 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded Diffusion Framework for Probabilistic Coarse-to-Fine Hand Pose Estimation
Oct 01, 2025



Deterministic models for 3D hand pose reconstruction, whether single-staged or cascaded, struggle with pose ambiguities caused by self-occlusions and complex hand articulations. Existing cascaded approaches refine predictions in a coarse-to-fine manner but remain deterministic and cannot capture pose uncertainties. Recent probabilistic methods model pose distributions yet are restricted to single-stage estimation, which often fails to produce accurate 3D reconstructions without refinement. To address these limitations, we propose a coarse-to-fine cascaded diffusion framework that combines probabilistic modeling with cascaded refinement. The first stage is a joint diffusion model that samples diverse 3D joint hypotheses, and the second stage is a Mesh Latent Diffusion Model (Mesh LDM) that reconstructs a 3D hand mesh conditioned on a joint sample. By training Mesh LDM with diverse joint hypotheses in a learned latent space, our framework learns distribution-aware joint-mesh relationships and robust hand priors. Furthermore, the cascaded design mitigates the difficulty of directly mapping 2D images to dense 3D poses, enhancing accuracy through sequential refinement. Experiments on FreiHAND and HO3Dv2 demonstrate that our method achieves state-of-the-art performance while effectively modeling pose distributions.
Hand-object reconstruction via interaction-aware graph attention mechanism
Sep 26, 2024



Estimating the poses of both a hand and an object has become an important area of research due to the growing need for advanced vision computing. The primary challenge involves understanding and reconstructing how hands and objects interact, such as contact and physical plausibility. Existing approaches often adopt a graph neural network to incorporate spatial information of hand and object meshes. However, these approaches have not fully exploited the potential of graphs without modification of edges within and between hand- and object-graphs. We propose a graph-based refinement method that incorporates an interaction-aware graph-attention mechanism to account for hand-object interactions. Using edges, we establish connections among closely correlated nodes, both within individual graphs and across different graphs. Experiments demonstrate the effectiveness of our proposed method with notable improvements in the realm of physical plausibility.
Dense Hand-Object(HO) GraspNet with Full Grasping Taxonomy and Dynamics
Sep 06, 2024
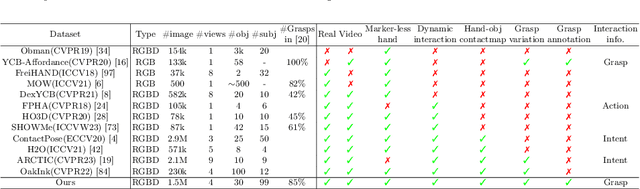
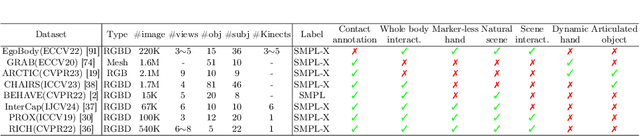
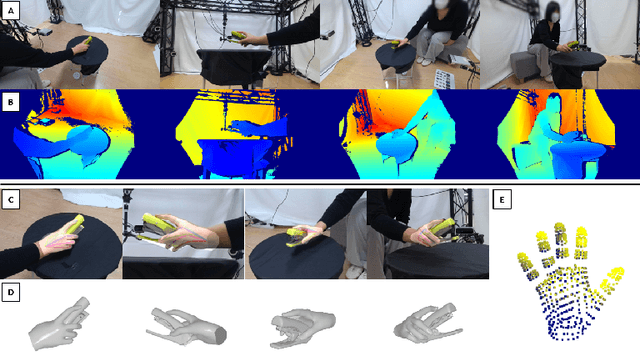
Existing datasets for 3D hand-object interaction are limited either in the data cardinality, data variations in interaction scenarios, or the quality of annotations. In this work, we present a comprehensive new training dataset for hand-object interaction called HOGraspNet. It is the only real dataset that captures full grasp taxonomies, providing grasp annotation and wide intraclass variations. Using grasp taxonomies as atomic actions, their space and time combinatorial can represent complex hand activities around objects. We select 22 rigid objects from the YCB dataset and 8 other compound objects using shape and size taxonomies, ensuring coverage of all hand grasp configurations. The dataset includes diverse hand shapes from 99 participants aged 10 to 74, continuous video frames, and a 1.5M RGB-Depth of sparse frames with annotations. It offers labels for 3D hand and object meshes, 3D keypoints, contact maps, and \emph{grasp labels}. Accurate hand and object 3D meshes are obtained by fitting the hand parametric model (MANO) and the hand implicit function (HALO) to multi-view RGBD frames, with the MoCap system only for objects. Note that HALO fitting does not require any parameter tuning, enabling scalability to the dataset's size with comparable accuracy to MANO. We evaluate HOGraspNet on relevant tasks: grasp classification and 3D hand pose estimation. The result shows performance variations based on grasp type and object class, indicating the potential importance of the interaction space captured by our dataset. The provided data aims at learning universal shape priors or foundation models for 3D hand-object interaction. Our dataset and code are available at https://hograspnet2024.github.io/.