 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechMLC: Speech Multi-label Classification
Sep 18, 2025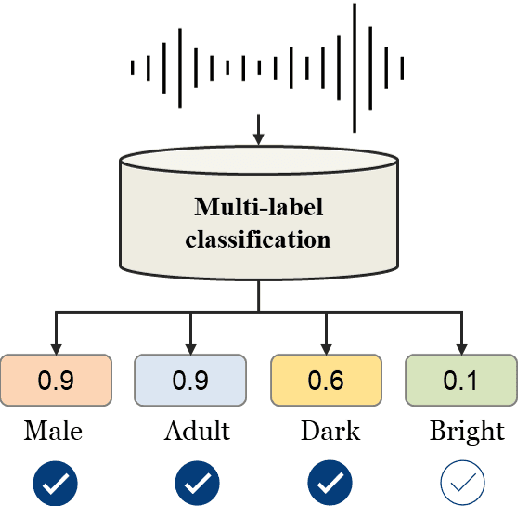
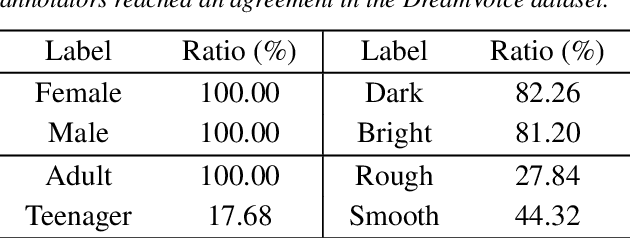
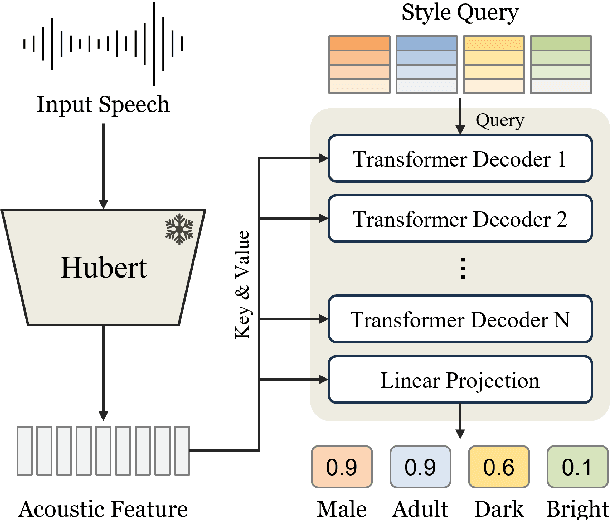

In this paper, we propose a multi-label classification framework to detect multiple speaking styles in a speech sample. Unlike previous studies that have primarily focused on identifying a single target style, our framework effectively captures various speaker characteristics within a unified structure, making it suitable for generalized human-computer interaction applications. The proposed framework integrates cross-attention mechanisms within a transformer decoder to extract salient features associated with each target label from the input speech. To mitigate the data imbalance inherent in multi-label speech datasets, we employ a data augmentation technique based on a speech generation model. We validate our model's effectiveness through multiple objective evaluations on seen and unseen corpora. In addition, we provide an analysis of the influence of human perception on classification accuracy by considering the impact of human labeling agreement on model performance.
Mitigating Intra-Speaker Variability in Diarization with Style-Controllable Speech Augmentation
Sep 18, 2025Speaker diarization systems often struggle with high intrinsic intra-speaker variability, such as shifts in emotion, health, or content. This can cause segments from the same speaker to be misclassified as different individuals, for example, when one raises their voice or speaks faster during conversation. To address this, we propose a style-controllable speech generation model that augments speech across diverse styles while preserving the target speaker's identity. The proposed system starts with diarized segments from a conventional diarizer. For each diarized segment, it generates augmented speech samples enriched with phonetic and stylistic diversity. And then, speaker embeddings from both the original and generated audio are blended to enhance the system's robustness in grouping segments with high intrinsic intra-speaker variability. We validate our approach on a simulated emotional speech dataset and the truncated AMI dataset, demonstrating significant improvements, with error rate reductions of 49% and 35% on each dataset, respectively.
Speak in the Scene: Diffusion-based Acoustic Scene Transfer toward Immersive Speech Generation
Jun 18, 2024This paper introduces a novel task in generative speech processing, Acoustic Scene Transfer (AST), which aims to transfer acoustic scenes of speech signals to diverse environments. AST promises an immersive experience in speech perception by adapting the acoustic scene behind speech signals to desired environments. We propose AST-LDM for the AST task, which generates speech signals accompanied by the target acoustic scene of the reference prompt. Specifically, AST-LDM is a latent diffusion model conditioned by CLAP embeddings that describe target acoustic scenes in either audio or text modalities. The contributions of this paper include introducing the AST task and implementing its baseline model. For AST-LDM, we emphasize its core framework, which is to preserve the input speech and generate audio consistently with both the given speech and the target acoustic environment. Experiments, including objective and subjective tests, validate the feasibility and efficacy of our approach.
BrainTalker: Low-Resource Brain-to-Speech Synthesis with Transfer Learning using Wav2Vec 2.0
Dec 21, 2023Decoding spoken speech from neural activity in the brain is a fast-emerging research topic, as it could enable communication for people who have difficulties with producing audible speech. For this task, electrocorticography (ECoG) is a common method for recording brain activity with high temporal resolution and high spatial precision. However, due to the risky surgical procedure required for obtaining ECoG recordings, relatively little of this data has been collected, and the amount is insufficient to train a neural network-based Brain-to-Speech (BTS) system. To address this problem, we propose BrainTalker-a novel BTS framework that generates intelligible spoken speech from ECoG signals under extremely low-resource scenarios. We apply a transfer learning approach utilizing a pre-trained self supervised model, Wav2Vec 2.0. Specifically, we train an encoder module to map ECoG signals to latent embeddings that match Wav2Vec 2.0 representations of the corresponding spoken speech. These embeddings are then transformed into mel-spectrograms using stacked convolutional and transformer-based layers, which are fed into a neural vocoder to synthesize speech waveform. Experimental results demonstrate our proposed framework achieves outstanding performance in terms of subjective and objective metrics, including a Pearson correlation coefficient of 0.9 between generated and ground truth mel spectrograms. We share publicly available Demos and Code.
Style Modeling for Multi-Speaker Articulation-to-Speech
Dec 21, 2023In this paper, we propose a neural articulation-to-speech (ATS) framework that synthesizes high-quality speech from articulatory signal in a multi-speaker situation. Most conventional ATS approaches only focus on modeling contextual information of speech from a single speaker's articulatory features. To explicitly represent each speaker's speaking style as well as the contextual information, our proposed model estimates style embeddings, guided from the essential speech style attributes such as pitch and energy. We adopt convolutional layers and transformer-based attention layers for our model to fully utilize both local and global information of articulatory signals, measured by electromagnetic articulography (EMA). Our model significantly improves the quality of synthesized speech compared to the baseline in terms of objective and subjective measurements in the Haskins dataset.
Self-supervised Complex Network for Machine Sound Anomaly Detection
Dec 21, 2023In this paper, we propose an anomaly detection algorithm for machine sounds with a deep complex network trained by self-supervision. Using the fact that phase continuity information is crucial for detecting abnormalities in time-series signals, our proposed algorithm utilizes the complex spectrum as an input and performs complex number arithmetic throughout the entire process. Since the usefulness of phase information can vary depending on the type of machine sound, we also apply an attention mechanism to control the weights of the complex and magnitude spectrum bottleneck features depending on the machine type. We train our network to perform a self-supervised task that classifies the machine identifier (id) of normal input sounds among multiple classes. At test time, an input signal is detected as anomalous if the trained model is unable to correctly classify the id. In other words, we determine the presence of an anomality when the output cross-entropy score of the multiclass identification task is lower than a pre-defined threshold. Experiments with the MIMII dataset show that the proposed algorithm has a much higher area under the curve (AUC) score than conventional magnitude spectrum-based algorithms.
C2C: Cough to COVID-19 Detection in BHI 2023 Data Challenge
Nov 01, 2023This report describes our submission to BHI 2023 Data Competition: Sensor challenge. Our Audio Alchemists team designed an acoustic-based COVID-19 diagnosis system, Cough to COVID-19 (C2C), and won the 1st place in the challenge. C2C involves three key contributions: pre-processing of input signals, cough-related representation extraction leveraging Wav2vec2.0, and data augmentation. Through experimental findings, we demonstrate C2C's promising potential to enhance the diagnostic accuracy of COVID-19 via cough signals. Our proposed model achieves a ROC-AUC value of 0.7810 in the context of COVID-19 diagnosis. The implementation details and the python code can be found in the following link: https://github.com/Woo-jin-Chung/BHI_2023_challenge_Audio_Alchemists
HappyQuokka System for ICASSP 2023 Auditory EEG Challenge
May 03, 2023This report describes our submission to Task 2 of the Auditory EEG Decoding Challenge at ICASSP 2023 Signal Processing Grand Challenge (SPGC). Task 2 is a regression problem that focuses on reconstructing a speech envelope from an EEG signal. For the task, we propose a pre-layer normalized feed-forward transformer (FFT) architecture. For within-subjects generation, we additionally utilize an auxiliary global conditioner which provides our model with additional information about seen individuals. Experimental results show that our proposed method outperforms the VLAAI baseline and all other submitted systems. Notably, it demonstrates significant improvements on the within-subjects task, likely thanks to our use of the auxiliary global conditioner. In terms of evaluation metrics set by the challenge, we obtain Pearson correlation values of 0.1895 0.0869 for the within-subjects generation test and 0.0976 0.0444 for the heldout-subjects test. We release the training code for our model online.