 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeak in the Scene: Diffusion-based Acoustic Scene Transfer toward Immersive Speech Generation
Jun 18, 2024This paper introduces a novel task in generative speech processing, Acoustic Scene Transfer (AST), which aims to transfer acoustic scenes of speech signals to diverse environments. AST promises an immersive experience in speech perception by adapting the acoustic scene behind speech signals to desired environments. We propose AST-LDM for the AST task, which generates speech signals accompanied by the target acoustic scene of the reference prompt. Specifically, AST-LDM is a latent diffusion model conditioned by CLAP embeddings that describe target acoustic scenes in either audio or text modalities. The contributions of this paper include introducing the AST task and implementing its baseline model. For AST-LDM, we emphasize its core framework, which is to preserve the input speech and generate audio consistently with both the given speech and the target acoustic environment. Experiments, including objective and subjective tests, validate the feasibility and efficacy of our approach.
HD-DEMUCS: General Speech Restoration with Heterogeneous Decoders
Jun 02, 2023



This paper introduces an end-to-end neural speech restoration model, HD-DEMUCS, demonstrating efficacy across multiple distortion environments. Unlike conventional approaches that employ cascading frameworks to remove undesirable noise first and then restore missing signal components, our model performs these tasks in parallel using two heterogeneous decoder networks. Based on the U-Net style encoder-decoder framework, we attach an additional decoder so that each decoder network performs noise suppression or restoration separately. We carefully design each decoder architecture to operate appropriately depending on its objectives. Additionally, we improve performance by leveraging a learnable weighting factor, aggregating the two decoder output waveforms. Experimental results with objective metrics across various environments clearly demonstrate the effectiveness of our approach over a single decoder or multi-stage systems for general speech restoration task.
An empirical study on speech restoration guided by self supervised speech representation
May 30, 2023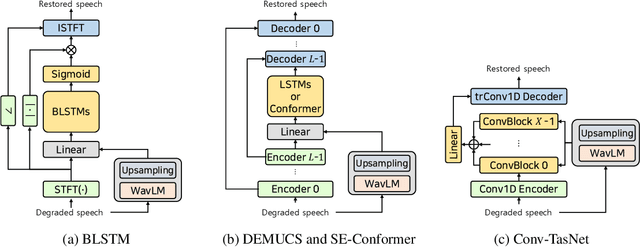
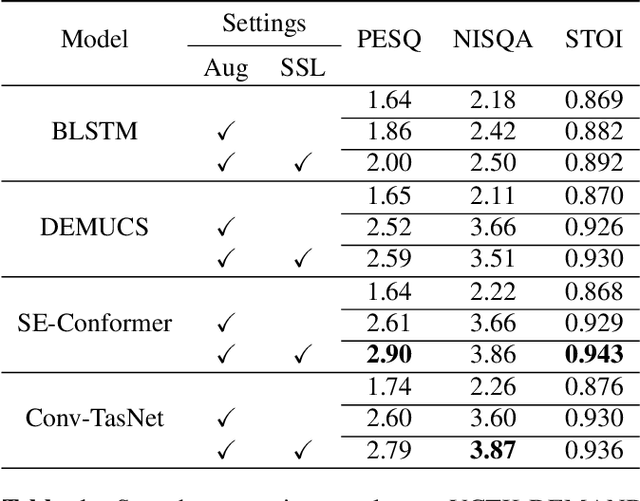


Enhancing speech quality is an indispensable yet difficult task as it is often complicated by a range of degradation factors. In addition to additive noise, reverberation, clipping, and speech attenuation can all adversely affect speech quality. Speech restoration aims to recover speech components from these distortions. This paper focuses on exploring the impact of self-supervised speech representation learning on the speech restoration task. Specifically, we employ speech representation in various speech restoration networks and evaluate their performance under complicated distortion scenarios. Our experiments demonstrate that the contextual information provided by the self-supervised speech representation can enhance speech restoration performance in various distortion scenarios, while also increasing robustness against the duration of speech attenuation and mismatched test conditions.
Diffusion-based Generative Speech Source Separation
Nov 02, 2022We propose DiffSep, a new single channel source separation method based on score-matching of a stochastic differential equation (SDE). We craft a tailored continuous time diffusion-mixing process starting from the separated sources and converging to a Gaussian distribution centered on their mixture. This formulation lets us apply the machinery of score-based generative modelling. First, we train a neural network to approximate the score function of the marginal probabilities or the diffusion-mixing process. Then, we use it to solve the reverse time SDE that progressively separates the sources starting from their mixture. We propose a modified training strategy to handle model mismatch and source permutation ambiguity. Experiments on the WSJ0 2mix dataset demonstrate the potential of the method. Furthermore, the method is also suitable for speech enhancement and shows performance competitive with prior work on the VoiceBank-DEMAND dataset.