 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInt3DNet: Scene-Motion Cross Attention Network for 3D Intention Prediction in Mixed Reality
Mar 09, 2026We propose Int3DNet, a scene-aware network that predicts 3D intention areas directly from scene geometry and head-hand motion cues, enabling robust human intention prediction without explicit object-level perception. In Mixed Reality (MR), intention prediction is critical as it enables the system to anticipate user actions and respond proactively, reducing interaction delays and ensuring seamless user experiences. Our method employs a cross attention fusion of sparse motion cues and scene point clouds, offering a novel approach that directly interprets the user's spatial intention within the scene. We evaluated Int3DNet on MoGaze and CIRCLE datasets, which are public datasets for full-body human-scene interactions, showing consistent performance across time horizons of up to 1500 ms and outperforming the baselines, even in diverse and unseen scenes. Moreover, we demonstrate the usability of proposed method through a demonstration of efficient visual question answering (VQA) based on intention areas. Int3DNet provides reliable 3D intention areas derived from head-hand motion and scene geometry, thus enabling seamless interaction between humans and MR systems through proactive processing of intention areas.
SceneLinker: Compositional 3D Scene Generation via Semantic Scene Graph from RGB Sequences
Feb 03, 2026We introduce SceneLinker, a novel framework that generates compositional 3D scenes via semantic scene graph from RGB sequences. To adaptively experience Mixed Reality (MR) content based on each user's space, it is essential to generate a 3D scene that reflects the real-world layout by compactly capturing the semantic cues of the surroundings. Prior works struggled to fully capture the contextual relationship between objects or mainly focused on synthesizing diverse shapes, making it challenging to generate 3D scenes aligned with object arrangements. We address these challenges by designing a graph network with cross-check feature attention for scene graph prediction and constructing a graph-variational autoencoder (graph-VAE), which consists of a joint shape and layout block for 3D scene generation. Experiments on the 3RScan/3DSSG and SG-FRONT datasets demonstrate that our approach outperforms state-of-the-art methods in both quantitative and qualitative evaluations, even in complex indoor environments and under challenging scene graph constraints. Our work enables users to generate consistent 3D spaces from their physical environments via scene graphs, allowing them to create spatial MR content. Project page is https://scenelinker2026.github.io.
VRGaussianAvatar: Integrating 3D Gaussian Avatars into VR
Feb 02, 2026We present VRGaussianAvatar, an integrated system that enables real-time full-body 3D Gaussian Splatting (3DGS) avatars in virtual reality using only head-mounted display (HMD) tracking signals. The system adopts a parallel pipeline with a VR Frontend and a GA Backend. The VR Frontend uses inverse kinematics to estimate full-body pose and streams the resulting pose along with stereo camera parameters to the backend. The GA Backend stereoscopically renders a 3DGS avatar reconstructed from a single image. To improve stereo rendering efficiency, we introduce Binocular Batching, which jointly processes left and right eye views in a single batched pass to reduce redundant computation and support high-resolution VR displays. We evaluate VRGaussianAvatar with quantitative performance tests and a within-subject user study against image- and video-based mesh avatar baselines. Results show that VRGaussianAvatar sustains interactive VR performance and yields higher perceived appearance similarity, embodiment, and plausibility. Project page and source code are available at https://vrgaussianavatar.github.io.
Fast Texture Transfer for XR Avatars via Barycentric UV Conversion
Aug 27, 2025
We present a fast and efficient method for transferring facial textures onto SMPL-X-based full-body avatars. Unlike conventional affine-transform methods that are slow and prone to visual artifacts, our method utilizes a barycentric UV conversion technique. Our approach precomputes the entire UV mapping into a single transformation matrix, enabling texture transfer in a single operation. This results in a speedup of over 7000x compared to the baseline, while also significantly improving the final texture quality by eliminating boundary artifacts. Through quantitative and qualitative evaluations, we demonstrate that our method offers a practical solution for personalization in immersive XR applications. The code is available online.
LLM Meets Scene Graph: Can Large Language Models Understand and Generate Scene Graphs? A Benchmark and Empirical Study
May 26, 2025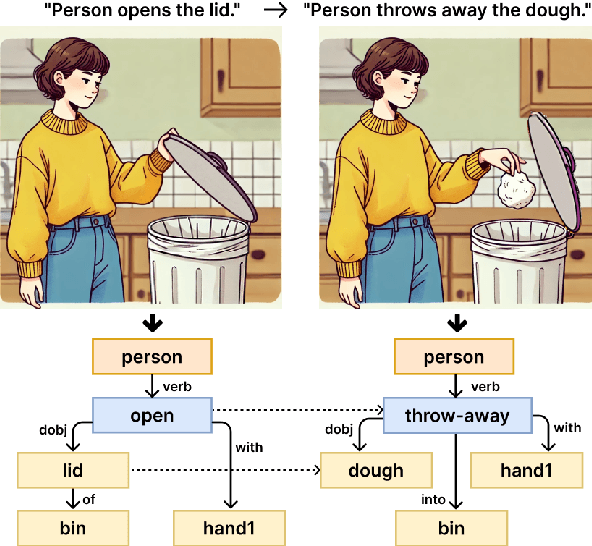

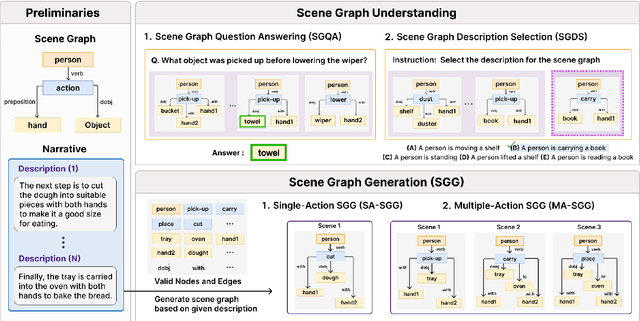

The remarkable reasoning and generalization capabilities of Large Language Models (LLMs) have paved the way for their expanding applications in embodied AI, robotics, and other real-world tasks. To effectively support these applications, grounding in spatial and temporal understanding in multimodal environments is essential. To this end, recent works have leveraged scene graphs, a structured representation that encodes entities, attributes, and their relationships in a scene. However, a comprehensive evaluation of LLMs' ability to utilize scene graphs remains limited. In this work, we introduce Text-Scene Graph (TSG) Bench, a benchmark designed to systematically assess LLMs' ability to (1) understand scene graphs and (2) generate them from textual narratives. With TSG Bench we evaluate 11 LLMs and reveal that, while models perform well on scene graph understanding, they struggle with scene graph generation, particularly for complex narratives. Our analysis indicates that these models fail to effectively decompose discrete scenes from a complex narrative, leading to a bottleneck when generating scene graphs. These findings underscore the need for improved methodologies in scene graph generation and provide valuable insights for future research. The demonstration of our benchmark is available at https://tsg-bench.netlify.app. Additionally, our code and evaluation data are publicly available at https://anonymous.4open.science/r/TSG-Bench.
S3D: Sketch-Driven 3D Model Generation
May 07, 2025Generating high-quality 3D models from 2D sketches is a challenging task due to the inherent ambiguity and sparsity of sketch data. In this paper, we present S3D, a novel framework that converts simple hand-drawn sketches into detailed 3D models. Our method utilizes a U-Net-based encoder-decoder architecture to convert sketches into face segmentation masks, which are then used to generate a 3D representation that can be rendered from novel views. To ensure robust consistency between the sketch domain and the 3D output, we introduce a novel style-alignment loss that aligns the U-Net bottleneck features with the initial encoder outputs of the 3D generation module, significantly enhancing reconstruction fidelity. To further enhance the network's robustness, we apply augmentation techniques to the sketch dataset. This streamlined framework demonstrates the effectiveness of S3D in generating high-quality 3D models from sketch inputs. The source code for this project is publicly available at https://github.com/hailsong/S3D.
Dense Hand-Object(HO) GraspNet with Full Grasping Taxonomy and Dynamics
Sep 06, 2024
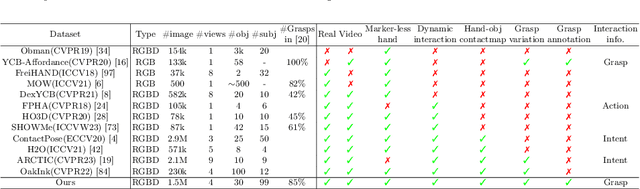
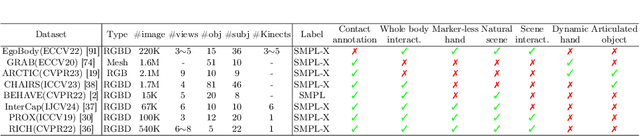
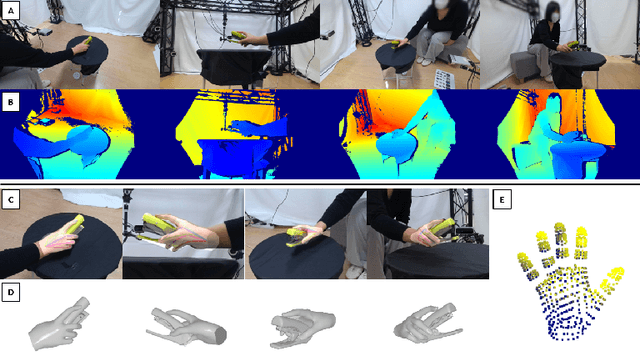
Existing datasets for 3D hand-object interaction are limited either in the data cardinality, data variations in interaction scenarios, or the quality of annotations. In this work, we present a comprehensive new training dataset for hand-object interaction called HOGraspNet. It is the only real dataset that captures full grasp taxonomies, providing grasp annotation and wide intraclass variations. Using grasp taxonomies as atomic actions, their space and time combinatorial can represent complex hand activities around objects. We select 22 rigid objects from the YCB dataset and 8 other compound objects using shape and size taxonomies, ensuring coverage of all hand grasp configurations. The dataset includes diverse hand shapes from 99 participants aged 10 to 74, continuous video frames, and a 1.5M RGB-Depth of sparse frames with annotations. It offers labels for 3D hand and object meshes, 3D keypoints, contact maps, and \emph{grasp labels}. Accurate hand and object 3D meshes are obtained by fitting the hand parametric model (MANO) and the hand implicit function (HALO) to multi-view RGBD frames, with the MoCap system only for objects. Note that HALO fitting does not require any parameter tuning, enabling scalability to the dataset's size with comparable accuracy to MANO. We evaluate HOGraspNet on relevant tasks: grasp classification and 3D hand pose estimation. The result shows performance variations based on grasp type and object class, indicating the potential importance of the interaction space captured by our dataset. The provided data aims at learning universal shape priors or foundation models for 3D hand-object interaction. Our dataset and code are available at https://hograspnet2024.github.io/.
eCAR: edge-assisted Collaborative Augmented Reality Framework
May 11, 2024



We propose a novel edge-assisted multi-user collaborative augmented reality framework in a large indoor environment. In Collaborative Augmented Reality, data communication that synchronizes virtual objects has large network traffic and high network latency. Due to drift, CAR applications without continuous data communication for coordinate system alignment have virtual object inconsistency. In addition, synchronization messages for online virtual object updates have high latency as the number of collaborative devices increases. To solve this problem, we implement the CAR framework, called eCAR, which utilizes edge computing to continuously match the device's coordinate system with less network traffic. Furthermore, we extend the co-visibility graph of the edge server to maintain virtual object spatial-temporal consistency in neighboring devices by synchronizing a local graph. We evaluate the system quantitatively and qualitatively in the public dataset and a physical indoor environment. eCAR communicates data for coordinate system alignment between the edge server and devices with less network traffic and latency. In addition, collaborative augmented reality synchronization algorithms quickly and accurately host and resolve virtual objects. The proposed system continuously aligns coordinate systems to multiple devices in a large indoor environment and shares augmented reality content. Through our system, users interact with virtual objects and share augmented reality experiences with neighboring users.
Seg&Struct: The Interplay Between Part Segmentation and Structure Inference for 3D Shape Parsing
Nov 01, 2022
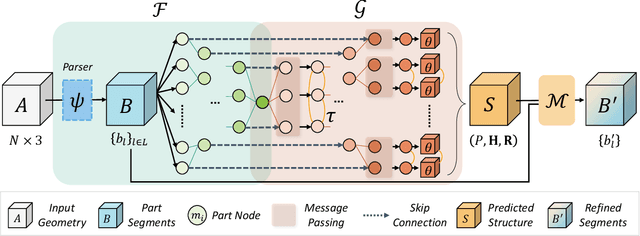
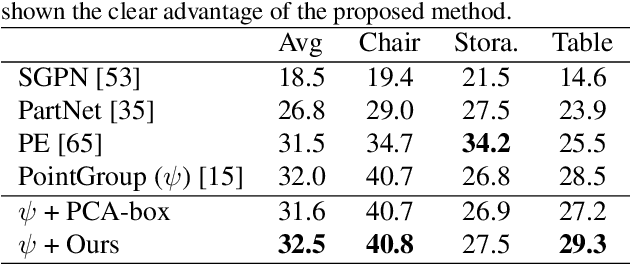
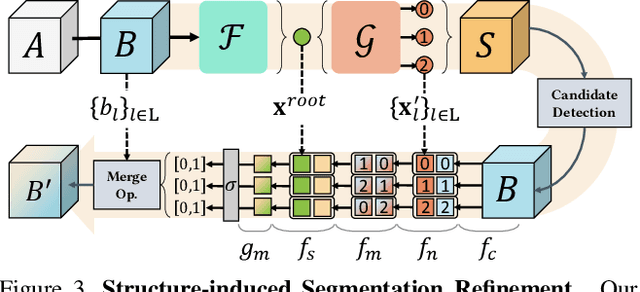
We propose Seg&Struct, a supervised learning framework leveraging the interplay between part segmentation and structure inference and demonstrating their synergy in an integrated framework. Both part segmentation and structure inference have been extensively studied in the recent deep learning literature, while the supervisions used for each task have not been fully exploited to assist the other task. Namely, structure inference has been typically conducted with an autoencoder that does not leverage the point-to-part associations. Also, segmentation has been mostly performed without structural priors that tell the plausibility of the output segments. We present how these two tasks can be best combined while fully utilizing supervision to improve performance. Our framework first decomposes a raw input shape into part segments using an off-the-shelf algorithm, whose outputs are then mapped to nodes in a part hierarchy, establishing point-to-part associations. Following this, ours predicts the structural information, e.g., part bounding boxes and part relationships. Lastly, the segmentation is rectified by examining the confusion of part boundaries using the structure-based part features. Our experimental results based on the StructureNet and PartNet demonstrate that the interplay between the two tasks results in remarkable improvements in both tasks: 27.91% in structure inference and 0.5% in segmentation.