 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Faithful Agentic XAI: A Verification Method and an Open-World Benchmark for Better Model Faithfulness
May 27, 2026Explainable AI (XAI) helps users interpret model behavior and identify potential faults. Agentic XAI systems use Large Language Models (LLMs) to make explanations more accessible through natural-language interaction, but they can also produce plausible yet unfaithful explanations. This risk arises because unreliable XAI outputs for complex models can be amplified by LLMs and mislead users. We propose Faithful Agentic XAI (FAX), a framework that improves explanation faithfulness through explicit verification. FAX decomposes draft explanations into claims and cross-checks them against inherently faithful tools, filtering unsupported or contradictory claims before final generation. We also introduce CRAFTER-XAI-Bench, an open-world reinforcement learning benchmark with complex policies, diverse goals, and challenging scenarios for assessing model-specific faithfulness. On CRAFTER-XAI-Bench, FAX improves simulation faithfulness from 0.20 for the strongest baseline to 0.46 while maintaining high informativeness, relevance, and fluency. On three tabular benchmarks, FAX performs competitively with prior Agentic XAI baselines, but our analysis shows that these settings can conflate task accuracy with model-specific faithfulness. These findings show that explicit verification is essential for faithful Agentic XAI and that that faithfulness benchmarks must be designed to test explanations against the behavior of the target model itself.
Visual Prompt Discovery via Semantic Exploration
Mar 17, 2026LVLMs encounter significant challenges in image understanding and visual reasoning, leading to critical perception failures. Visual prompts, which incorporate image manipulation code, have shown promising potential in mitigating these issues. While emerged as a promising direction, previous methods for visual prompt generation have focused on tool selection rather than diagnosing and mitigating the root causes of LVLM perception failures. Because of the opacity and unpredictability of LVLMs, optimal visual prompts must be discovered through empirical experiments, which have relied on manual human trial-and-error. We propose an automated semantic exploration framework for discovering task-wise visual prompts. Our approach enables diverse yet efficient exploration through agent-driven experiments, minimizing human intervention and avoiding the inefficiency of per-sample generation. We introduce a semantic exploration algorithm named SEVEX, which addresses two major challenges of visual prompt exploration: (1) the distraction caused by lengthy, low-level code and (2) the vast, unstructured search space of visual prompts. Specifically, our method leverages an abstract idea space as a search space, a novelty-guided selection algorithm, and a semantic feedback-driven ideation process to efficiently explore diverse visual prompts based on empirical results. We evaluate SEVEX on the BlindTest and BLINK benchmarks, which are designed to assess LVLM perception. Experimental results demonstrate that SEVEX significantly outperforms baseline methods in task accuracy, inference efficiency, exploration efficiency, and exploration stability. Notably, our framework discovers sophisticated and counter-intuitive visual strategies that go beyond conventional tool usage, offering a new paradigm for enhancing LVLM perception through automated, task-wise visual prompts.
Semantic Exploration with Adaptive Gating for Efficient Problem Solving with Language Models
Jan 10, 2025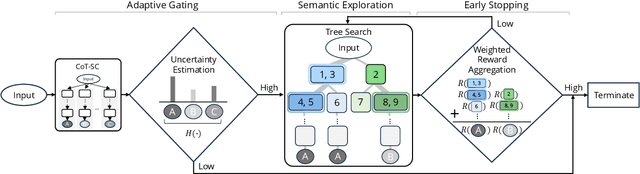
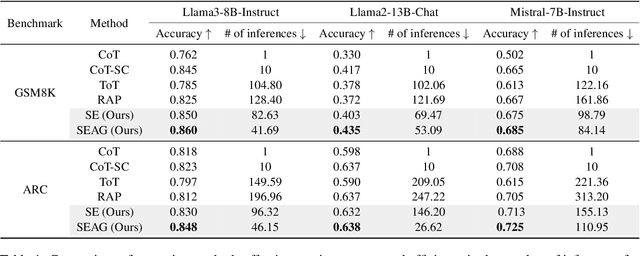
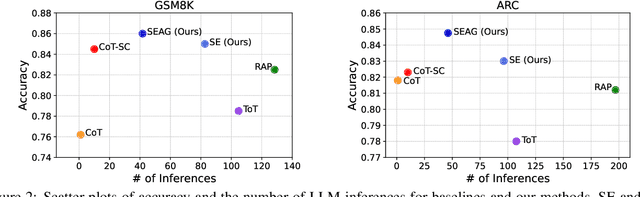
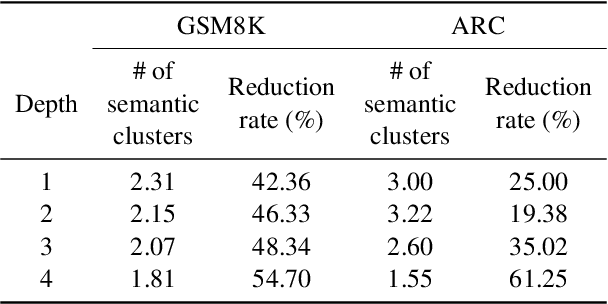
Recent advancements in large language models (LLMs) have shown remarkable potential in various complex tasks requiring multi-step reasoning methods like tree search to explore diverse reasoning paths. However, existing methods often suffer from computational inefficiency and redundancy. First, they overlook the diversity of task difficulties, leading to unnecessarily extensive searches even for easy tasks. Second, they neglect the semantics of reasoning paths, resulting in redundant exploration of semantically identical paths. To address these limitations, we propose Semantic Exploration with Adaptive Gating (SEAG), a computationally efficient method. SEAG employs an adaptive gating mechanism that dynamically decides whether to conduct a tree search, based on the confidence level of answers from a preceding simple reasoning method. Furthermore, its tree-based exploration consolidates semantically identical reasoning steps, reducing redundant explorations while maintaining or even improving accuracy. Our extensive experiments demonstrate that SEAG significantly improves accuracy by 4.3% on average while requiring only 31% of computational costs compared to existing tree search-based methods on complex reasoning benchmarks including GSM8K and ARC with diverse language models such as Llama2, Llama3, and Mistral.
Active Prompt Learning with Vision-Language Model Priors
Nov 23, 2024



Vision-language models (VLMs) have demonstrated remarkable zero-shot performance across various classification tasks. Nonetheless, their reliance on hand-crafted text prompts for each task hinders efficient adaptation to new tasks. While prompt learning offers a promising solution, most studies focus on maximizing the utilization of given few-shot labeled datasets, often overlooking the potential of careful data selection strategies, which enable higher accuracy with fewer labeled data. This motivates us to study a budget-efficient active prompt learning framework. Specifically, we introduce a class-guided clustering that leverages the pre-trained image and text encoders of VLMs, thereby enabling our cluster-balanced acquisition function from the initial round of active learning. Furthermore, considering the substantial class-wise variance in confidence exhibited by VLMs, we propose a budget-saving selective querying based on adaptive class-wise thresholds. Extensive experiments in active learning scenarios across nine datasets demonstrate that our method outperforms existing baselines.
Bridging the Gap between Expert and Language Models: Concept-guided Chess Commentary Generation and Evaluation
Oct 28, 2024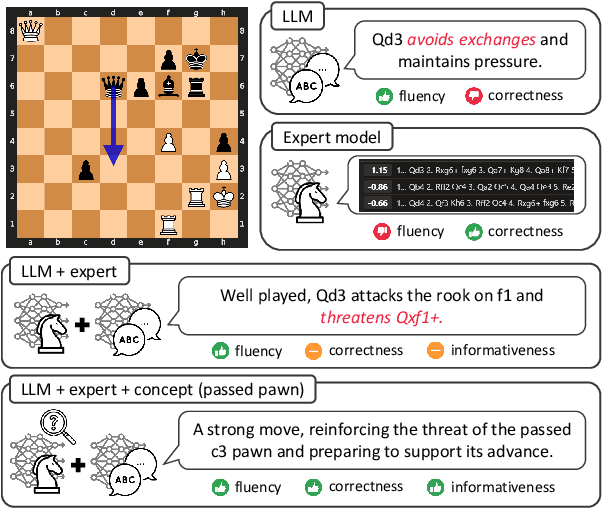
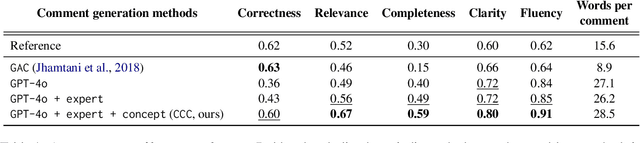
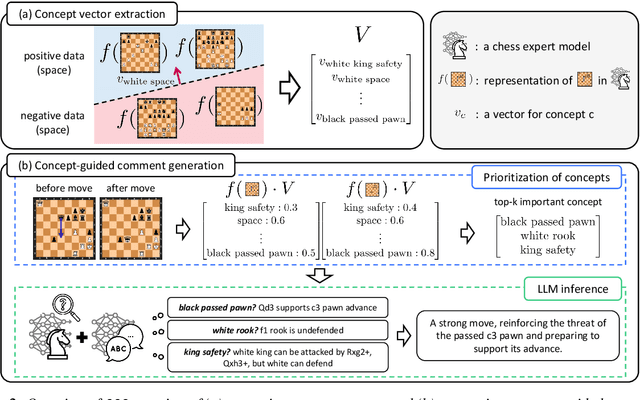
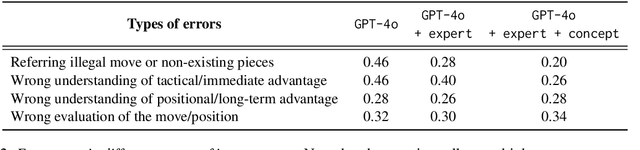
Deep learning-based expert models have reached superhuman performance in decision-making domains such as chess and Go. However, it is under-explored to explain or comment on given decisions although it is important for human education and model explainability. The outputs of expert models are accurate, but yet difficult to interpret for humans. On the other hand, large language models (LLMs) produce fluent commentary but are prone to hallucinations due to their limited decision-making capabilities. To bridge this gap between expert models and LLMs, we focus on chess commentary as a representative case of explaining complex decision-making processes through language and address both the generation and evaluation of commentary. We introduce Concept-guided Chess Commentary generation (CCC) for producing commentary and GPT-based Chess Commentary Evaluation (GCC-Eval) for assessing it. CCC integrates the decision-making strengths of expert models with the linguistic fluency of LLMs through prioritized, concept-based explanations. GCC-Eval leverages expert knowledge to evaluate chess commentary based on informativeness and linguistic quality. Experimental results, validated by both human judges and GCC-Eval, demonstrate that CCC generates commentary that is accurate, informative, and fluent.
Activity-Guided Industrial Anomalous Sound Detection against Interferences
Sep 03, 2024
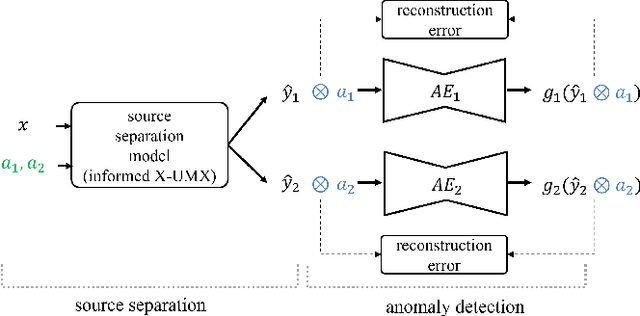
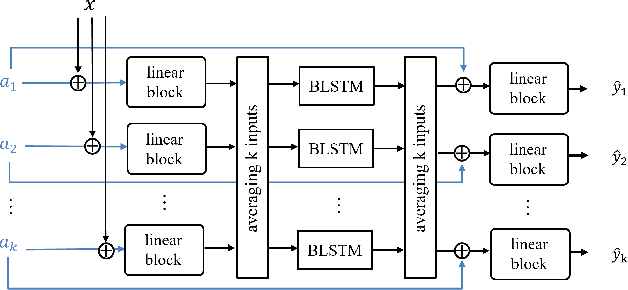
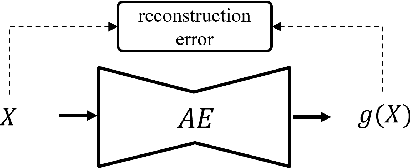
We address a practical scenario of anomaly detection for industrial sound data, where the sound of a target machine is corrupted by background noise and interference from neighboring machines. Overcoming this challenge is difficult since the interference is often virtually indistinguishable from the target machine without additional information. To address the issue, we propose SSAD, a framework of source separation (SS) followed by anomaly detection (AD), which leverages machine activity information, often readily available in practical settings. SSAD consists of two components: (i) activity-informed SS, enabling effective source separation even given interference with similar timbre, and (ii) two-step masking, robustifying anomaly detection by emphasizing anomalies aligned with the machine activity. Our experiments demonstrate that SSAD achieves comparable accuracy to a baseline with full access to clean signals, while SSAD is provided only a corrupted signal and activity information. In addition, thanks to the activity-informed SS and AD with the two-step masking, SSAD outperforms standard approaches, particularly in cases with interference. It highlights the practical efficacy of SSAD in addressing the complexities of anomaly detection in industrial sound data.
Addressing Feature Imbalance in Sound Source Separation
Sep 11, 2023Neural networks often suffer from a feature preference problem, where they tend to overly rely on specific features to solve a task while disregarding other features, even if those neglected features are essential for the task. Feature preference problems have primarily been investigated in classification task. However, we observe that feature preference occurs in high-dimensional regression task, specifically, source separation. To mitigate feature preference in source separation, we propose FEAture BAlancing by Suppressing Easy feature (FEABASE). This approach enables efficient data utilization by learning hidden information about the neglected feature. We evaluate our method in a multi-channel source separation task, where feature preference between spatial feature and timbre feature appears.
Learning Continuous Representation of Audio for Arbitrary Scale Super Resolution
Oct 30, 2021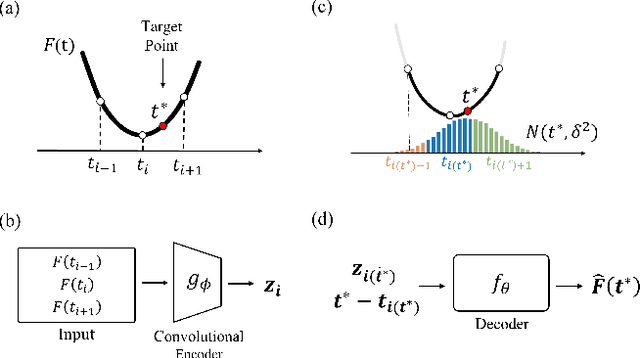
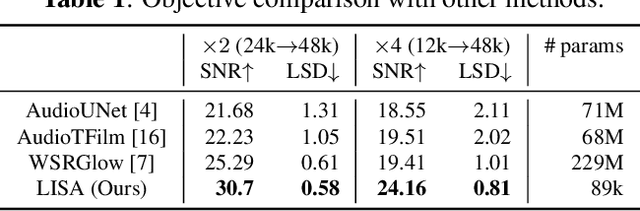
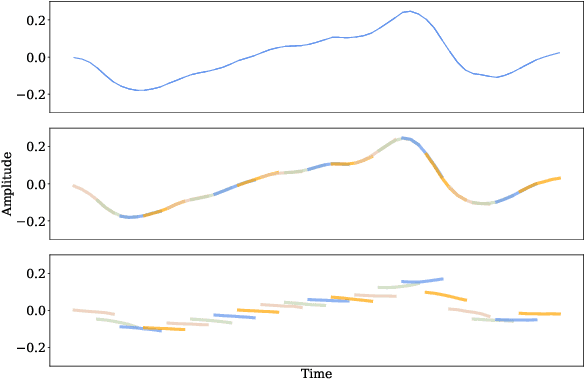
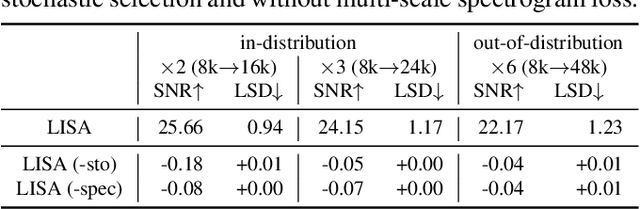
Audio super resolution aims to predict the missing high resolution components of the low resolution audio signals. While audio in nature is continuous signal, current approaches treat it as discrete data (i.e., input is defined on discrete time domain), and consider the super resolution over fixed scale factor (i.e., it is required to train a new neural network to change output resolution). To obtain a continuous representation of audio and enable super resolution for arbitrary scale factor, we propose a method of neural implicit representation, coined Local Implicit representation for Super resolution of Arbitrary scale (LISA). Our method locally parameterizes a chunk of audio as a function of continuous time, and represents each chunk with the local latent codes of neighboring chunks so that the function can extrapolate the signal at any time coordinate, i.e., infinite resolution. To learn a continuous representation for audio, we design a self-supervised learning strategy to practice super resolution tasks up to the original resolution by stochastic selection. Our numerical evaluation shows that LISA outperforms the previous fixed-scale methods with a fraction of parameters, but also is capable of arbitrary scale super resolution even beyond the resolution of training data.
Gradient Inversion with Generative Image Prior
Oct 28, 2021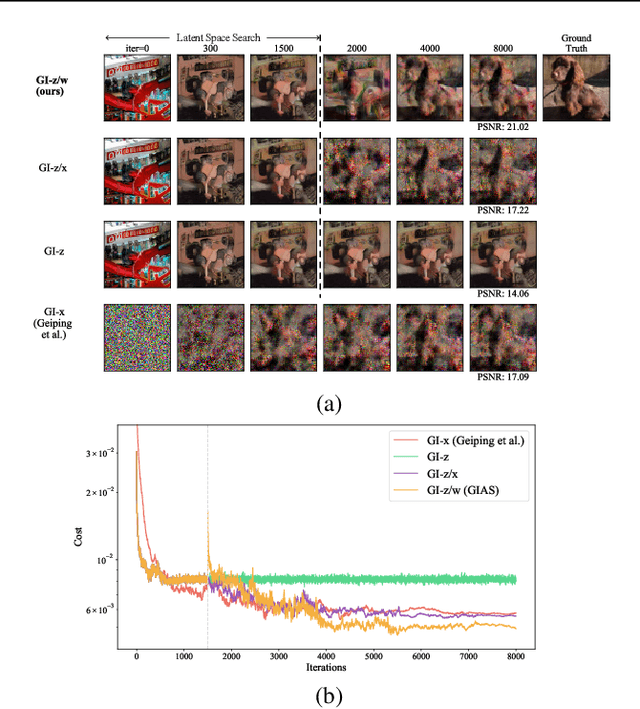

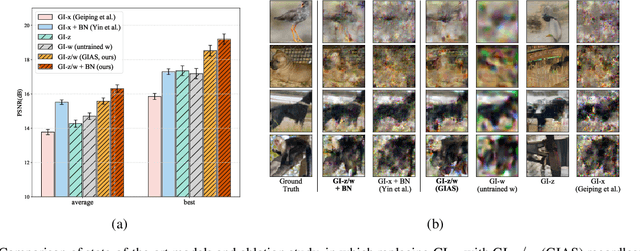
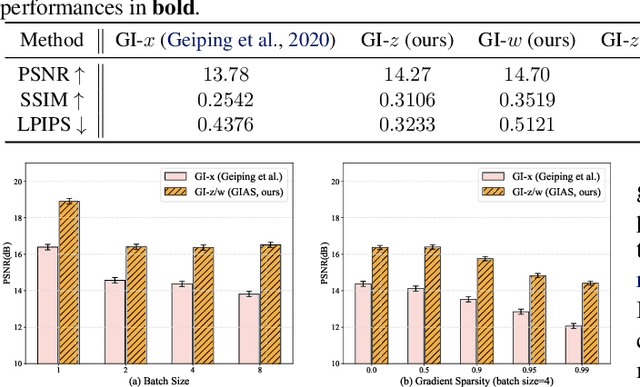
Federated Learning (FL) is a distributed learning framework, in which the local data never leaves clients devices to preserve privacy, and the server trains models on the data via accessing only the gradients of those local data. Without further privacy mechanisms such as differential privacy, this leaves the system vulnerable against an attacker who inverts those gradients to reveal clients sensitive data. However, a gradient is often insufficient to reconstruct the user data without any prior knowledge. By exploiting a generative model pretrained on the data distribution, we demonstrate that data privacy can be easily breached. Further, when such prior knowledge is unavailable, we investigate the possibility of learning the prior from a sequence of gradients seen in the process of FL training. We experimentally show that the prior in a form of generative model is learnable from iterative interactions in FL. Our findings strongly suggest that additional mechanisms are necessary to prevent privacy leakage in FL.