 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-dimensional Preference Alignment by Conditioning Reward Itself
Dec 11, 2025Reinforcement Learning from Human Feedback has emerged as a standard for aligning diffusion models. However, we identify a fundamental limitation in the standard DPO formulation because it relies on the Bradley-Terry model to aggregate diverse evaluation axes like aesthetic quality and semantic alignment into a single scalar reward. This aggregation creates a reward conflict where the model is forced to unlearn desirable features of a specific dimension if they appear in a globally non-preferred sample. To address this issue, we propose Multi Reward Conditional DPO (MCDPO). This method resolves reward conflicts by introducing a disentangled Bradley-Terry objective. MCDPO explicitly injects a preference outcome vector as a condition during training, which allows the model to learn the correct optimization direction for each reward axis independently within a single network. We further introduce dimensional reward dropout to ensure balanced optimization across dimensions. Extensive experiments on Stable Diffusion 1.5 and SDXL demonstrate that MCDPO achieves superior performance on benchmarks. Notably, our conditional framework enables dynamic and multiple-axis control at inference time using Classifier Free Guidance to amplify specific reward dimensions without additional training or external reward models.
Targeted Data Protection for Diffusion Model by Matching Training Trajectory
Dec 11, 2025Recent advancements in diffusion models have made fine-tuning text-to-image models for personalization increasingly accessible, but have also raised significant concerns regarding unauthorized data usage and privacy infringement. Current protection methods are limited to passively degrading image quality, failing to achieve stable control. While Targeted Data Protection (TDP) offers a promising paradigm for active redirection toward user-specified target concepts, existing TDP attempts suffer from poor controllability due to snapshot-matching approaches that fail to account for complete learning dynamics. We introduce TAFAP (Trajectory Alignment via Fine-tuning with Adversarial Perturbations), the first method to successfully achieve effective TDP by controlling the entire training trajectory. Unlike snapshot-based methods whose protective influence is easily diluted as training progresses, TAFAP employs trajectory-matching inspired by dataset distillation to enforce persistent, verifiable transformations throughout fine-tuning. We validate our method through extensive experiments, demonstrating the first successful targeted transformation in diffusion models with simultaneous control over both identity and visual patterns. TAFAP significantly outperforms existing TDP attempts, achieving robust redirection toward target concepts while maintaining high image quality. This work enables verifiable safeguards and provides a new framework for controlling and tracing alterations in diffusion model outputs.
LoGoColor: Local-Global 3D Colorization for 360° Scenes
Dec 10, 2025



Single-channel 3D reconstruction is widely used in fields such as robotics and medical imaging. While this line of work excels at reconstructing 3D geometry, the outputs are not colored 3D models, thus 3D colorization is required for visualization. Recent 3D colorization studies address this problem by distilling 2D image colorization models. However, these approaches suffer from an inherent inconsistency of 2D image models. This results in colors being averaged during training, leading to monotonous and oversimplified results, particularly in complex 360° scenes. In contrast, we aim to preserve color diversity by generating a new set of consistently colorized training views, thereby bypassing the averaging process. Nevertheless, eliminating the averaging process introduces a new challenge: ensuring strict multi-view consistency across these colorized views. To achieve this, we propose LoGoColor, a pipeline designed to preserve color diversity by eliminating this guidance-averaging process with a `Local-Global' approach: we partition the scene into subscenes and explicitly tackle both inter-subscene and intra-subscene consistency using a fine-tuned multi-view diffusion model. We demonstrate that our method achieves quantitatively and qualitatively more consistent and plausible 3D colorization on complex 360° scenes than existing methods, and validate its superior color diversity using a novel Color Diversity Index.
Alignment-Aware Quantization for LLM Safety
Nov 11, 2025Safety and efficiency are both important factors when deploying large language models(LLMs). LLMs are trained to follow human alignment for safety, and post training quantization(PTQ) is applied afterward for efficiency. However, these two objectives are often in conflict, revealing a fundamental flaw in the conventional PTQ paradigm: quantization can turn into a safety vulnerability if it only aims to achieve low perplexity. Models can demonstrate low perplexity yet exhibit significant degradation in alignment with the safety policy, highlighting that perplexity alone is an insufficient and often misleading proxy for model safety. To address this, we propose Alignment-Aware Quantization(AAQ), a novel approach that integrates Alignment-Preserving Contrastive(APC) loss into the PTQ pipeline. Compared to simple reconstruction loss, ours explicitly preserves alignment by encouraging the quantized model to mimic its safe, instruction-tuned model while diverging from the unaligned, pre-trained counterpart. Our method achieves this robust safety alignment without resorting to specialized safety-focused calibration datasets, highlighting its practical utility and broad applicability. AAQ is compatible with standard PTQ techniques and enables robust 4-bit (W4A4) quantization across diverse model families such as LLaMA, Qwen, and Mistral while maintaining safety where previous methods fail. Our work resolves the critical trade-off between efficiency and safety, paving the way toward LLMs that are both efficient and trustworthy. Anonymized code is available in the supplementary material.
Style Composition within Distinct LoRA modules for Traditional Art
Jul 16, 2025Diffusion-based text-to-image models have achieved remarkable results in synthesizing diverse images from text prompts and can capture specific artistic styles via style personalization. However, their entangled latent space and lack of smooth interpolation make it difficult to apply distinct painting techniques in a controlled, regional manner, often causing one style to dominate. To overcome this, we propose a zero-shot diffusion pipeline that naturally blends multiple styles by performing style composition on the denoised latents predicted during the flow-matching denoising process of separately trained, style-specialized models. We leverage the fact that lower-noise latents carry stronger stylistic information and fuse them across heterogeneous diffusion pipelines using spatial masks, enabling precise, region-specific style control. This mechanism preserves the fidelity of each individual style while allowing user-guided mixing. Furthermore, to ensure structural coherence across different models, we incorporate depth-map conditioning via ControlNet into the diffusion framework. Qualitative and quantitative experiments demonstrate that our method successfully achieves region-specific style mixing according to the given masks.
ReFlex: Text-Guided Editing of Real Images in Rectified Flow via Mid-Step Feature Extraction and Attention Adaptation
Jul 02, 2025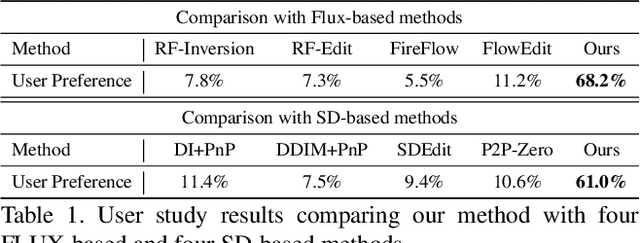

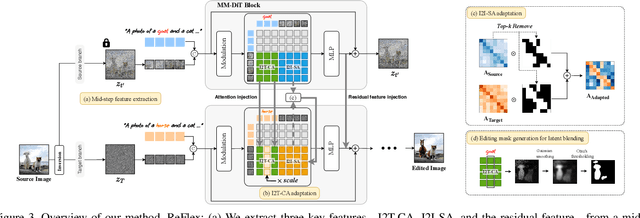

Rectified Flow text-to-image models surpass diffusion models in image quality and text alignment, but adapting ReFlow for real-image editing remains challenging. We propose a new real-image editing method for ReFlow by analyzing the intermediate representations of multimodal transformer blocks and identifying three key features. To extract these features from real images with sufficient structural preservation, we leverage mid-step latent, which is inverted only up to the mid-step. We then adapt attention during injection to improve editability and enhance alignment to the target text. Our method is training-free, requires no user-provided mask, and can be applied even without a source prompt. Extensive experiments on two benchmarks with nine baselines demonstrate its superior performance over prior methods, further validated by human evaluations confirming a strong user preference for our approach.
Understanding Differential Transformer Unchains Pretrained Self-Attentions
May 22, 2025Differential Transformer has recently gained significant attention for its impressive empirical performance, often attributed to its ability to perform noise canceled attention. However, precisely how differential attention achieves its empirical benefits remains poorly understood. Moreover, Differential Transformer architecture demands large-scale training from scratch, hindering utilization of open pretrained weights. In this work, we conduct an in-depth investigation of Differential Transformer, uncovering three key factors behind its success: (1) enhanced expressivity via negative attention, (2) reduced redundancy among attention heads, and (3) improved learning dynamics. Based on these findings, we propose DEX, a novel method to efficiently integrate the advantages of differential attention into pretrained language models. By reusing the softmax attention scores and adding a lightweight differential operation on the output value matrix, DEX effectively incorporates the key advantages of differential attention while remaining lightweight in both training and inference. Evaluations confirm that DEX substantially improves the pretrained LLMs across diverse benchmarks, achieving significant performance gains with minimal adaptation data (< 0.01\%).
S3D: Sketch-Driven 3D Model Generation
May 07, 2025Generating high-quality 3D models from 2D sketches is a challenging task due to the inherent ambiguity and sparsity of sketch data. In this paper, we present S3D, a novel framework that converts simple hand-drawn sketches into detailed 3D models. Our method utilizes a U-Net-based encoder-decoder architecture to convert sketches into face segmentation masks, which are then used to generate a 3D representation that can be rendered from novel views. To ensure robust consistency between the sketch domain and the 3D output, we introduce a novel style-alignment loss that aligns the U-Net bottleneck features with the initial encoder outputs of the 3D generation module, significantly enhancing reconstruction fidelity. To further enhance the network's robustness, we apply augmentation techniques to the sketch dataset. This streamlined framework demonstrates the effectiveness of S3D in generating high-quality 3D models from sketch inputs. The source code for this project is publicly available at https://github.com/hailsong/S3D.
Unlocking the Potential of Unlabeled Data in Semi-Supervised Domain Generalization
Mar 18, 2025We address the problem of semi-supervised domain generalization (SSDG), where the distributions of train and test data differ, and only a small amount of labeled data along with a larger amount of unlabeled data are available during training. Existing SSDG methods that leverage only the unlabeled samples for which the model's predictions are highly confident (confident-unlabeled samples), limit the full utilization of the available unlabeled data. To the best of our knowledge, we are the first to explore a method for incorporating the unconfident-unlabeled samples that were previously disregarded in SSDG setting. To this end, we propose UPCSC to utilize these unconfident-unlabeled samples in SSDG that consists of two modules: 1) Unlabeled Proxy-based Contrastive learning (UPC) module, treating unconfident-unlabeled samples as additional negative pairs and 2) Surrogate Class learning (SC) module, generating positive pairs for unconfident-unlabeled samples using their confusing class set. These modules are plug-and-play and do not require any domain labels, which can be easily integrated into existing approaches. Experiments on four widely used SSDG benchmarks demonstrate that our approach consistently improves performance when attached to baselines and outperforms competing plug-and-play methods. We also analyze the role of our method in SSDG, showing that it enhances class-level discriminability and mitigates domain gaps. The code is available at https://github.com/dongkwani/UPCSC.
A Revisit to the Decoder for Camouflaged Object Detection
Mar 18, 2025

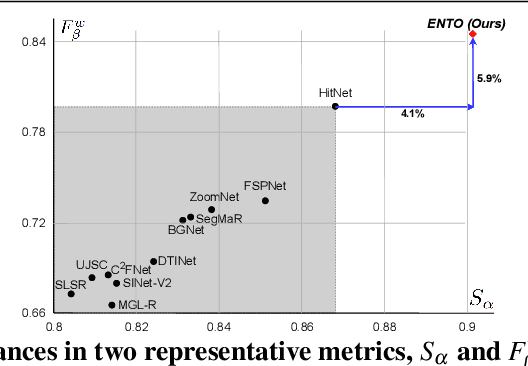
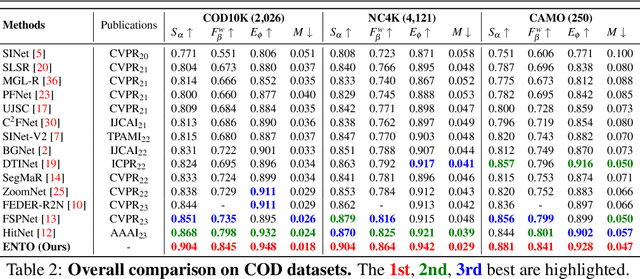
Camouflaged object detection (COD) aims to generate a fine-grained segmentation map of camouflaged objects hidden in their background. Due to the hidden nature of camouflaged objects, it is essential for the decoder to be tailored to effectively extract proper features of camouflaged objects and extra-carefully generate their complex boundaries. In this paper, we propose a novel architecture that augments the prevalent decoding strategy in COD with Enrich Decoder and Retouch Decoder, which help to generate a fine-grained segmentation map. Specifically, the Enrich Decoder amplifies the channels of features that are important for COD using channel-wise attention. Retouch Decoder further refines the segmentation maps by spatially attending to important pixels, such as the boundary regions. With extensive experiments, we demonstrate that ENTO shows superior performance using various encoders, with the two novel components playing their unique roles that are mutually complementary.
* Published in BMVC 2024, 13 pages, 7 figures (Appendix: 5 pages, 2 figures)