 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVDPP: Video Depth Post-Processing for Speed and Scalability
Apr 08, 2026Video depth estimation is essential for providing 3D scene structure in applications ranging from autonomous driving to mixed reality. Current end-to-end video depth models have established state-of-the-art performance. Although current end-to-end (E2E) models have achieved state-of-the-art performance, they function as tightly coupled systems that suffer from a significant adaptation lag whenever superior single-image depth estimators are released. To mitigate this issue, post-processing methods such as NVDS offer a modular plug-and-play alternative to incorporate any evolving image depth model without retraining. However, existing post-processing methods still struggle to match the efficiency and practicality of E2E systems due to limited speed, accuracy, and RGB reliance. In this work, we revitalize the role of post-processing by proposing VDPP (Video Depth Post-Processing), a framework that improves the speed and accuracy of post-processing methods for video depth estimation. By shifting the paradigm from computationally expensive scene reconstruction to targeted geometric refinement, VDPP operates purely on geometric refinements in low-resolution space. This design achieves exceptional speed (>43.5 FPS on NVIDIA Jetson Orin Nano) while matching the temporal coherence of E2E systems, with dense residual learning driving geometric representations rather than full reconstructions. Furthermore, our VDPP's RGB-free architecture ensures true scalability, enabling immediate integration with any evolving image depth model. Our results demonstrate that VDPP provides a superior balance of speed, accuracy, and memory efficiency, making it the most practical solution for real-time edge deployment. Our project page is at https://github.com/injun-baek/VDPP
Bi-ICE: An Inner Interpretable Framework for Image Classification via Bi-directional Interactions between Concept and Input Embeddings
Nov 26, 2024
Inner interpretability is a promising field focused on uncovering the internal mechanisms of AI systems and developing scalable, automated methods to understand these systems at a mechanistic level. While significant research has explored top-down approaches starting from high-level problems or algorithmic hypotheses and bottom-up approaches building higher-level abstractions from low-level or circuit-level descriptions, most efforts have concentrated on analyzing large language models. Moreover, limited attention has been given to applying inner interpretability to large-scale image tasks, primarily focusing on architectural and functional levels to visualize learned concepts. In this paper, we first present a conceptual framework that supports inner interpretability and multilevel analysis for large-scale image classification tasks. We introduce the Bi-directional Interaction between Concept and Input Embeddings (Bi-ICE) module, which facilitates interpretability across the computational, algorithmic, and implementation levels. This module enhances transparency by generating predictions based on human-understandable concepts, quantifying their contributions, and localizing them within the inputs. Finally, we showcase enhanced transparency in image classification, measuring concept contributions and pinpointing their locations within the inputs. Our approach highlights algorithmic interpretability by demonstrating the process of concept learning and its convergence.
Decompose the model: Mechanistic interpretability in image models with Generalized Integrated Gradients (GIG)
Sep 03, 2024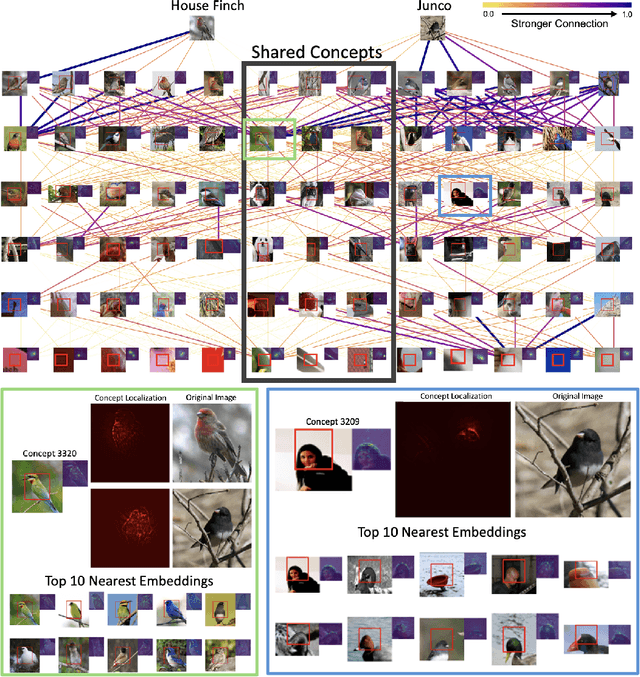
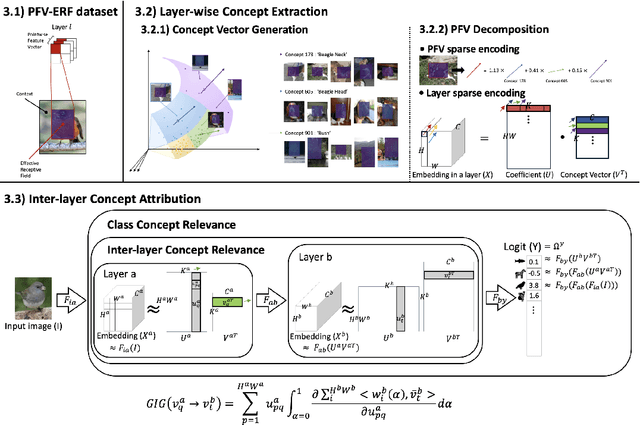

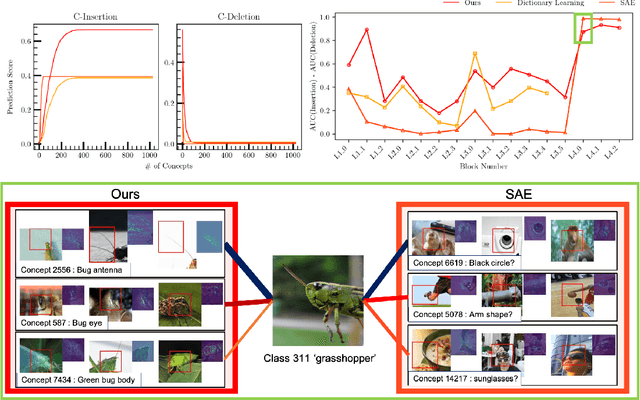
In the field of eXplainable AI (XAI) in language models, the progression from local explanations of individual decisions to global explanations with high-level concepts has laid the groundwork for mechanistic interpretability, which aims to decode the exact operations. However, this paradigm has not been adequately explored in image models, where existing methods have primarily focused on class-specific interpretations. This paper introduces a novel approach to systematically trace the entire pathway from input through all intermediate layers to the final output within the whole dataset. We utilize Pointwise Feature Vectors (PFVs) and Effective Receptive Fields (ERFs) to decompose model embeddings into interpretable Concept Vectors. Then, we calculate the relevance between concept vectors with our Generalized Integrated Gradients (GIG), enabling a comprehensive, dataset-wide analysis of model behavior. We validate our method of concept extraction and concept attribution in both qualitative and quantitative evaluations. Our approach advances the understanding of semantic significance within image models, offering a holistic view of their operational mechanics.
Respect the model: Fine-grained and Robust Explanation with Sharing Ratio Decomposition
Jan 25, 2024



The truthfulness of existing explanation methods in authentically elucidating the underlying model's decision-making process has been questioned. Existing methods have deviated from faithfully representing the model, thus susceptible to adversarial attacks. To address this, we propose a novel eXplainable AI (XAI) method called SRD (Sharing Ratio Decomposition), which sincerely reflects the model's inference process, resulting in significantly enhanced robustness in our explanations. Different from the conventional emphasis on the neuronal level, we adopt a vector perspective to consider the intricate nonlinear interactions between filters. We also introduce an interesting observation termed Activation-Pattern-Only Prediction (APOP), letting us emphasize the importance of inactive neurons and redefine relevance encapsulating all relevant information including both active and inactive neurons. Our method, SRD, allows for the recursive decomposition of a Pointwise Feature Vector (PFV), providing a high-resolution Effective Receptive Field (ERF) at any layer.