 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecompose the model: Mechanistic interpretability in image models with Generalized Integrated Gradients (GIG)
Paper and Code
Sep 03, 2024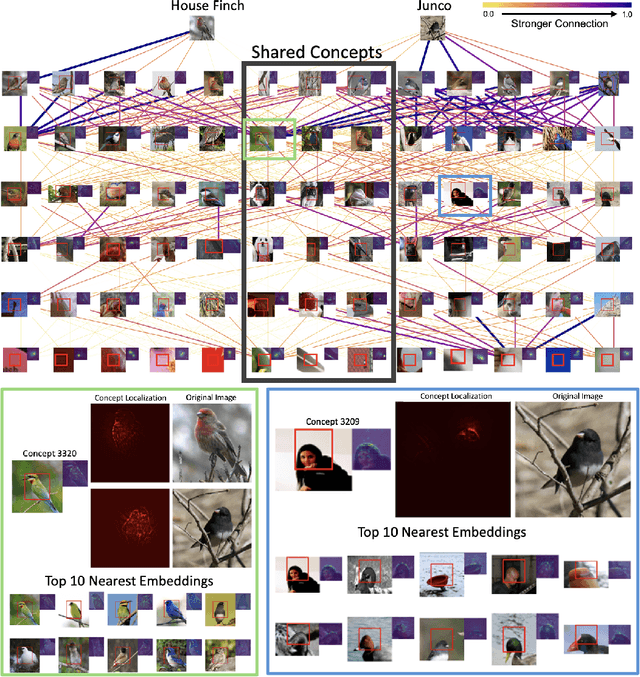
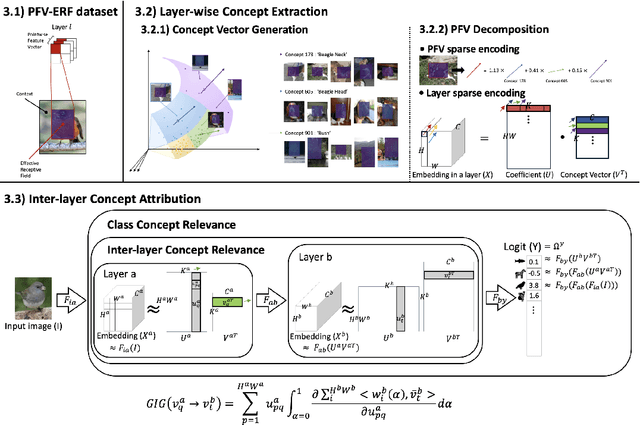

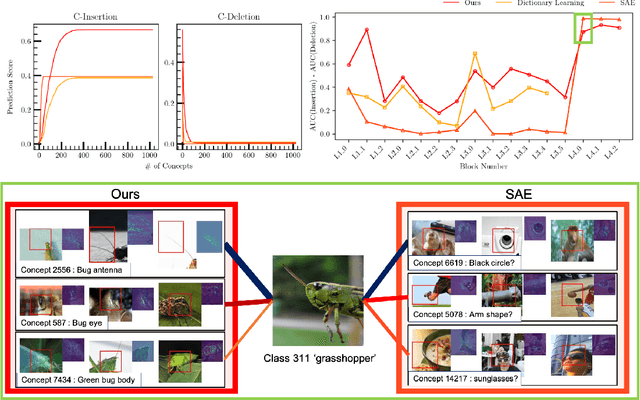
In the field of eXplainable AI (XAI) in language models, the progression from local explanations of individual decisions to global explanations with high-level concepts has laid the groundwork for mechanistic interpretability, which aims to decode the exact operations. However, this paradigm has not been adequately explored in image models, where existing methods have primarily focused on class-specific interpretations. This paper introduces a novel approach to systematically trace the entire pathway from input through all intermediate layers to the final output within the whole dataset. We utilize Pointwise Feature Vectors (PFVs) and Effective Receptive Fields (ERFs) to decompose model embeddings into interpretable Concept Vectors. Then, we calculate the relevance between concept vectors with our Generalized Integrated Gradients (GIG), enabling a comprehensive, dataset-wide analysis of model behavior. We validate our method of concept extraction and concept attribution in both qualitative and quantitative evaluations. Our approach advances the understanding of semantic significance within image models, offering a holistic view of their operational mechanics.