 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM-SLAM: Dense Monocular SLAM via Adaptive and Informative Multi-View Keyframe Prioritization with Foundation Model
Mar 05, 2026Recent advances in geometric foundation models have emerged as a promising alternative for addressing the challenge of dense reconstruction in monocular visual simultaneous localization and mapping (SLAM). Although geometric foundation models enable SLAM to leverage variable input views, the previous methods remain confined to two-view pairs or fixed-length inputs without sufficient deliberation of geometric context for view selection. To tackle this problem, we propose AIM-SLAM, a dense monocular SLAM framework that exploits an adaptive and informative multi-view keyframe prioritization with dense pointmap predictions from visual geometry grounded transformer (VGGT). Specifically, we introduce the selective information- and geometric-aware multi-view adaptation (SIGMA) module, which employs voxel overlap and information gain to retrieve a candidate set of keyframes and adaptively determine its size. Furthermore, we formulate a joint multi-view Sim(3) optimization that enforces consistent alignment across selected views, substantially improving pose estimation accuracy. The effectiveness of AIM-SLAM is demonstrated on real-world datasets, where it achieves state-of-the-art performance in both pose estimation and dense reconstruction. Our system supports ROS integration, with code is available at https://aimslam.github.io/.
uCLIP: Parameter-Efficient Multilingual Extension of Vision-Language Models with Unpaired Data
Nov 17, 2025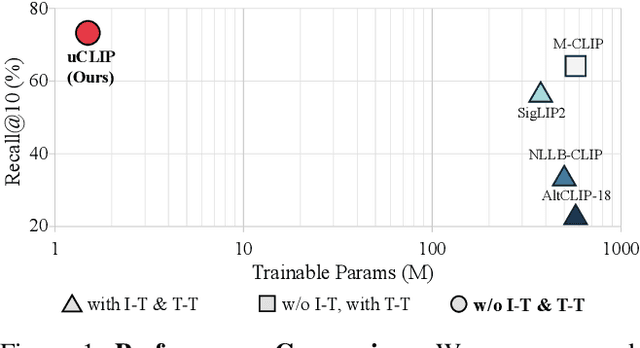
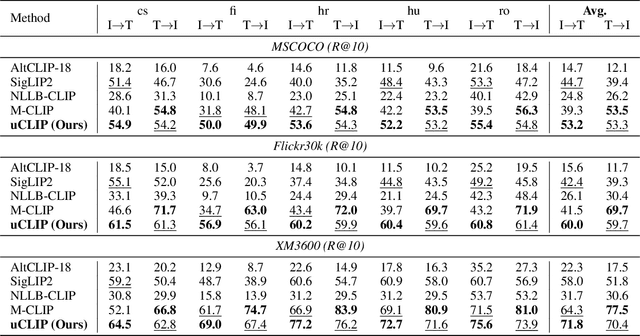
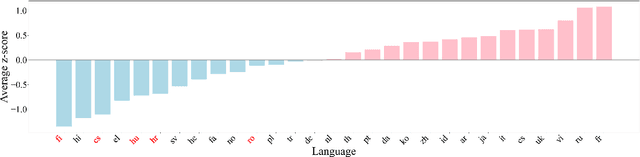
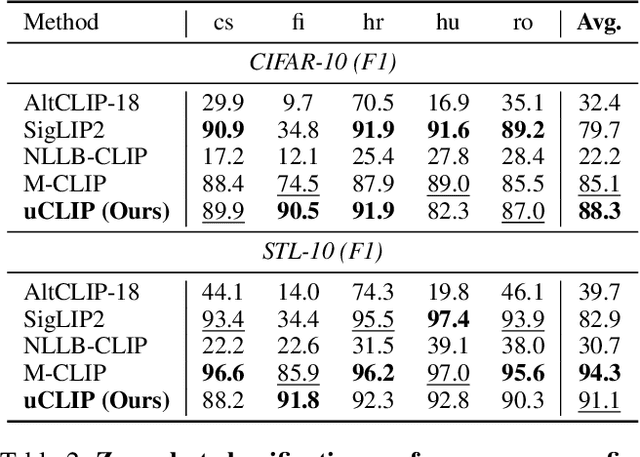
Contrastive Language-Image Pre-training (CLIP) has demonstrated strong generalization across a wide range of visual tasks by leveraging large-scale English-image pairs. However, its extension to low-resource languages remains limited due to the scarcity of high-quality multilingual image-text data. Existing multilingual vision-language models exhibit consistently low retrieval performance in underrepresented languages including Czech, Finnish, Croatian, Hungarian, and Romanian on the Crossmodal-3600 (XM3600) benchmark. To address this, we propose a lightweight and data-efficient framework for multilingual vision-language alignment. Our approach requires no image-text pairs or text-text pairs and freezes both the pretrained image encoder and multilingual text encoder during training. Only a compact 1.7M-parameter projection module is trained, using a contrastive loss over English representations as semantic anchors. This minimal training setup enables robust multilingual alignment even for languages with limited supervision. Extensive evaluation across multiple multilingual retrieval benchmarks confirms the effectiveness of our method, showing significant gains in five underrepresented languages where existing models typically underperform. These findings highlight the effectiveness of our pivot-based, parameter-efficient alignment strategy for inclusive multimodal learning.
eCAR: edge-assisted Collaborative Augmented Reality Framework
May 11, 2024



We propose a novel edge-assisted multi-user collaborative augmented reality framework in a large indoor environment. In Collaborative Augmented Reality, data communication that synchronizes virtual objects has large network traffic and high network latency. Due to drift, CAR applications without continuous data communication for coordinate system alignment have virtual object inconsistency. In addition, synchronization messages for online virtual object updates have high latency as the number of collaborative devices increases. To solve this problem, we implement the CAR framework, called eCAR, which utilizes edge computing to continuously match the device's coordinate system with less network traffic. Furthermore, we extend the co-visibility graph of the edge server to maintain virtual object spatial-temporal consistency in neighboring devices by synchronizing a local graph. We evaluate the system quantitatively and qualitatively in the public dataset and a physical indoor environment. eCAR communicates data for coordinate system alignment between the edge server and devices with less network traffic and latency. In addition, collaborative augmented reality synchronization algorithms quickly and accurately host and resolve virtual objects. The proposed system continuously aligns coordinate systems to multiple devices in a large indoor environment and shares augmented reality content. Through our system, users interact with virtual objects and share augmented reality experiences with neighboring users.
Struct-MDC: Mesh-Refined Unsupervised Depth Completion Leveraging Structural Regularities from Visual SLAM
Apr 29, 2022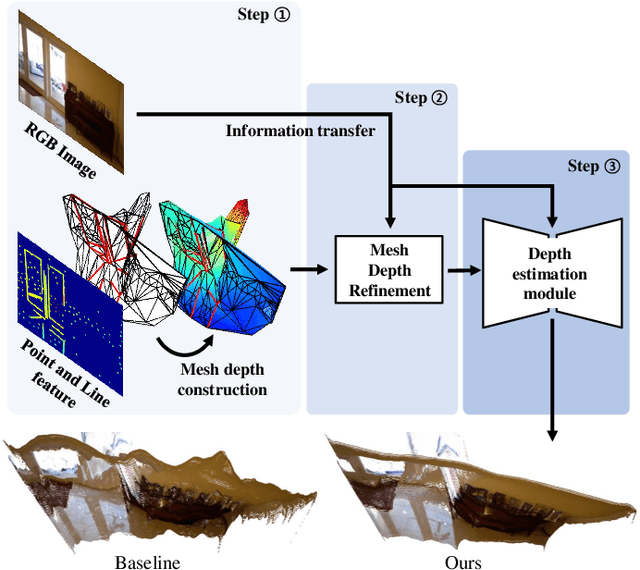

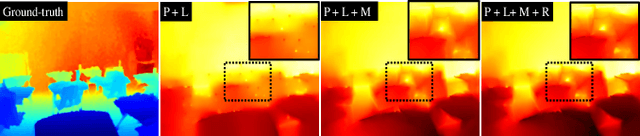
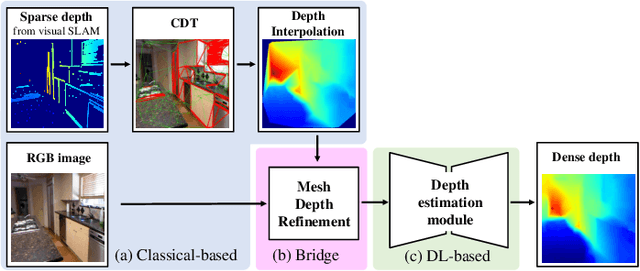
Feature-based visual simultaneous localization and mapping (SLAM) methods only estimate the depth of extracted features, generating a sparse depth map. To solve this sparsity problem, depth completion tasks that estimate a dense depth from a sparse depth have gained significant importance in robotic applications like exploration. Existing methodologies that use sparse depth from visual SLAM mainly employ point features. However, point features have limitations in preserving structural regularities owing to texture-less environments and sparsity problems. To deal with these issues, we perform depth completion with visual SLAM using line features, which can better contain structural regularities than point features. The proposed methodology creates a convex hull region by performing constrained Delaunay triangulation with depth interpolation using line features. However, the generated depth includes low-frequency information and is discontinuous at the convex hull boundary. Therefore, we propose a mesh depth refinement (MDR) module to address this problem. The MDR module effectively transfers the high-frequency details of an input image to the interpolated depth and plays a vital role in bridging the conventional and deep learning-based approaches. The Struct-MDC outperforms other state-of-the-art algorithms on public and our custom datasets, and even outperforms supervised methodologies for some metrics. In addition, the effectiveness of the proposed MDR module is verified by a rigorous ablation study.
UV-SLAM: Unconstrained Line-based SLAM Using Vanishing Points for Structural Mapping
Dec 27, 2021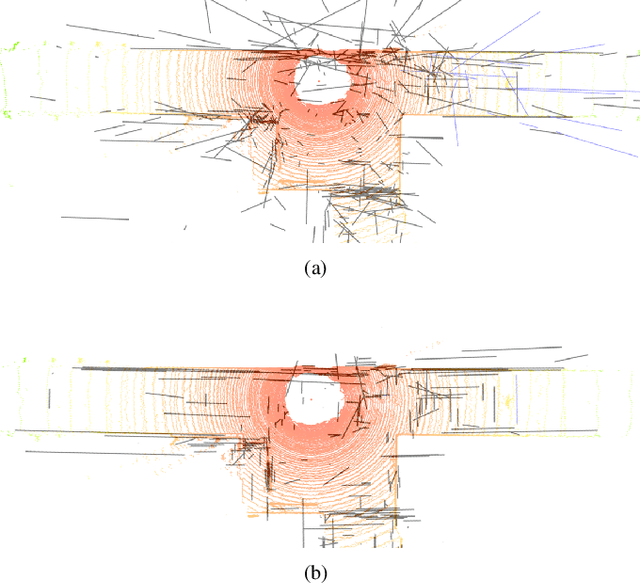
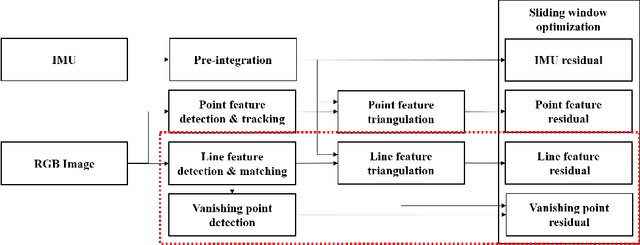
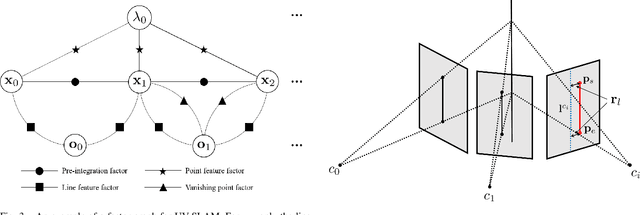

In feature-based simultaneous localization and mapping (SLAM), line features complement the sparsity of point features, making it possible to map the surrounding environment structure. Existing approaches utilizing line features have primarily employed a measurement model that uses line re-projection. However, the direction vectors used in the 3D line mapping process cannot be corrected because the line measurement model employs only the lines' normal vectors in the Pl\"{u}cker coordinate. As a result, problems like degeneracy that occur during the 3D line mapping process cannot be solved. To tackle the problem, this paper presents a UV-SLAM, which is an unconstrained line-based SLAM using vanishing points for structural mapping. This paper focuses on using structural regularities without any constraints, such as the Manhattan world assumption. For this, we use the vanishing points that can be obtained from the line features. The difference between the vanishing point observation calculated through line features in the image and the vanishing point estimation calculated through the direction vector is defined as a residual and added to the cost function of optimization-based SLAM. Furthermore, through Fisher information matrix rank analysis, we prove that vanishing point measurements guarantee a unique mapping solution. Finally, we demonstrate that the localization accuracy and mapping quality are improved compared to the state-of-the-art algorithms using public datasets.
Gradient Inversion with Generative Image Prior
Oct 28, 2021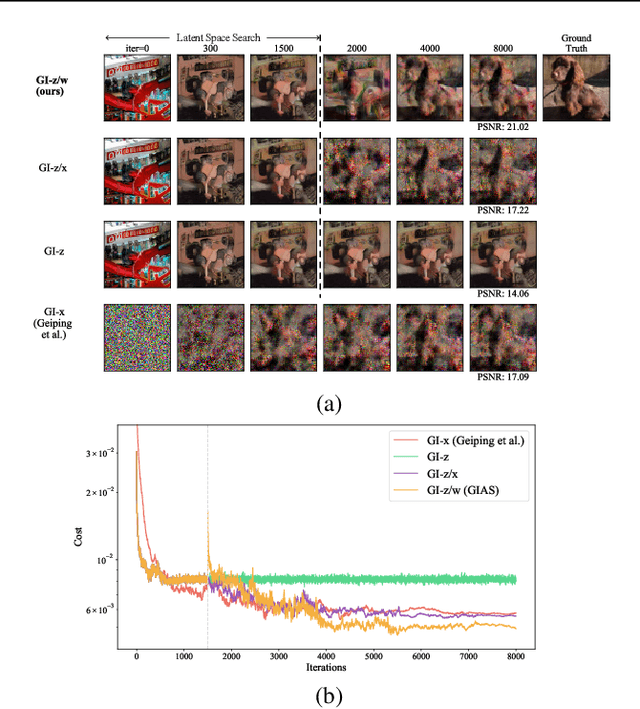

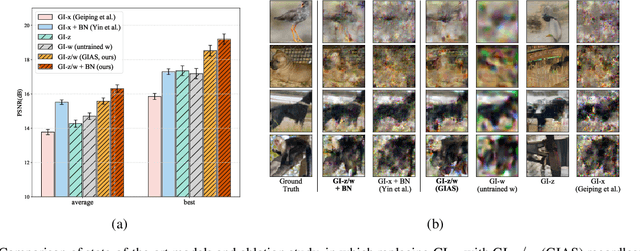
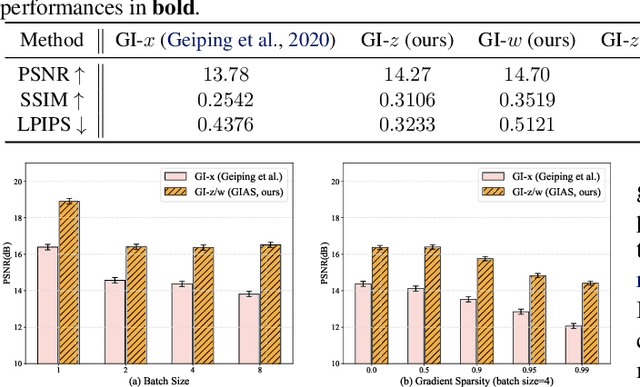
Federated Learning (FL) is a distributed learning framework, in which the local data never leaves clients devices to preserve privacy, and the server trains models on the data via accessing only the gradients of those local data. Without further privacy mechanisms such as differential privacy, this leaves the system vulnerable against an attacker who inverts those gradients to reveal clients sensitive data. However, a gradient is often insufficient to reconstruct the user data without any prior knowledge. By exploiting a generative model pretrained on the data distribution, we demonstrate that data privacy can be easily breached. Further, when such prior knowledge is unavailable, we investigate the possibility of learning the prior from a sequence of gradients seen in the process of FL training. We experimentally show that the prior in a form of generative model is learnable from iterative interactions in FL. Our findings strongly suggest that additional mechanisms are necessary to prevent privacy leakage in FL.
Run Your Visual-Inertial Odometry on NVIDIA Jetson: Benchmark Tests on a Micro Aerial Vehicle
Mar 02, 2021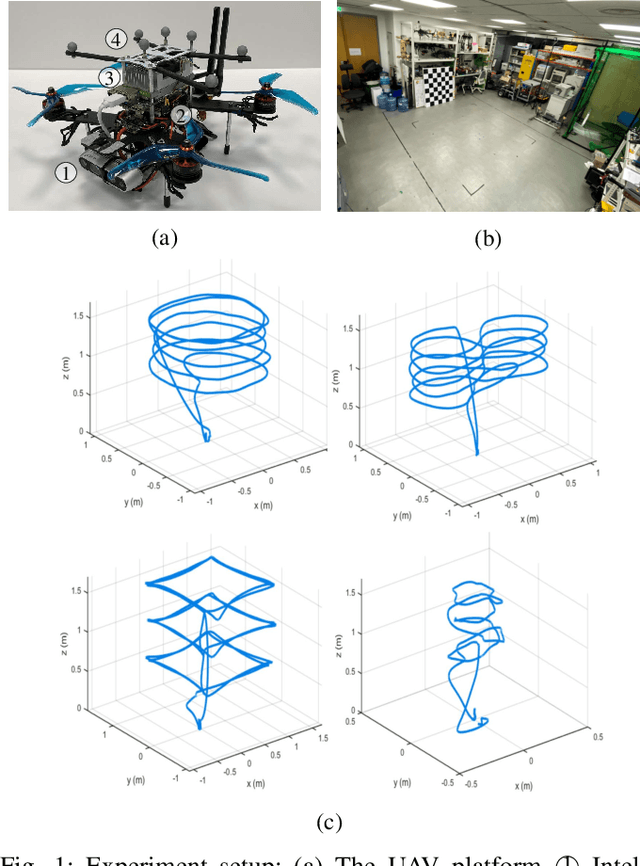

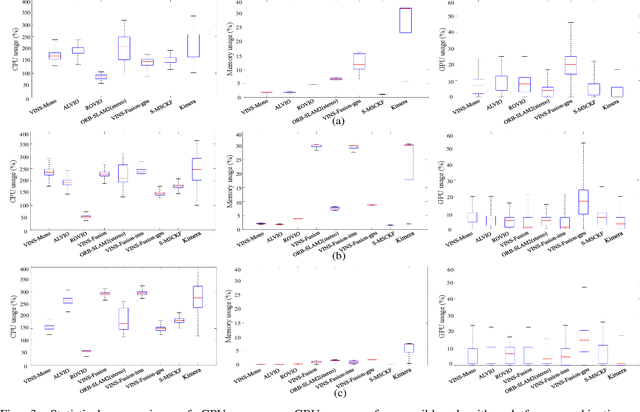
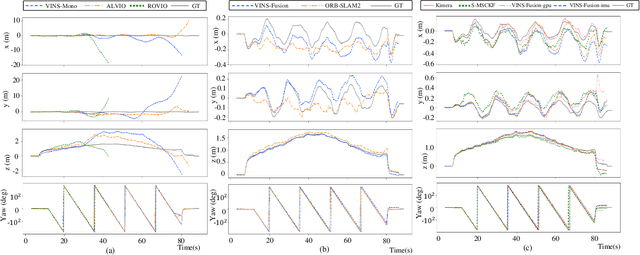
This paper presents benchmark tests of various visual(-inertial) odometry algorithms on NVIDIA Jetson platforms. The compared algorithms include mono and stereo, covering Visual Odometry (VO) and Visual-Inertial Odometry (VIO): VINS-Mono, VINS-Fusion, Kimera, ALVIO, Stereo-MSCKF, ORB-SLAM2 stereo, and ROVIO. As these methods are mainly used for unmanned aerial vehicles (UAVs), they must perform well in situations where the size of the processing board and weight is limited. Jetson boards released by NVIDIA satisfy these constraints as they have a sufficiently powerful central processing unit (CPU) and graphics processing unit (GPU) for image processing. However, in existing studies, the performance of Jetson boards as a processing platform for executing VO/VIO has not been compared extensively in terms of the usage of computing resources and accuracy. Therefore, this study compares representative VO/VIO algorithms on several NVIDIA Jetson platforms, namely NVIDIA Jetson TX2, Xavier NX, and AGX Xavier, and introduces a novel dataset 'KAIST VIO dataset' for UAVs. Including pure rotations, the dataset has several geometric trajectories that are harsh to visual(-inertial) state estimation. The evaluation is performed in terms of the accuracy of estimated odometry, CPU usage, and memory usage on various Jetson boards, algorithms, and trajectories. We present the {results of the} comprehensive benchmark test and release the dataset for the computer vision and robotics applications.