 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Accent Identification via Voice Conversion and Non-Timbral Embeddings
Apr 28, 2026Automatic accent identification (AID) remains a challenging task due to the complex variability of accents, the entanglement of accent cues with speaker traits, and the scarcity of reliable accentlabelled data. To address these challenges, we propose a speaker augmentation strategy using voice conversion (VC), with which we generate additional training data by converting original training utterances into different speaker voices while preserving accentual cues. For this purpose, we select two recent VC systems and evaluate their capability to preserve accent. Alternatively, we also explore the use of non-timbral embeddings in AID, for their ability to convey accent information among other non timbral cues. The effectiveness of both methods is demonstrated on the GenAID benchmark, achieving a new state-of-the-art F1-score of 0.66, compared to the previous score of 0.55. Beyond AID, we show that non-timbral embeddings enable accent-controlled Text-to-Speech, producing high-fidelity speech with accurate accent transfer.
Identity leakage through accent cues in voice anonymisation
Mar 27, 2026Voice anonymisation is used to conceal voice identity while preserving linguistic content. Even if anonymisation seems strong, non-timbral cues such as accent that remain post-anonymisation can help re-identification and reveal sensitive socio-demographic traits. We report a study of residual accent information involving multiple anonymisation systems. We highlight the role of accent using speaker verification, accent verification, and accent classification using a set of embeddings focusing on timbral, non-timbral and accent-related information and show the extent to which related cues facilitate reidentification post anonymisation. Results show that, while some systems are robust to reidentification attempts using accent cues, others leave residual, speaker-dependent, accentrelated cues which can be used to reveal the voice identity. We also highlight accent-dependent variation in anonymisation performance, raising fairness concerns, and show that a system with characterlevel conditioning can help obfuscate identity-revealing accent cues, reducing accent-identification accuracy by 68% on average and improving overall anonymisation performance by 11% relative.
Enhancing Multi-Corpus Training in SSL-Based Anti-Spoofing Models: Domain-Invariant Feature Extraction
Mar 19, 2026The performance of speech spoofing detection often varies across different training and evaluation corpora. Leveraging multiple corpora typically enhances robustness and performance in fields like speaker recognition and speech recognition. However, our spoofing detection experiments show that multi-corpus training does not consistently improve performance and may even degrade it. We hypothesize that dataset-specific biases impair generalization, leading to performance instability. To address this, we propose an Invariant Domain Feature Extraction (IDFE) framework, employing multi-task learning and a gradient reversal layer to minimize corpus-specific information in learned embeddings. The IDFE framework reduces the average equal error rate by 20% compared to the baseline, assessed across four varied datasets.
Assessing the Impact of Speaker Identity in Speech Spoofing Detection
Feb 24, 2026Spoofing detection systems are typically trained using diverse recordings from multiple speakers, often assuming that the resulting embeddings are independent of speaker identity. However, this assumption remains unverified. In this paper, we investigate the impact of speaker information on spoofing detection systems. We propose two approaches within our Speaker-Invariant Multi-Task framework, one that models speaker identity within the embeddings and another that removes it. SInMT integrates multi-task learning for joint speaker recognition and spoofing detection, incorporating a gradient reversal layer. Evaluated using four datasets, our speaker-invariant model reduces the average equal error rate by 17% compared to the baseline, with up to 48% reduction for the most challenging attacks (e.g., A11).
WeDefense: A Toolkit to Defend Against Fake Audio
Jan 21, 2026The advances in generative AI have enabled the creation of synthetic audio which is perceptually indistinguishable from real, genuine audio. Although this stellar progress enables many positive applications, it also raises risks of misuse, such as for impersonation, disinformation and fraud. Despite a growing number of open-source fake audio detection codes released through numerous challenges and initiatives, most are tailored to specific competitions, datasets or models. A standardized and unified toolkit that supports the fair benchmarking and comparison of competing solutions with not just common databases, protocols, metrics, but also a shared codebase, is missing. To address this, we propose WeDefense, the first open-source toolkit to support both fake audio detection and localization. Beyond model training, WeDefense emphasizes critical yet often overlooked components: flexible input and augmentation, calibration, score fusion, standardized evaluation metrics, and analysis tools for deeper understanding and interpretation. The toolkit is publicly available at https://github.com/zlin0/wedefense with interactive demos for fake audio detection and localization.
The Third VoicePrivacy Challenge: Preserving Emotional Expressiveness and Linguistic Content in Voice Anonymization
Jan 17, 2026We present results and analyses from the third VoicePrivacy Challenge held in 2024, which focuses on advancing voice anonymization technologies. The task was to develop a voice anonymization system for speech data that conceals a speaker's voice identity while preserving linguistic content and emotional state. We provide a systematic overview of the challenge framework, including detailed descriptions of the anonymization task and datasets used for both system development and evaluation. We outline the attack model and objective evaluation metrics for assessing privacy protection (concealing speaker voice identity) and utility (content and emotional state preservation). We describe six baseline anonymization systems and summarize the innovative approaches developed by challenge participants. Finally, we provide key insights and observations to guide the design of future VoicePrivacy challenges and identify promising directions for voice anonymization research.
ASVspoof 5: Evaluation of Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Jan 07, 2026ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake detection solutions. A significant change from previous challenge editions is a new crowdsourced database collected from a substantially greater number of speakers under diverse recording conditions, and a mix of cutting-edge and legacy generative speech technology. With the new database described elsewhere, we provide in this paper an overview of the ASVspoof 5 challenge results for the submissions of 53 participating teams. While many solutions perform well, performance degrades under adversarial attacks and the application of neural encoding/compression schemes. Together with a review of post-challenge results, we also report a study of calibration in addition to other principal challenges and outline a road-map for the future of ASVspoof.
Exploring Situated Stabilities of a Rhythm Generation System through Variational Cross-Examination
Sep 05, 2025This paper investigates GrooveTransformer, a real-time rhythm generation system, through the postphenomenological framework of Variational Cross-Examination (VCE). By reflecting on its deployment across three distinct artistic contexts, we identify three stabilities: an autonomous drum accompaniment generator, a rhythmic control voltage sequencer in Eurorack format, and a rhythm driver for a harmonic accompaniment system. The versatility of its applications was not an explicit goal from the outset of the project. Thus, we ask: how did this multistability emerge? Through VCE, we identify three key contributors to its emergence: the affordances of system invariants, the interdisciplinary collaboration, and the situated nature of its development. We conclude by reflecting on the viability of VCE as a descriptive and analytical method for Digital Musical Instrument (DMI) design, emphasizing its value in uncovering how technologies mediate, co-shape, and are co-shaped by users and contexts.
MDD: a Mask Diffusion Detector to Protect Speaker Verification Systems from Adversarial Perturbations
Aug 26, 2025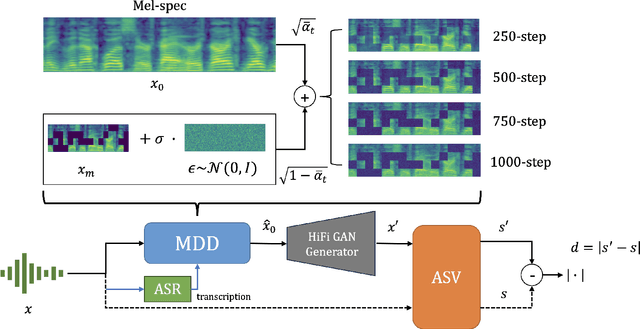
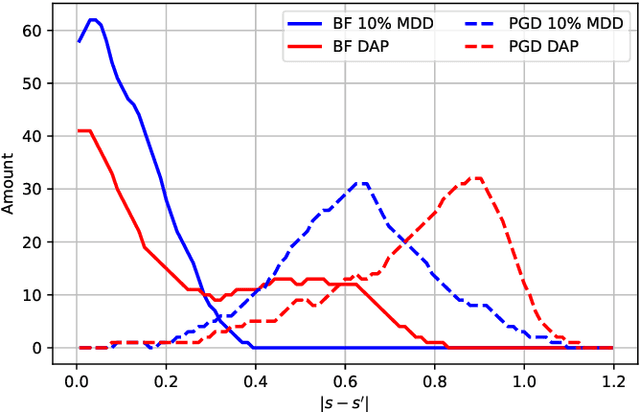
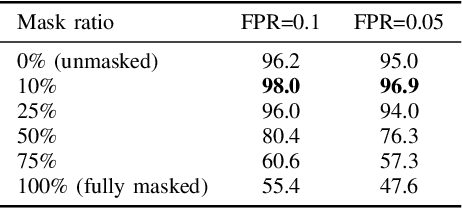

Speaker verification systems are increasingly deployed in security-sensitive applications but remain highly vulnerable to adversarial perturbations. In this work, we propose the Mask Diffusion Detector (MDD), a novel adversarial detection and purification framework based on a \textit{text-conditioned masked diffusion model}. During training, MDD applies partial masking to Mel-spectrograms and progressively adds noise through a forward diffusion process, simulating the degradation of clean speech features. A reverse process then reconstructs the clean representation conditioned on the input transcription. Unlike prior approaches, MDD does not require adversarial examples or large-scale pretraining. Experimental results show that MDD achieves strong adversarial detection performance and outperforms prior state-of-the-art methods, including both diffusion-based and neural codec-based approaches. Furthermore, MDD effectively purifies adversarially-manipulated speech, restoring speaker verification performance to levels close to those observed under clean conditions. These findings demonstrate the potential of diffusion-based masking strategies for secure and reliable speaker verification systems.
The Risks and Detection of Overestimated Privacy Protection in Voice Anonymisation
Jul 30, 2025Voice anonymisation aims to conceal the voice identity of speakers in speech recordings. Privacy protection is usually estimated from the difficulty of using a speaker verification system to re-identify the speaker post-anonymisation. Performance assessments are therefore dependent on the verification model as well as the anonymisation system. There is hence potential for privacy protection to be overestimated when the verification system is poorly trained, perhaps with mismatched data. In this paper, we demonstrate the insidious risk of overestimating anonymisation performance and show examples of exaggerated performance reported in the literature. For the worst case we identified, performance is overestimated by 74% relative. We then introduce a means to detect when performance assessment might be untrustworthy and show that it can identify all overestimation scenarios presented in the paper. Our solution is openly available as a fork of the 2024 VoicePrivacy Challenge evaluation toolkit.