 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Self-Attention for Zero-Shot Multi-Speaker Text-to-Speech
Aug 28, 2023For personalized speech generation, a neural text-to-speech (TTS) model must be successfully implemented with limited data from a target speaker. To this end, the baseline TTS model needs to be amply generalized to out-of-domain data (i.e., target speaker's speech). However, approaches to address this out-of-domain generalization problem in TTS have yet to be thoroughly studied. In this work, we propose an effective pruning method for a transformer known as sparse attention, to improve the TTS model's generalization abilities. In particular, we prune off redundant connections from self-attention layers whose attention weights are below the threshold. To flexibly determine the pruning strength for searching optimal degree of generalization, we also propose a new differentiable pruning method that allows the model to automatically learn the thresholds. Evaluations on zero-shot multi-speaker TTS verify the effectiveness of our method in terms of voice quality and speaker similarity.
* INTERSPEECH 2023
HappyQuokka System for ICASSP 2023 Auditory EEG Challenge
May 03, 2023This report describes our submission to Task 2 of the Auditory EEG Decoding Challenge at ICASSP 2023 Signal Processing Grand Challenge (SPGC). Task 2 is a regression problem that focuses on reconstructing a speech envelope from an EEG signal. For the task, we propose a pre-layer normalized feed-forward transformer (FFT) architecture. For within-subjects generation, we additionally utilize an auxiliary global conditioner which provides our model with additional information about seen individuals. Experimental results show that our proposed method outperforms the VLAAI baseline and all other submitted systems. Notably, it demonstrates significant improvements on the within-subjects task, likely thanks to our use of the auxiliary global conditioner. In terms of evaluation metrics set by the challenge, we obtain Pearson correlation values of 0.1895 0.0869 for the within-subjects generation test and 0.0976 0.0444 for the heldout-subjects test. We release the training code for our model online.
AILTTS: Adversarial Learning of Intermediate Acoustic Feature for End-to-End Lightweight Text-to-Speech
Apr 05, 2022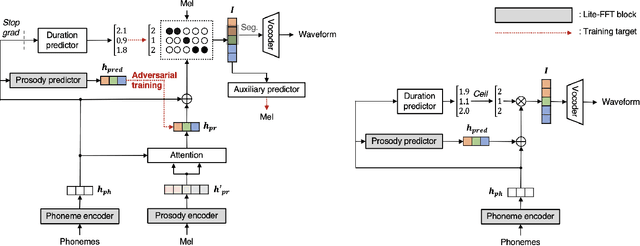
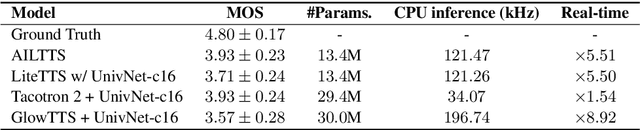


The quality of end-to-end neural text-to-speech (TTS) systems highly depends on the reliable estimation of intermediate acoustic features from text inputs. To reduce the complexity of the speech generation process, several non-autoregressive TTS systems directly find a mapping relationship between text and waveforms. However, the generation quality of these system is unsatisfactory due to the difficulty in modeling the dynamic nature of prosodic information. In this paper, we propose an effective prosody predictor that successfully replicates the characteristics of prosodic features extracted from mel-spectrograms. Specifically, we introduce a generative model-based conditional discriminator to enable the estimated embeddings have highly informative prosodic features, which significantly enhances the expressiveness of generated speech. Since the estimated embeddings obtained by the proposed method are highly correlated with acoustic features, the time-alignment of input texts and intermediate features is greatly simplified, which results in faster convergence. Our proposed model outperforms several publicly available models based on various objective and subjective evaluation metrics, even using a relatively small number of parameters.