 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap between Expert and Language Models: Concept-guided Chess Commentary Generation and Evaluation
Paper and Code
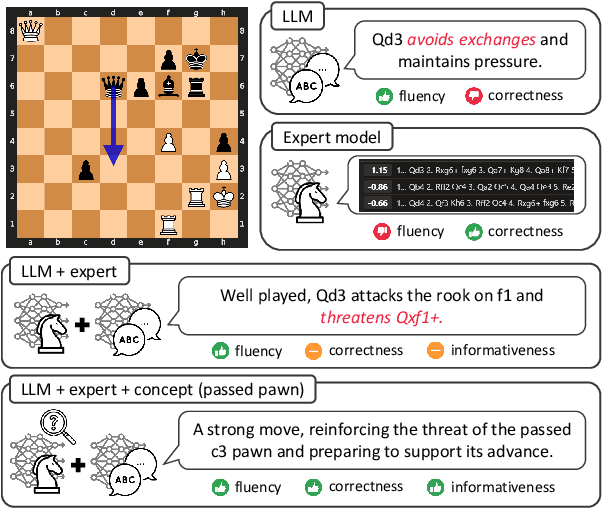
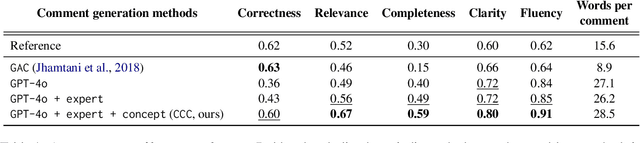
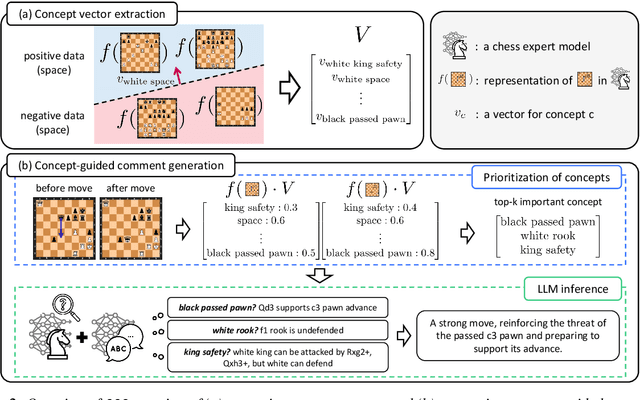
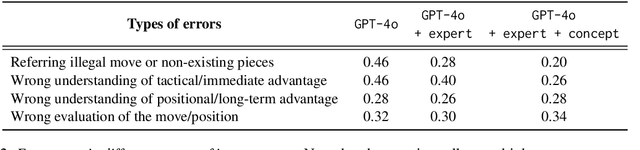
Deep learning-based expert models have reached superhuman performance in decision-making domains such as chess and Go. However, it is under-explored to explain or comment on given decisions although it is important for human education and model explainability. The outputs of expert models are accurate, but yet difficult to interpret for humans. On the other hand, large language models (LLMs) produce fluent commentary but are prone to hallucinations due to their limited decision-making capabilities. To bridge this gap between expert models and LLMs, we focus on chess commentary as a representative case of explaining complex decision-making processes through language and address both the generation and evaluation of commentary. We introduce Concept-guided Chess Commentary generation (CCC) for producing commentary and GPT-based Chess Commentary Evaluation (GCC-Eval) for assessing it. CCC integrates the decision-making strengths of expert models with the linguistic fluency of LLMs through prioritized, concept-based explanations. GCC-Eval leverages expert knowledge to evaluate chess commentary based on informativeness and linguistic quality. Experimental results, validated by both human judges and GCC-Eval, demonstrate that CCC generates commentary that is accurate, informative, and fluent.