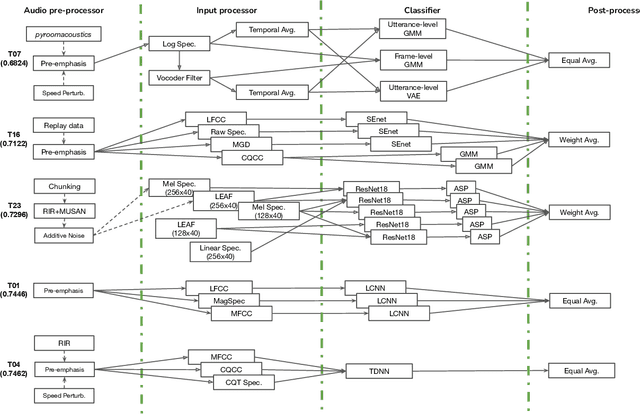
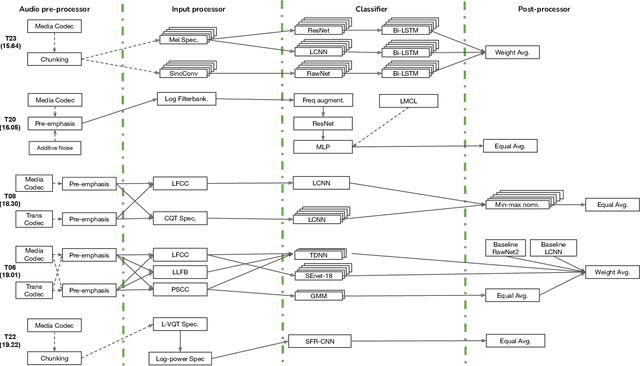
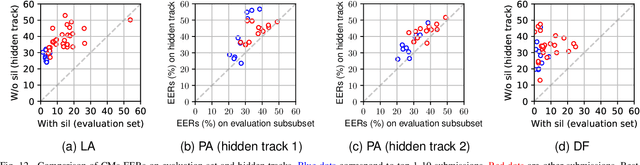
Benchmarking initiatives support the meaningful comparison of competing solutions to prominent problems in speech and language processing. Successive benchmarking evaluations typically reflect a progressive evolution from ideal lab conditions towards to those encountered in the wild. ASVspoof, the spoofing and deepfake detection initiative and challenge series, has followed the same trend. This article provides a summary of the ASVspoof 2021 challenge and the results of 37 participating teams. For the logical access task, results indicate that countermeasures solutions are robust to newly introduced encoding and transmission effects. Results for the physical access task indicate the potential to detect replay attacks in real, as opposed to simulated physical spaces, but a lack of robustness to variations between simulated and real acoustic environments. The DF task, new to the 2021 edition, targets solutions to the detection of manipulated, compressed speech data posted online. While detection solutions offer some resilience to compression effects, they lack generalization across different source datasets. In addition to a summary of the top-performing systems for each task, new analyses of influential data factors and results for hidden data subsets, the article includes a review of post-challenge results, an outline of the principal challenge limitations and a road-map for the future of ASVspoof. Link to the ASVspoof challenge and related resources: https://www.asvspoof.org/index2021.html
The VoicePrivacy 2020 Challenge Evaluation Plan
May 14, 2022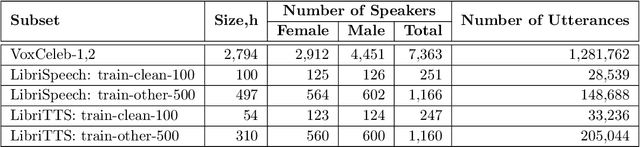
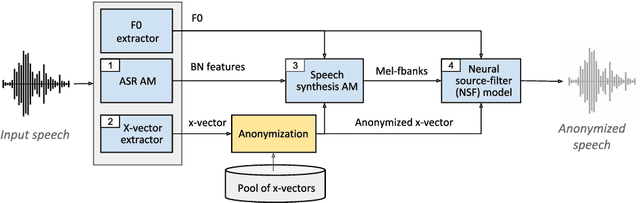
The VoicePrivacy Challenge aims to promote the development of privacy preservation tools for speech technology by gathering a new community to define the tasks of interest and the evaluation methodology, and benchmarking solutions through a series of challenges. In this document, we formulate the voice anonymization task selected for the VoicePrivacy 2020 Challenge and describe the datasets used for system development and evaluation. We also present the attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and report objective evaluation results.
Exploring auditory acoustic features for the diagnosis of the Covid-19
Jan 22, 2022
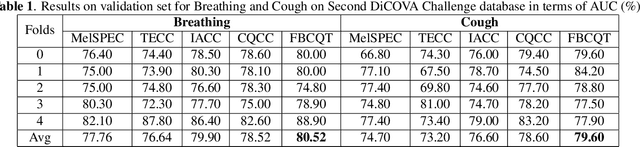
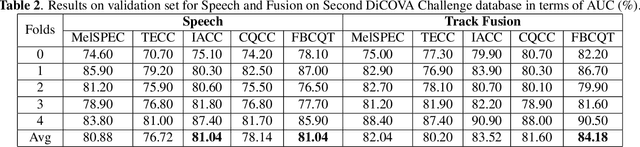
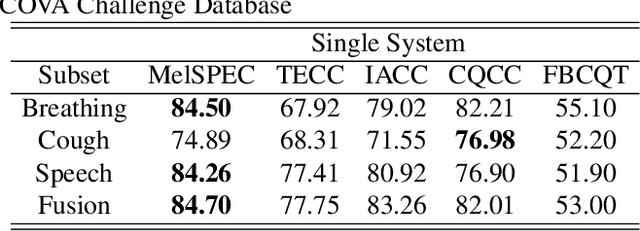
The current outbreak of a coronavirus, has quickly escalated to become a serious global problem that has now been declared a Public Health Emergency of International Concern by the World Health Organization. Infectious diseases know no borders, so when it comes to controlling outbreaks, timing is absolutely essential. It is so important to detect threats as early as possible, before they spread. After a first successful DiCOVA challenge, the organisers released second DiCOVA challenge with the aim of diagnosing COVID-19 through the use of breath, cough and speech audio samples. This work presents the details of the automatic system for COVID-19 detection using breath, cough and speech recordings. We developed different front-end auditory acoustic features along with a bidirectional Long Short-Term Memory (bi-LSTM) as classifier. The results are promising and have demonstrated the high complementary behaviour among the auditory acoustic features in the Breathing, Cough and Speech tracks giving an AUC of 86.60% on the test set.
RawBoost: A Raw Data Boosting and Augmentation Method applied to Automatic Speaker Verification Anti-Spoofing
Nov 08, 2021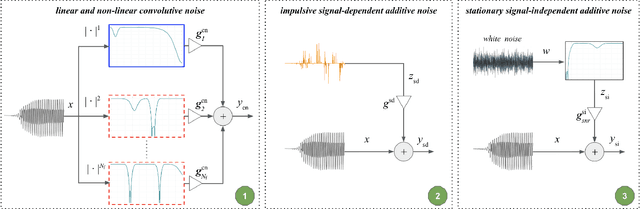
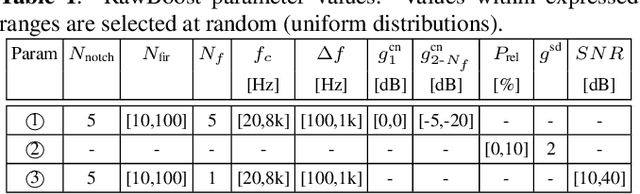
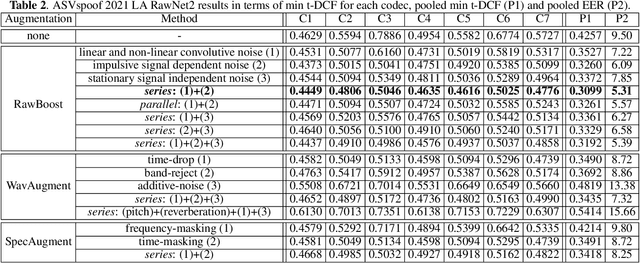
This paper introduces RawBoost, a data boosting and augmentation method for the design of more reliable spoofing detection solutions which operate directly upon raw waveform inputs. While RawBoost requires no additional data sources, e.g. noise recordings or impulse responses and is data, application and model agnostic, it is designed for telephony scenarios. Based upon the combination of linear and non-linear convolutive noise, impulsive signal-dependent additive noise and stationary signal-independent additive noise, RawBoost models nuisance variability stemming from, e.g., encoding, transmission, microphones and amplifiers, and both linear and non-linear distortion. Experiments performed using the ASVspoof 2021 logical access database show that RawBoost improves the performance of a state-of-the-art raw end-to-end baseline system by 27% relative and is only outperformed by solutions that either depend on external data or that require additional intervention at the model level.
Explaining deep learning models for spoofing and deepfake detection with SHapley Additive exPlanations
Oct 07, 2021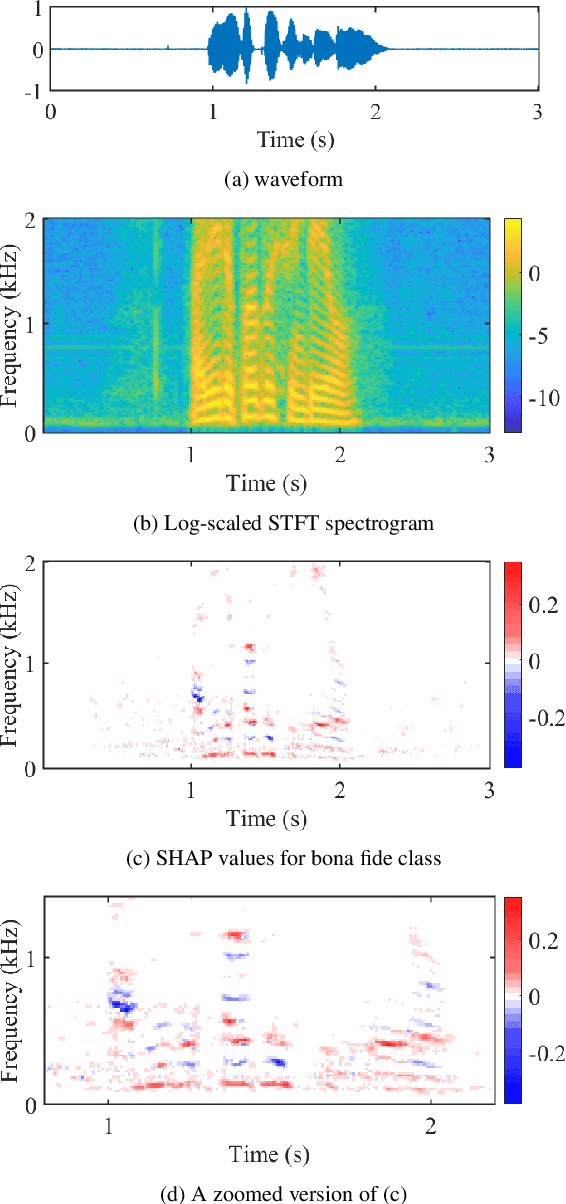
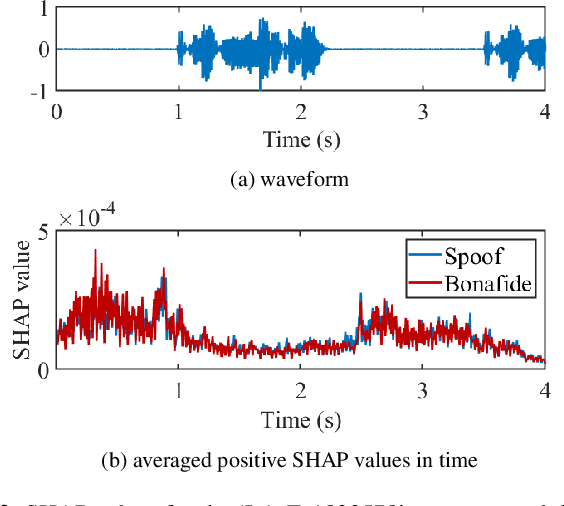
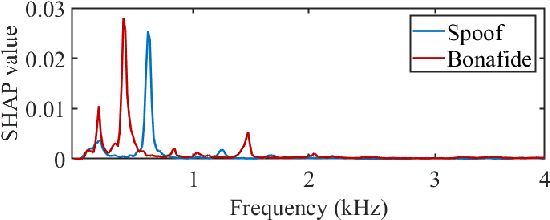
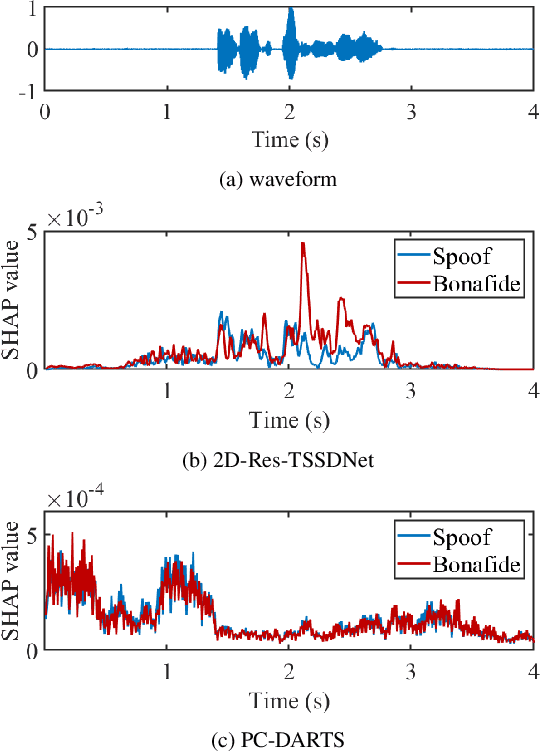
Substantial progress in spoofing and deepfake detection has been made in recent years. Nonetheless, the community has yet to make notable inroads in providing an explanation for how a classifier produces its output. The dominance of black box spoofing detection solutions is at further odds with the drive toward trustworthy, explainable artificial intelligence. This paper describes our use of SHapley Additive exPlanations (SHAP) to gain new insights in spoofing detection. We demonstrate use of the tool in revealing unexpected classifier behaviour, the artefacts that contribute most to classifier outputs and differences in the behaviour of competing spoofing detection models. The tool is both efficient and flexible, being readily applicable to a host of different architecture models in addition to related, different applications. All results reported in the paper are reproducible using open-source software.
The VoicePrivacy 2020 Challenge: Results and findings
Sep 01, 2021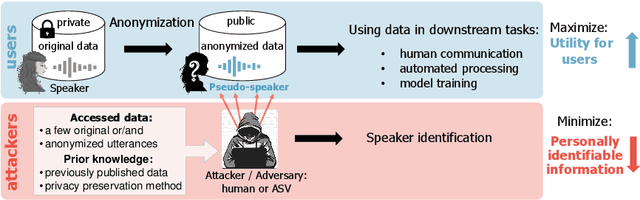
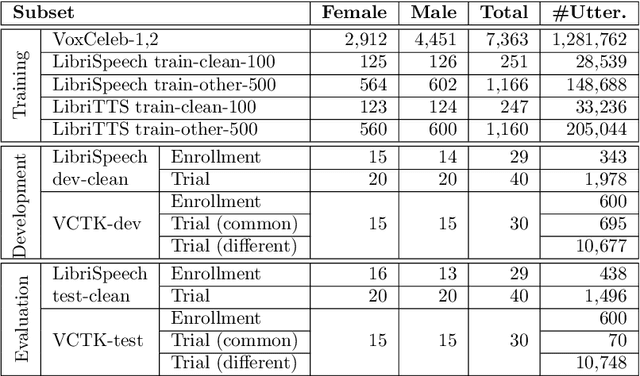
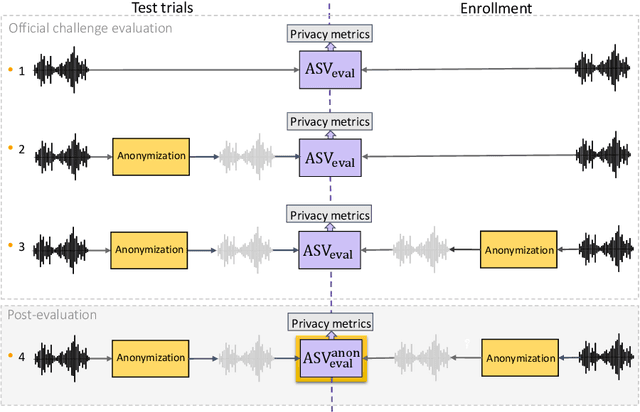
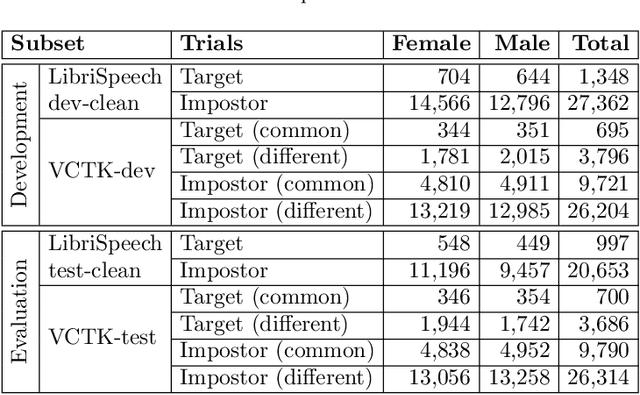
This paper presents the results and analyses stemming from the first VoicePrivacy 2020 Challenge which focuses on developing anonymization solutions for speech technology. We provide a systematic overview of the challenge design with an analysis of submitted systems and evaluation results. In particular, we describe the voice anonymization task and datasets used for system development and evaluation. Also, we present different attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and provide a summary description of the anonymization systems developed by the challenge participants. We report objective and subjective evaluation results for baseline and submitted systems. In addition, we present experimental results for alternative privacy metrics and attack models developed as a part of the post-evaluation analysis. Finally, we summarize our insights and observations that will influence the design of the next VoicePrivacy challenge edition and some directions for future voice anonymization research.
ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection
Sep 01, 2021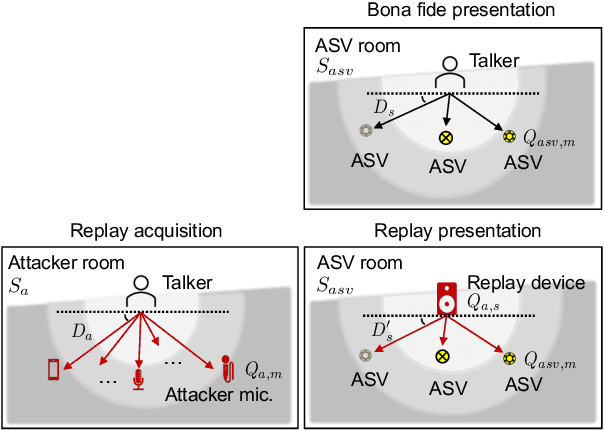
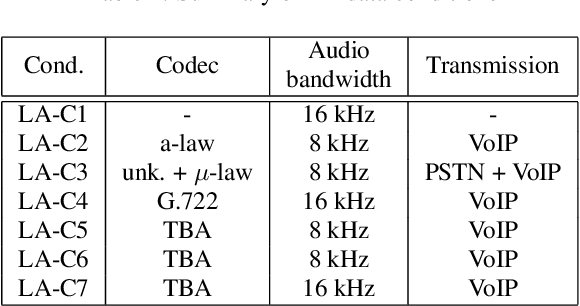
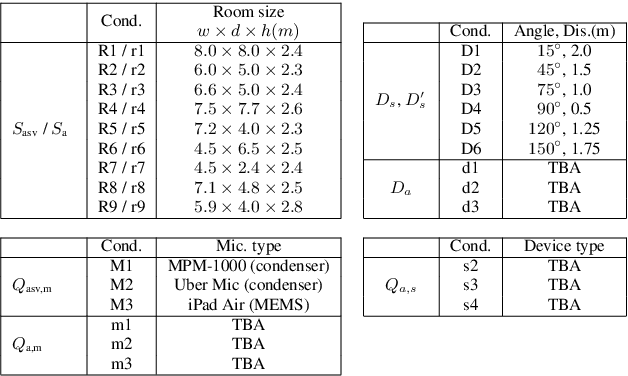
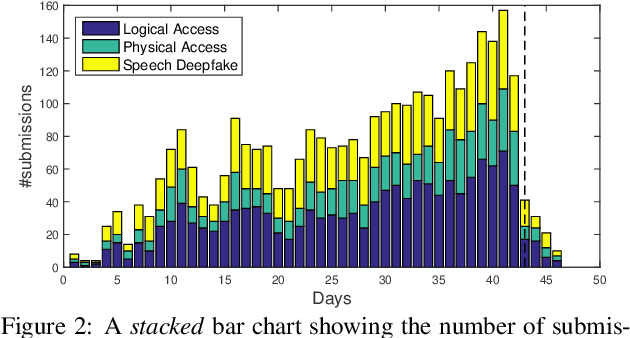
ASVspoof 2021 is the forth edition in the series of bi-annual challenges which aim to promote the study of spoofing and the design of countermeasures to protect automatic speaker verification systems from manipulation. In addition to a continued focus upon logical and physical access tasks in which there are a number of advances compared to previous editions, ASVspoof 2021 introduces a new task involving deepfake speech detection. This paper describes all three tasks, the new databases for each of them, the evaluation metrics, four challenge baselines, the evaluation platform and a summary of challenge results. Despite the introduction of channel and compression variability which compound the difficulty, results for the logical access and deepfake tasks are close to those from previous ASVspoof editions. Results for the physical access task show the difficulty in detecting attacks in real, variable physical spaces. With ASVspoof 2021 being the first edition for which participants were not provided with any matched training or development data and with this reflecting real conditions in which the nature of spoofed and deepfake speech can never be predicated with confidence, the results are extremely encouraging and demonstrate the substantial progress made in the field in recent years.
ASVspoof 2021: Automatic Speaker Verification Spoofing and Countermeasures Challenge Evaluation Plan
Sep 01, 2021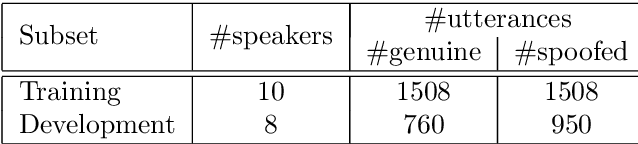
The automatic speaker verification spoofing and countermeasures (ASVspoof) challenge series is a community-led initiative which aims to promote the consideration of spoofing and the development of countermeasures. ASVspoof 2021 is the 4th in a series of bi-annual, competitive challenges where the goal is to develop countermeasures capable of discriminating between bona fide and spoofed or deepfake speech. This document provides a technical description of the ASVspoof 2021 challenge, including details of training, development and evaluation data, metrics, baselines, evaluation rules, submission procedures and the schedule.
Benchmarking and challenges in security and privacy for voice biometrics
Sep 01, 2021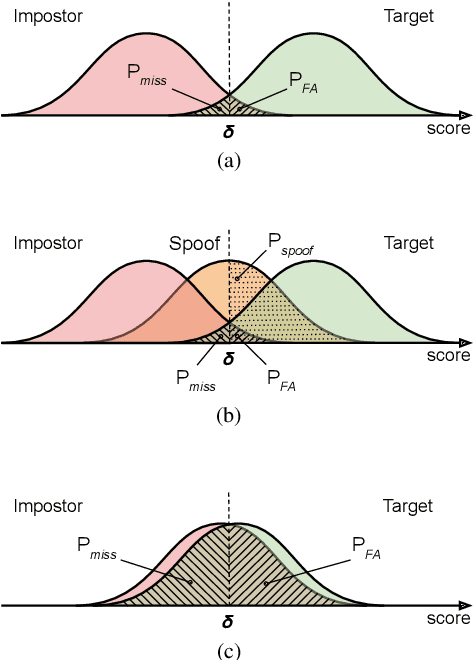
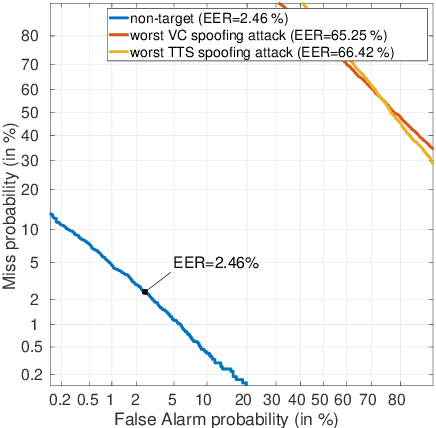
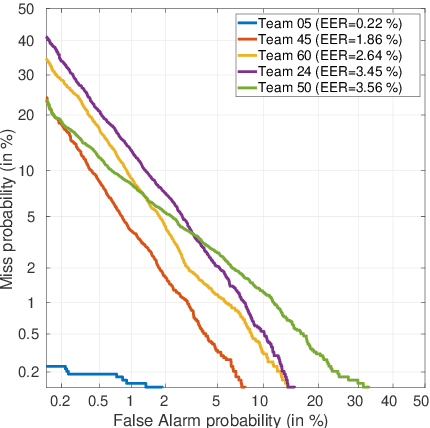
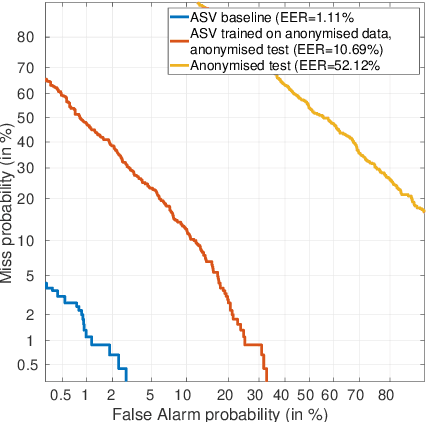
For many decades, research in speech technologies has focused upon improving reliability. With this now meeting user expectations for a range of diverse applications, speech technology is today omni-present. As result, a focus on security and privacy has now come to the fore. Here, the research effort is in its relative infancy and progress calls for greater, multidisciplinary collaboration with security, privacy, legal and ethical experts among others. Such collaboration is now underway. To help catalyse the efforts, this paper provides a high-level overview of some related research. It targets the non-speech audience and describes the benchmarking methodology that has spearheaded progress in traditional research and which now drives recent security and privacy initiatives related to voice biometrics. We describe: the ASVspoof challenge relating to the development of spoofing countermeasures; the VoicePrivacy initiative which promotes research in anonymisation for privacy preservation.
End-to-End Spectro-Temporal Graph Attention Networks for Speaker Verification Anti-Spoofing and Speech Deepfake Detection
Aug 23, 2021



Artefacts that serve to distinguish bona fide speech from spoofed or deepfake speech are known to reside in specific subbands and temporal segments. Various approaches can be used to capture and model such artefacts, however, none works well across a spectrum of diverse spoofing attacks. Reliable detection then often depends upon the fusion of multiple detection systems, each tuned to detect different forms of attack. In this paper we show that better performance can be achieved when the fusion is performed within the model itself and when the representation is learned automatically from raw waveform inputs. The principal contribution is a spectro-temporal graph attention network (GAT) which learns the relationship between cues spanning different sub-bands and temporal intervals. Using a model-level graph fusion of spectral (S) and temporal (T) sub-graphs and a graph pooling strategy to improve discrimination, the proposed RawGAT-ST model achieves an equal error rate of 1.06 % for the ASVspoof 2019 logical access database. This is one of the best results reported to date and is reproducible using an open source implementation.