 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivity-Guided Industrial Anomalous Sound Detection against Interferences
Sep 03, 2024
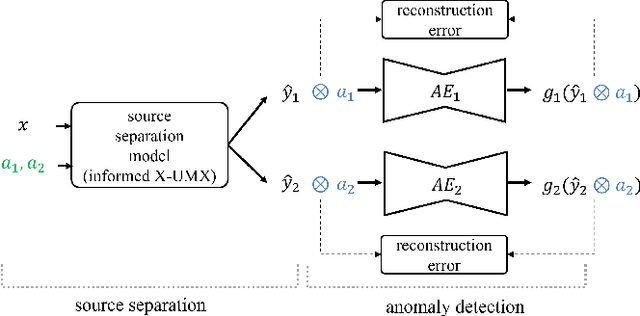
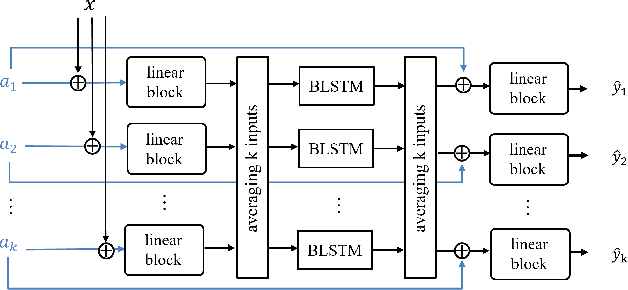
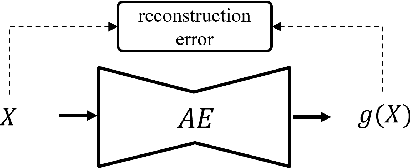
We address a practical scenario of anomaly detection for industrial sound data, where the sound of a target machine is corrupted by background noise and interference from neighboring machines. Overcoming this challenge is difficult since the interference is often virtually indistinguishable from the target machine without additional information. To address the issue, we propose SSAD, a framework of source separation (SS) followed by anomaly detection (AD), which leverages machine activity information, often readily available in practical settings. SSAD consists of two components: (i) activity-informed SS, enabling effective source separation even given interference with similar timbre, and (ii) two-step masking, robustifying anomaly detection by emphasizing anomalies aligned with the machine activity. Our experiments demonstrate that SSAD achieves comparable accuracy to a baseline with full access to clean signals, while SSAD is provided only a corrupted signal and activity information. In addition, thanks to the activity-informed SS and AD with the two-step masking, SSAD outperforms standard approaches, particularly in cases with interference. It highlights the practical efficacy of SSAD in addressing the complexities of anomaly detection in industrial sound data.
Learning Continuous Representation of Audio for Arbitrary Scale Super Resolution
Oct 30, 2021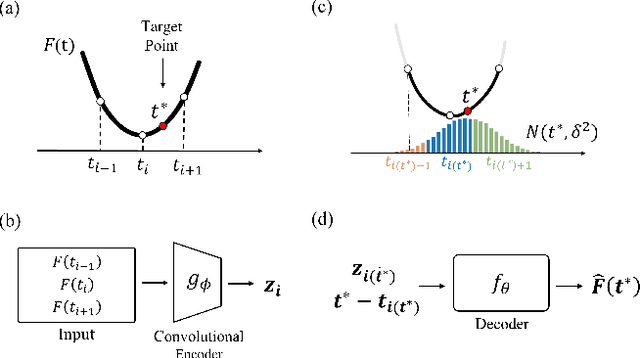
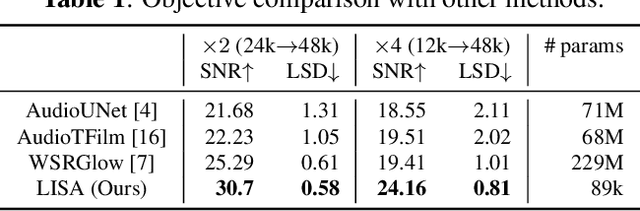
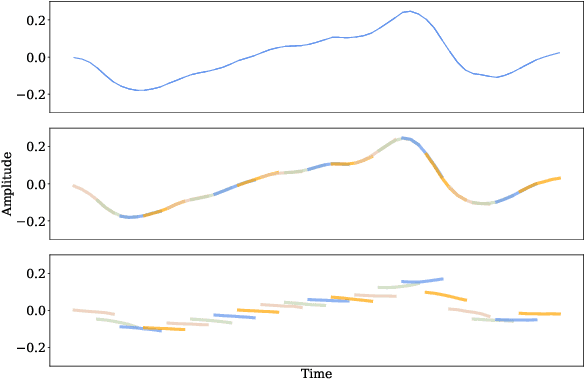
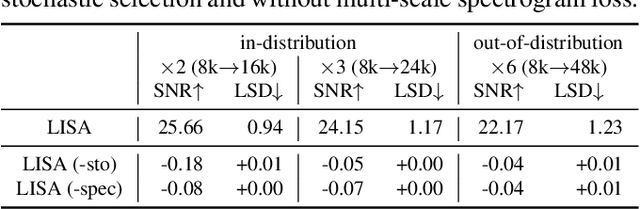
Audio super resolution aims to predict the missing high resolution components of the low resolution audio signals. While audio in nature is continuous signal, current approaches treat it as discrete data (i.e., input is defined on discrete time domain), and consider the super resolution over fixed scale factor (i.e., it is required to train a new neural network to change output resolution). To obtain a continuous representation of audio and enable super resolution for arbitrary scale factor, we propose a method of neural implicit representation, coined Local Implicit representation for Super resolution of Arbitrary scale (LISA). Our method locally parameterizes a chunk of audio as a function of continuous time, and represents each chunk with the local latent codes of neighboring chunks so that the function can extrapolate the signal at any time coordinate, i.e., infinite resolution. To learn a continuous representation for audio, we design a self-supervised learning strategy to practice super resolution tasks up to the original resolution by stochastic selection. Our numerical evaluation shows that LISA outperforms the previous fixed-scale methods with a fraction of parameters, but also is capable of arbitrary scale super resolution even beyond the resolution of training data.