 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgea-DCF: an architecture agnostic metric with application to spoofing-robust speaker verification
Mar 03, 2024



Spoofing detection is today a mainstream research topic. Standard metrics can be applied to evaluate the performance of isolated spoofing detection solutions and others have been proposed to support their evaluation when they are combined with speaker detection. These either have well-known deficiencies or restrict the architectural approach to combine speaker and spoof detectors. In this paper, we propose an architecture-agnostic detection cost function (a-DCF). A generalisation of the original DCF used widely for the assessment of automatic speaker verification (ASV), the a-DCF is designed for the evaluation of spoofing-robust ASV. Like the DCF, the a-DCF reflects the cost of decisions in a Bayes risk sense, with explicitly defined class priors and detection cost model. We demonstrate the merit of the a-DCF through the benchmarking evaluation of architecturally-heterogeneous spoofing-robust ASV solutions.
Thech. Report: Genuinization of Speech waveform PMF for speaker detection spoofing and countermeasures
Oct 09, 2023



In the context of spoofing attacks in speaker recognition systems, we observed that the waveform probability mass function (PMF) of genuine speech differs significantly from the PMF of speech resulting from the attacks. This is true for synthesized or converted speech as well as replayed speech. We also noticed that this observation seems to have a significant impact on spoofing detection performance. In this article, we propose an algorithm, denoted genuinization, capable of reducing the waveform distribution gap between authentic speech and spoofing speech. Our genuinization algorithm is evaluated on ASVspoof 2019 challenge datasets, using the baseline system provided by the challenge organization. We first assess the influence of genuinization on spoofing performance. Using genuinization for the spoofing attacks degrades spoofing detection performance by up to a factor of 10. Next, we integrate the genuinization algorithm in the spoofing countermeasures and we observe a huge spoofing detection improvement in different cases. The results of our experiments show clearly that waveform distribution plays an important role and must be taken into account by anti-spoofing systems.
Revisiting Speech Content Privacy
Oct 13, 2021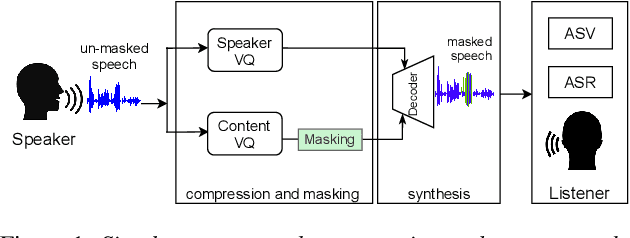
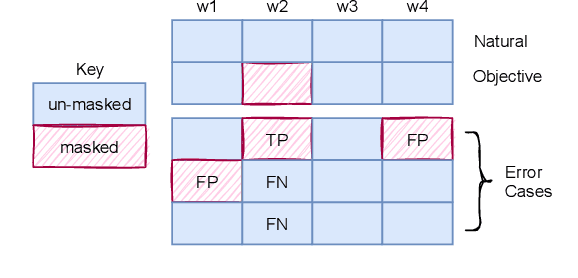
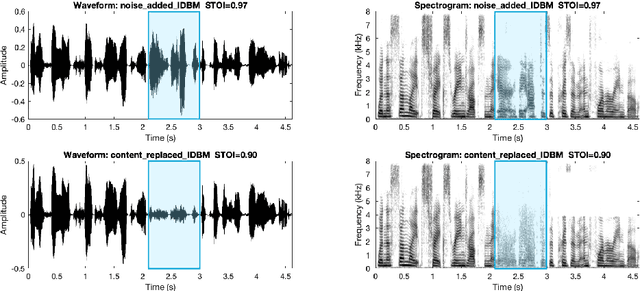
In this paper, we discuss an important aspect of speech privacy: protecting spoken content. New capabilities from the field of machine learning provide a unique and timely opportunity to revisit speech content protection. There are many different applications of content privacy, even though this area has been under-explored in speech technology research. This paper presents several scenarios that indicate a need for speech content privacy even as the specific techniques to achieve content privacy may necessarily vary. Our discussion includes several different types of content privacy including recoverable and non-recoverable content. Finally, we introduce evaluation strategies as well as describe some of the difficulties that may be encountered.
Benchmarking and challenges in security and privacy for voice biometrics
Sep 01, 2021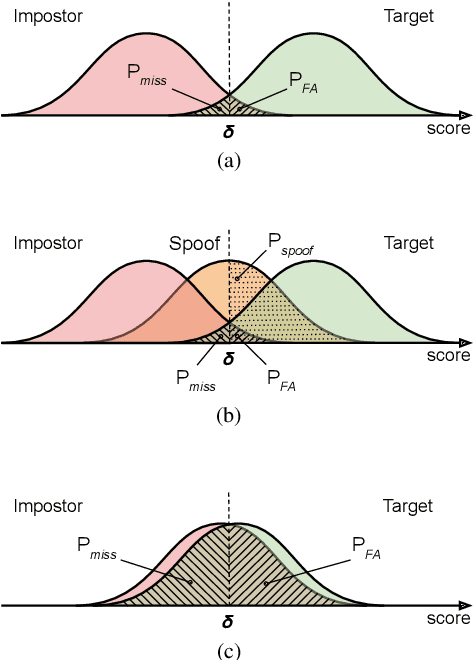
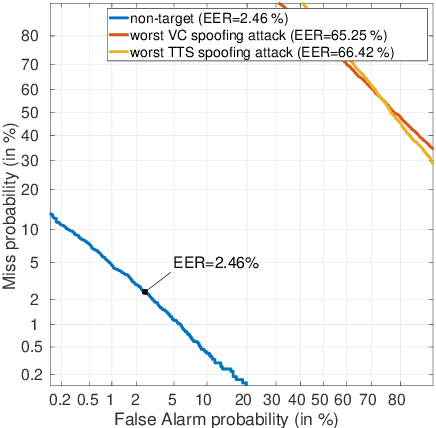
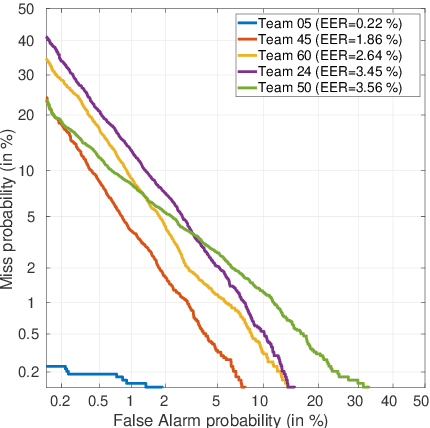
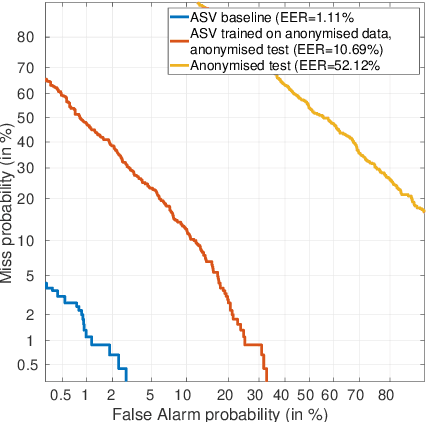
For many decades, research in speech technologies has focused upon improving reliability. With this now meeting user expectations for a range of diverse applications, speech technology is today omni-present. As result, a focus on security and privacy has now come to the fore. Here, the research effort is in its relative infancy and progress calls for greater, multidisciplinary collaboration with security, privacy, legal and ethical experts among others. Such collaboration is now underway. To help catalyse the efforts, this paper provides a high-level overview of some related research. It targets the non-speech audience and describes the benchmarking methodology that has spearheaded progress in traditional research and which now drives recent security and privacy initiatives related to voice biometrics. We describe: the ASVspoof challenge relating to the development of spoofing countermeasures; the VoicePrivacy initiative which promotes research in anonymisation for privacy preservation.
Speaker Anonymization Using X-vector and Neural Waveform Models
May 30, 2019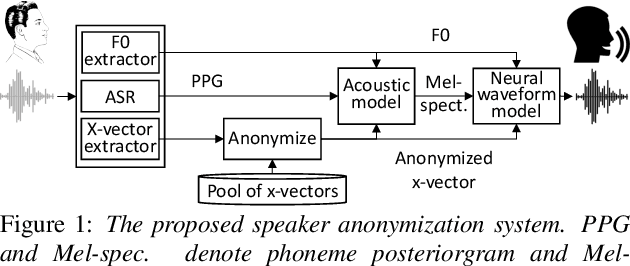
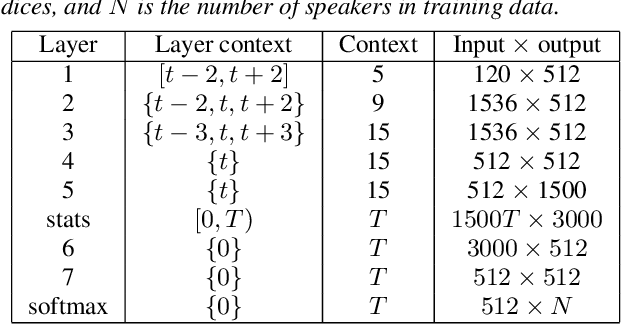
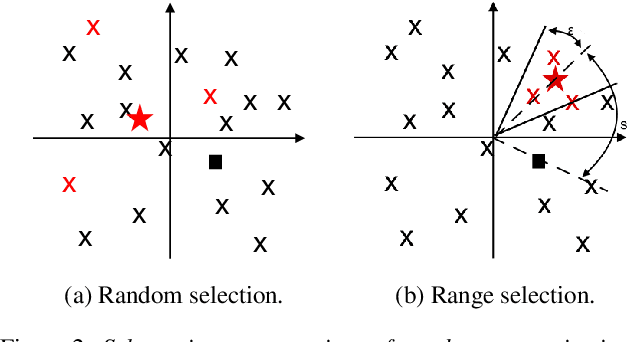
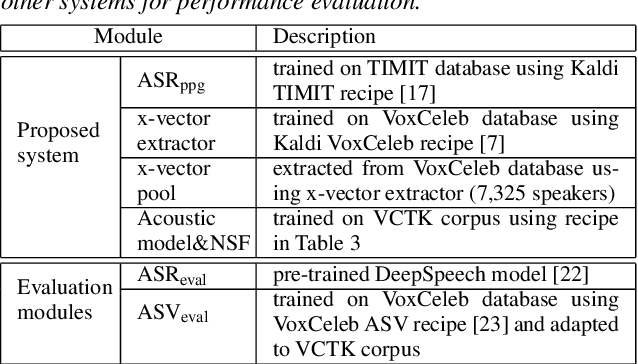
The social media revolution has produced a plethora of web services to which users can easily upload and share multimedia documents. Despite the popularity and convenience of such services, the sharing of such inherently personal data, including speech data, raises obvious security and privacy concerns. In particular, a user's speech data may be acquired and used with speech synthesis systems to produce high-quality speech utterances which reflect the same user's speaker identity. These utterances may then be used to attack speaker verification systems. One solution to mitigate these concerns involves the concealing of speaker identities before the sharing of speech data. For this purpose, we present a new approach to speaker anonymization. The idea is to extract linguistic and speaker identity features from an utterance and then to use these with neural acoustic and waveform models to synthesize anonymized speech. The original speaker identity, in the form of timbre, is suppressed and replaced with that of an anonymous pseudo identity. The approach exploits state-of-the-art x-vector speaker representations. These are used to derive anonymized pseudo speaker identities through the combination of multiple, random speaker x-vectors. Experimental results show that the proposed approach is effective in concealing speaker identities. It increases the equal error rate of a speaker verification system while maintaining high quality, anonymized speech.
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019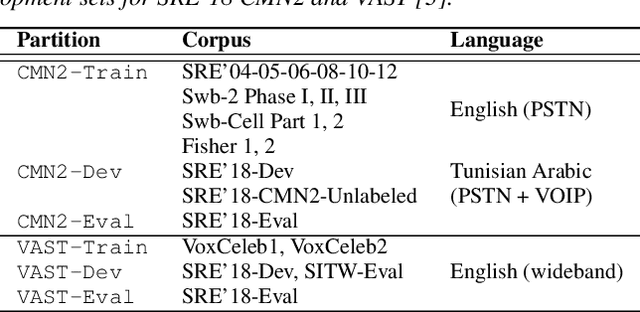
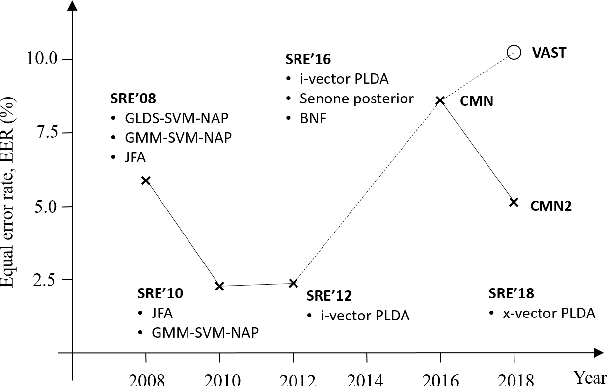
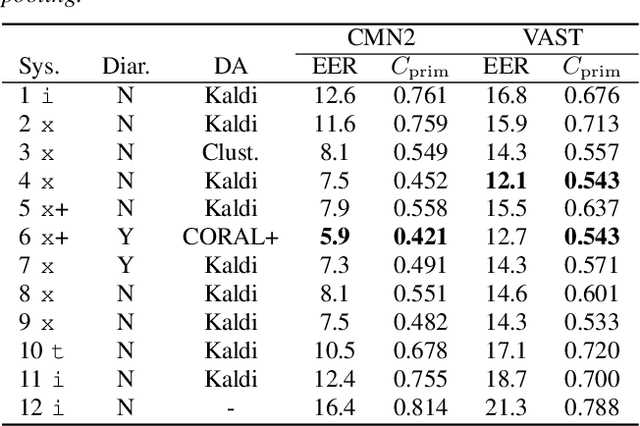
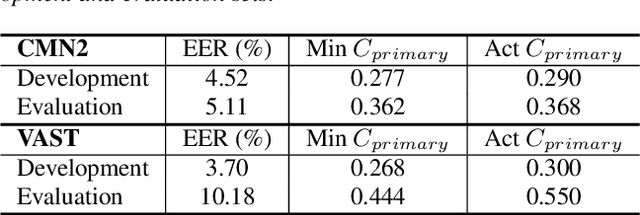
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.