 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysHanDI: Physics-Based Reconstruction of Hand-Deformable Object Interactions
May 10, 2026While existing methods for reconstructing hand-object interactions have made impressive progress, they either focus on rigid or part-wise rigid objects-limiting their ability to model real-world objects (e.g., cloth, stuffed animals) that exhibit highly non-rigid deformations-or model deformable objects without full 3D hand reconstruction. To bridge this gap, we present PhysHanDI (Physics-based Reconstruction of Hand and Deformable Object Interactions), a framework that enables full 3D reconstruction of both interacting hands and non-rigid objects. Our key idea is to physically simulate object deformations driven by forces induced from densely reconstructed 3D hand motions, ensuring that the reconstructed object dynamics are both physically plausible and coherent with the interacting hand movements. Furthermore, we demonstrate that such simulation of object deformations can, in turn, refine and improve hand reconstruction via inverse physics. In experiments, PhysHanDI outperforms the state-of-the-art baseline across reconstruction and future prediction.
PSY-STEP: Structuring Therapeutic Targets and Action Sequences for Proactive Counseling Dialogue Systems
Apr 06, 2026Cognitive Behavioral Therapy (CBT) aims to identify and restructure automatic negative thoughts pertaining to involuntary interpretations of events, yet existing counseling agents struggle to identify and address them in dialogue settings. To bridge this gap, we introduce STEP, a dataset that models CBT counseling by explicitly reflecting automatic thoughts alongside dynamic, action-level counseling sequences. Using this dataset, we train STEPPER, a counseling agent that proactively elicits automatic thoughts and executes cognitively grounded interventions. To further enhance both decision accuracy and empathic responsiveness, we refine STEPPER through preference learning based on simulated, synthesized counseling sessions. Extensive CBT-aligned evaluations show that STEPPER delivers more clinically grounded, coherent, and personalized counseling compared to other strong baseline models, and achieves higher counselor competence without inducing emotional disruption.
Large-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
MPMAvatar: Learning 3D Gaussian Avatars with Accurate and Robust Physics-Based Dynamics
Oct 02, 2025While there has been significant progress in the field of 3D avatar creation from visual observations, modeling physically plausible dynamics of humans with loose garments remains a challenging problem. Although a few existing works address this problem by leveraging physical simulation, they suffer from limited accuracy or robustness to novel animation inputs. In this work, we present MPMAvatar, a framework for creating 3D human avatars from multi-view videos that supports highly realistic, robust animation, as well as photorealistic rendering from free viewpoints. For accurate and robust dynamics modeling, our key idea is to use a Material Point Method-based simulator, which we carefully tailor to model garments with complex deformations and contact with the underlying body by incorporating an anisotropic constitutive model and a novel collision handling algorithm. We combine this dynamics modeling scheme with our canonical avatar that can be rendered using 3D Gaussian Splatting with quasi-shadowing, enabling high-fidelity rendering for physically realistic animations. In our experiments, we demonstrate that MPMAvatar significantly outperforms the existing state-of-the-art physics-based avatar in terms of (1) dynamics modeling accuracy, (2) rendering accuracy, and (3) robustness and efficiency. Additionally, we present a novel application in which our avatar generalizes to unseen interactions in a zero-shot manner-which was not achievable with previous learning-based methods due to their limited simulation generalizability. Our project page is at: https://KAISTChangmin.github.io/MPMAvatar/
Affordance-Guided Diffusion Prior for 3D Hand Reconstruction
Oct 01, 2025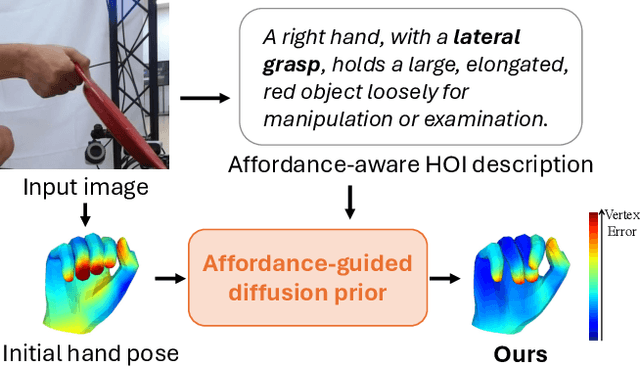
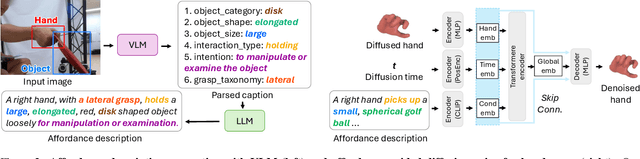
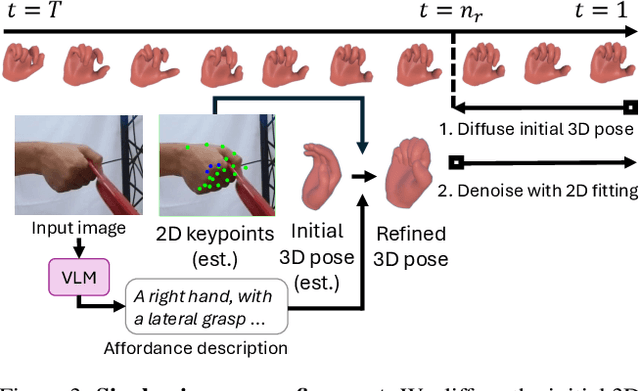
How can we reconstruct 3D hand poses when large portions of the hand are heavily occluded by itself or by objects? Humans often resolve such ambiguities by leveraging contextual knowledge -- such as affordances, where an object's shape and function suggest how the object is typically grasped. Inspired by this observation, we propose a generative prior for hand pose refinement guided by affordance-aware textual descriptions of hand-object interactions (HOI). Our method employs a diffusion-based generative model that learns the distribution of plausible hand poses conditioned on affordance descriptions, which are inferred from a large vision-language model (VLM). This enables the refinement of occluded regions into more accurate and functionally coherent hand poses. Extensive experiments on HOGraspNet, a 3D hand-affordance dataset with severe occlusions, demonstrate that our affordance-guided refinement significantly improves hand pose estimation over both recent regression methods and diffusion-based refinement lacking contextual reasoning.
PicPersona-TOD : A Dataset for Personalizing Utterance Style in Task-Oriented Dialogue with Image Persona
Apr 24, 2025
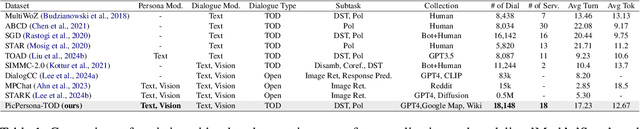

Task-Oriented Dialogue (TOD) systems are designed to fulfill user requests through natural language interactions, yet existing systems often produce generic, monotonic responses that lack individuality and fail to adapt to users' personal attributes. To address this, we introduce PicPersona-TOD, a novel dataset that incorporates user images as part of the persona, enabling personalized responses tailored to user-specific factors such as age or emotional context. This is facilitated by first impressions, dialogue policy-guided prompting, and the use of external knowledge to reduce hallucinations. Human evaluations confirm that our dataset enhances user experience, with personalized responses contributing to a more engaging interaction. Additionally, we introduce a new NLG model, Pictor, which not only personalizes responses, but also demonstrates robust performance across unseen domains https://github.com/JihyunLee1/PicPersona.
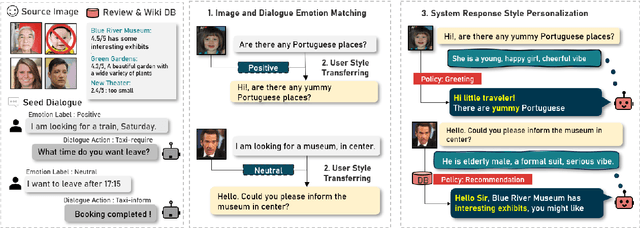
Mirror: Multimodal Cognitive Reframing Therapy for Rolling with Resistance
Apr 16, 2025
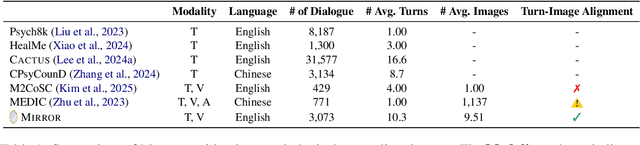
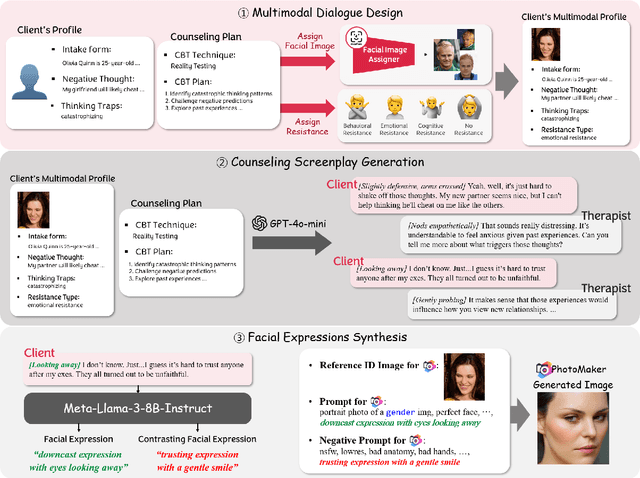
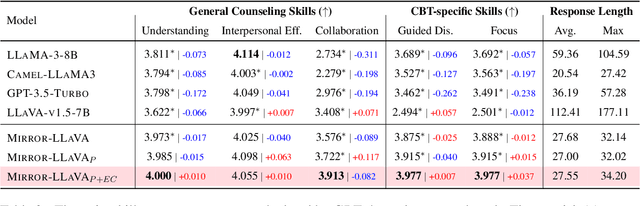
Recent studies have explored the use of large language models (LLMs) in psychotherapy; however, text-based cognitive behavioral therapy (CBT) models often struggle with client resistance, which can weaken therapeutic alliance. To address this, we propose a multimodal approach that incorporates nonverbal cues, allowing the AI therapist to better align its responses with the client's negative emotional state. Specifically, we introduce a new synthetic dataset, Multimodal Interactive Rolling with Resistance (Mirror), which is a novel synthetic dataset that pairs client statements with corresponding facial images. Using this dataset, we train baseline Vision-Language Models (VLMs) that can analyze facial cues, infer emotions, and generate empathetic responses to effectively manage resistance. They are then evaluated in terms of both the therapist's counseling skills and the strength of the therapeutic alliance in the presence of client resistance. Our results demonstrate that Mirror significantly enhances the AI therapist's ability to handle resistance, which outperforms existing text-based CBT approaches.
REWIND: Real-Time Egocentric Whole-Body Motion Diffusion with Exemplar-Based Identity Conditioning
Apr 08, 2025We present REWIND (Real-Time Egocentric Whole-Body Motion Diffusion), a one-step diffusion model for real-time, high-fidelity human motion estimation from egocentric image inputs. While an existing method for egocentric whole-body (i.e., body and hands) motion estimation is non-real-time and acausal due to diffusion-based iterative motion refinement to capture correlations between body and hand poses, REWIND operates in a fully causal and real-time manner. To enable real-time inference, we introduce (1) cascaded body-hand denoising diffusion, which effectively models the correlation between egocentric body and hand motions in a fast, feed-forward manner, and (2) diffusion distillation, which enables high-quality motion estimation with a single denoising step. Our denoising diffusion model is based on a modified Transformer architecture, designed to causally model output motions while enhancing generalizability to unseen motion lengths. Additionally, REWIND optionally supports identity-conditioned motion estimation when identity prior is available. To this end, we propose a novel identity conditioning method based on a small set of pose exemplars of the target identity, which further enhances motion estimation quality. Through extensive experiments, we demonstrate that REWIND significantly outperforms the existing baselines both with and without exemplar-based identity conditioning.
ORIGEN: Zero-Shot 3D Orientation Grounding in Text-to-Image Generation
Mar 28, 2025We introduce ORIGEN, the first zero-shot method for 3D orientation grounding in text-to-image generation across multiple objects and diverse categories. While previous work on spatial grounding in image generation has mainly focused on 2D positioning, it lacks control over 3D orientation. To address this, we propose a reward-guided sampling approach using a pretrained discriminative model for 3D orientation estimation and a one-step text-to-image generative flow model. While gradient-ascent-based optimization is a natural choice for reward-based guidance, it struggles to maintain image realism. Instead, we adopt a sampling-based approach using Langevin dynamics, which extends gradient ascent by simply injecting random noise--requiring just a single additional line of code. Additionally, we introduce adaptive time rescaling based on the reward function to accelerate convergence. Our experiments show that ORIGEN outperforms both training-based and test-time guidance methods across quantitative metrics and user studies.
Keyword-Aware ASR Error Augmentation for Robust Dialogue State Tracking
Sep 10, 2024



Dialogue State Tracking (DST) is a key part of task-oriented dialogue systems, identifying important information in conversations. However, its accuracy drops significantly in spoken dialogue environments due to named entity errors from Automatic Speech Recognition (ASR) systems. We introduce a simple yet effective data augmentation method that targets those entities to improve the robustness of DST model. Our novel method can control the placement of errors using keyword-highlighted prompts while introducing phonetically similar errors. As a result, our method generated sufficient error patterns on keywords, leading to improved accuracy in noised and low-accuracy ASR environments.