 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechMLC: Speech Multi-label Classification
Sep 18, 2025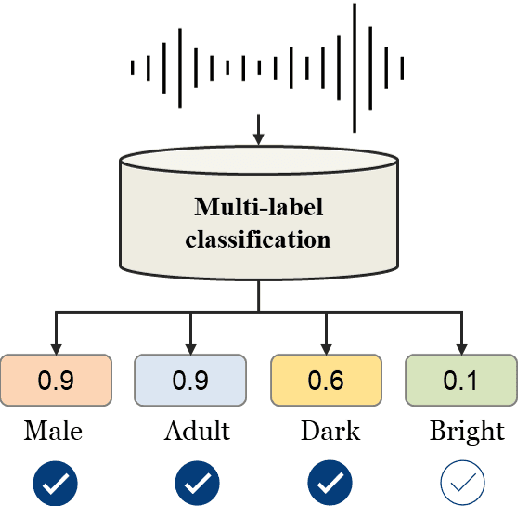
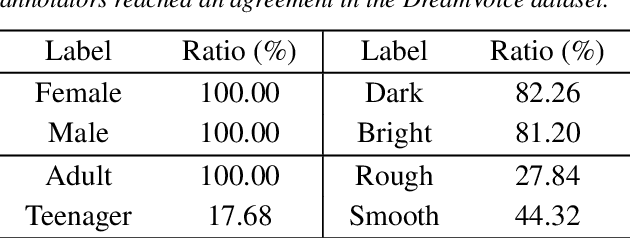
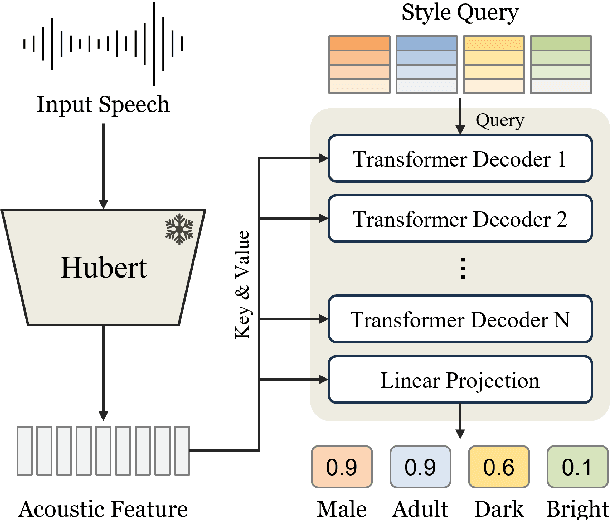

In this paper, we propose a multi-label classification framework to detect multiple speaking styles in a speech sample. Unlike previous studies that have primarily focused on identifying a single target style, our framework effectively captures various speaker characteristics within a unified structure, making it suitable for generalized human-computer interaction applications. The proposed framework integrates cross-attention mechanisms within a transformer decoder to extract salient features associated with each target label from the input speech. To mitigate the data imbalance inherent in multi-label speech datasets, we employ a data augmentation technique based on a speech generation model. We validate our model's effectiveness through multiple objective evaluations on seen and unseen corpora. In addition, we provide an analysis of the influence of human perception on classification accuracy by considering the impact of human labeling agreement on model performance.
UniCoM: A Universal Code-Switching Speech Generator
Aug 21, 2025


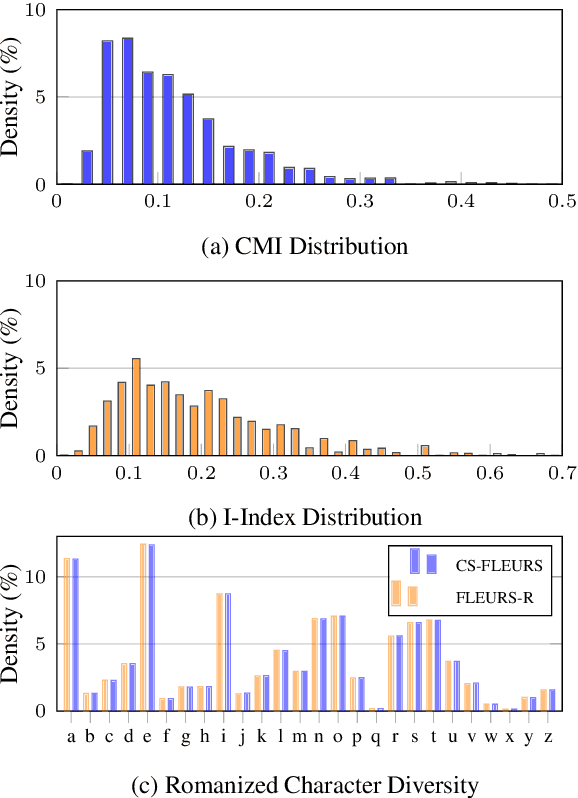
Code-switching (CS), the alternation between two or more languages within a single speaker's utterances, is common in real-world conversations and poses significant challenges for multilingual speech technology. However, systems capable of handling this phenomenon remain underexplored, primarily due to the scarcity of suitable datasets. To resolve this issue, we propose Universal Code-Mixer (UniCoM), a novel pipeline for generating high-quality, natural CS samples without altering sentence semantics. Our approach utilizes an algorithm we call Substituting WORDs with Synonyms (SWORDS), which generates CS speech by replacing selected words with their translations while considering their parts of speech. Using UniCoM, we construct Code-Switching FLEURS (CS-FLEURS), a multilingual CS corpus designed for automatic speech recognition (ASR) and speech-to-text translation (S2TT). Experimental results show that CS-FLEURS achieves high intelligibility and naturalness, performing comparably to existing datasets on both objective and subjective metrics. We expect our approach to advance CS speech technology and enable more inclusive multilingual systems.
Text-To-Speech Synthesis In The Wild
Sep 13, 2024Text-to-speech (TTS) systems are traditionally trained using modest databases of studio-quality, prompted or read speech collected in benign acoustic environments such as anechoic rooms. The recent literature nonetheless shows efforts to train TTS systems using data collected in the wild. While this approach allows for the use of massive quantities of natural speech, until now, there are no common datasets. We introduce the TTS In the Wild (TITW) dataset, the result of a fully automated pipeline, in this case, applied to the VoxCeleb1 dataset commonly used for speaker recognition. We further propose two training sets. TITW-Hard is derived from the transcription, segmentation, and selection of VoxCeleb1 source data. TITW-Easy is derived from the additional application of enhancement and additional data selection based on DNSMOS. We show that a number of recent TTS models can be trained successfully using TITW-Easy, but that it remains extremely challenging to produce similar results using TITW-Hard. Both the dataset and protocols are publicly available and support the benchmarking of TTS systems trained using TITW data.
ReCAB-VAE: Gumbel-Softmax Variational Inference Based on Analytic Divergence
May 09, 2022
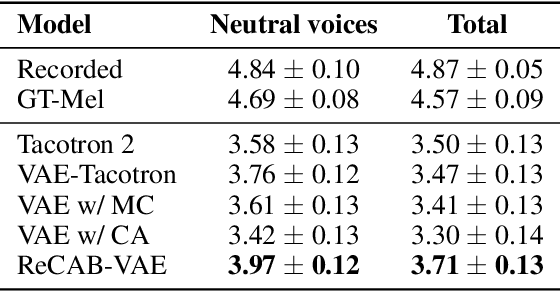


The Gumbel-softmax distribution, or Concrete distribution, is often used to relax the discrete characteristics of a categorical distribution and enable back-propagation through differentiable reparameterization. Although it reliably yields low variance gradients, it still relies on a stochastic sampling process for optimization. In this work, we present a relaxed categorical analytic bound (ReCAB), a novel divergence-like metric which corresponds to the upper bound of the Kullback-Leibler divergence (KLD) of a relaxed categorical distribution. The proposed metric is easy to implement because it has a closed form solution, and empirical results show that it is close to the actual KLD. Along with this new metric, we propose a relaxed categorical analytic bound variational autoencoder (ReCAB-VAE) that successfully models both continuous and relaxed discrete latent representations. We implement an emotional text-to-speech synthesis system based on the proposed framework, and show that the proposed system flexibly and stably controls emotion expressions with better speech quality compared to baselines that use stochastic estimation or categorical distribution approximation.
AILTTS: Adversarial Learning of Intermediate Acoustic Feature for End-to-End Lightweight Text-to-Speech
Apr 05, 2022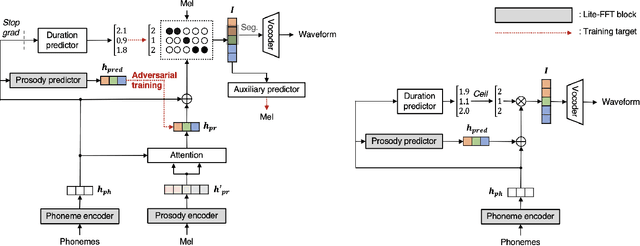
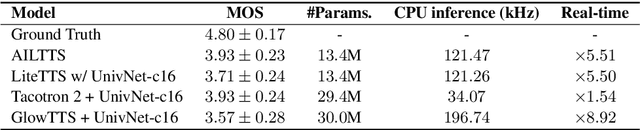


The quality of end-to-end neural text-to-speech (TTS) systems highly depends on the reliable estimation of intermediate acoustic features from text inputs. To reduce the complexity of the speech generation process, several non-autoregressive TTS systems directly find a mapping relationship between text and waveforms. However, the generation quality of these system is unsatisfactory due to the difficulty in modeling the dynamic nature of prosodic information. In this paper, we propose an effective prosody predictor that successfully replicates the characteristics of prosodic features extracted from mel-spectrograms. Specifically, we introduce a generative model-based conditional discriminator to enable the estimated embeddings have highly informative prosodic features, which significantly enhances the expressiveness of generated speech. Since the estimated embeddings obtained by the proposed method are highly correlated with acoustic features, the time-alignment of input texts and intermediate features is greatly simplified, which results in faster convergence. Our proposed model outperforms several publicly available models based on various objective and subjective evaluation metrics, even using a relatively small number of parameters.