 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Continuous Representation of Audio for Arbitrary Scale Super Resolution
Paper and Code
Oct 30, 2021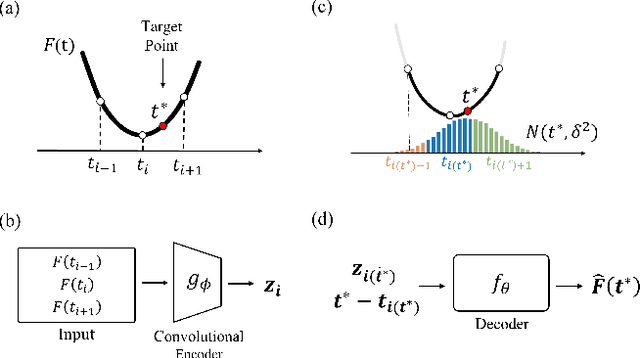
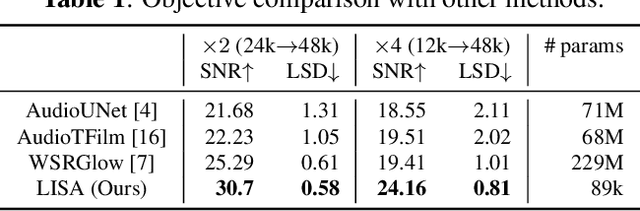
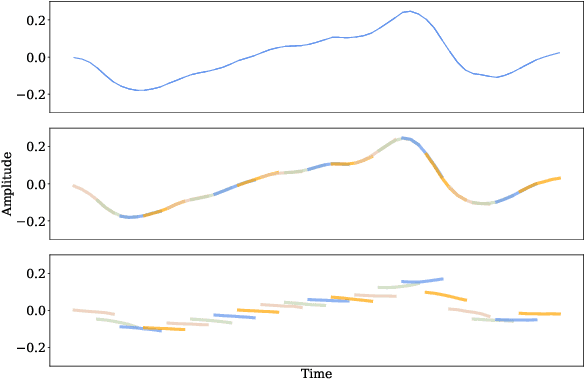
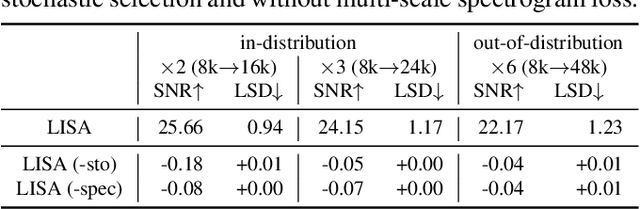
Audio super resolution aims to predict the missing high resolution components of the low resolution audio signals. While audio in nature is continuous signal, current approaches treat it as discrete data (i.e., input is defined on discrete time domain), and consider the super resolution over fixed scale factor (i.e., it is required to train a new neural network to change output resolution). To obtain a continuous representation of audio and enable super resolution for arbitrary scale factor, we propose a method of neural implicit representation, coined Local Implicit representation for Super resolution of Arbitrary scale (LISA). Our method locally parameterizes a chunk of audio as a function of continuous time, and represents each chunk with the local latent codes of neighboring chunks so that the function can extrapolate the signal at any time coordinate, i.e., infinite resolution. To learn a continuous representation for audio, we design a self-supervised learning strategy to practice super resolution tasks up to the original resolution by stochastic selection. Our numerical evaluation shows that LISA outperforms the previous fixed-scale methods with a fraction of parameters, but also is capable of arbitrary scale super resolution even beyond the resolution of training data.