 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROODI: Reconstructing Occluded Objects with Denoising Inpainters
Mar 13, 2025



While the quality of novel-view images has improved dramatically with 3D Gaussian Splatting, extracting specific objects from scenes remains challenging. Isolating individual 3D Gaussian primitives for each object and handling occlusions in scenes remain far from being solved. We propose a novel object extraction method based on two key principles: (1) being object-centric by pruning irrelevant primitives; and (2) leveraging generative inpainting to compensate for missing observations caused by occlusions. For pruning, we analyze the local structure of primitives using K-nearest neighbors, and retain only relevant ones. For inpainting, we employ an off-the-shelf diffusion-based inpainter combined with occlusion reasoning, utilizing the 3D representation of the entire scene. Our findings highlight the crucial synergy between pruning and inpainting, both of which significantly enhance extraction performance. We evaluate our method on a standard real-world dataset and introduce a synthetic dataset for quantitative analysis. Our approach outperforms the state-of-the-art, demonstrating its effectiveness in object extraction from complex scenes.
ViVid-1-to-3: Novel View Synthesis with Video Diffusion Models
Dec 03, 2023Generating novel views of an object from a single image is a challenging task. It requires an understanding of the underlying 3D structure of the object from an image and rendering high-quality, spatially consistent new views. While recent methods for view synthesis based on diffusion have shown great progress, achieving consistency among various view estimates and at the same time abiding by the desired camera pose remains a critical problem yet to be solved. In this work, we demonstrate a strikingly simple method, where we utilize a pre-trained video diffusion model to solve this problem. Our key idea is that synthesizing a novel view could be reformulated as synthesizing a video of a camera going around the object of interest -- a scanning video -- which then allows us to leverage the powerful priors that a video diffusion model would have learned. Thus, to perform novel-view synthesis, we create a smooth camera trajectory to the target view that we wish to render, and denoise using both a view-conditioned diffusion model and a video diffusion model. By doing so, we obtain a highly consistent novel view synthesis, outperforming the state of the art.
Differentiable SLAM Helps Deep Learning-based LiDAR Perception Tasks
Sep 17, 2023



We investigate a new paradigm that uses differentiable SLAM architectures in a self-supervised manner to train end-to-end deep learning models in various LiDAR based applications. To the best of our knowledge there does not exist any work that leverages SLAM as a training signal for deep learning based models. We explore new ways to improve the efficiency, robustness, and adaptability of LiDAR systems with deep learning techniques. We focus on the potential benefits of differentiable SLAM architectures for improving performance of deep learning tasks such as classification, regression as well as SLAM. Our experimental results demonstrate a non-trivial increase in the performance of two deep learning applications - Ground Level Estimation and Dynamic to Static LiDAR Translation, when used with differentiable SLAM architectures. Overall, our findings provide important insights that enhance the performance of LiDAR based navigation systems. We demonstrate that this new paradigm of using SLAM Loss signal while training LiDAR based models can be easily adopted by the community.
Robust, High-Precision GNSS Carrier-Phase Positioning with Visual-Inertial Fusion
Mar 02, 2023



Robust, high-precision global localization is fundamental to a wide range of outdoor robotics applications. Conventional fusion methods use low-accuracy pseudorange based GNSS measurements ($>>5m$ errors) and can only yield a coarse registration to the global earth-centered-earth-fixed (ECEF) frame. In this paper, we leverage high-precision GNSS carrier-phase positioning and aid it with local visual-inertial odometry (VIO) tracking using an extended Kalman filter (EKF) framework that better resolves the integer ambiguity concerned with GNSS carrier-phase. %to achieve centimeter-level accuracy in the ECEF frame. We also propose an algorithm for accurate GNSS-antenna-to-IMU extrinsics calibration to accurately align VIO to the ECEF frame. Together, our system achieves robust global positioning demonstrated by real-world hardware experiments in severely occluded urban canyons, and outperforms the state-of-the-art RTKLIB by a significant margin in terms of integer ambiguity solution fix rate and positioning RMSE accuracy.
Generalized Data Weighting via Class-level Gradient Manipulation
Oct 29, 2021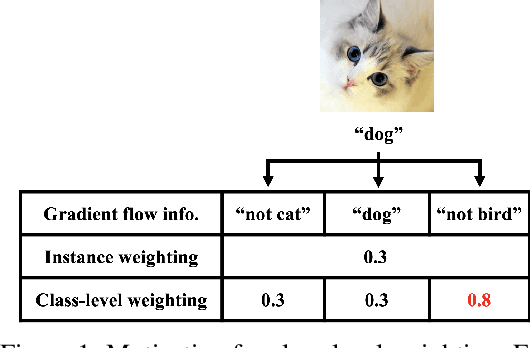



Label noise and class imbalance are two major issues coexisting in real-world datasets. To alleviate the two issues, state-of-the-art methods reweight each instance by leveraging a small amount of clean and unbiased data. Yet, these methods overlook class-level information within each instance, which can be further utilized to improve performance. To this end, in this paper, we propose Generalized Data Weighting (GDW) to simultaneously mitigate label noise and class imbalance by manipulating gradients at the class level. To be specific, GDW unrolls the loss gradient to class-level gradients by the chain rule and reweights the flow of each gradient separately. In this way, GDW achieves remarkable performance improvement on both issues. Aside from the performance gain, GDW efficiently obtains class-level weights without introducing any extra computational cost compared with instance weighting methods. Specifically, GDW performs a gradient descent step on class-level weights, which only relies on intermediate gradients. Extensive experiments in various settings verify the effectiveness of GDW. For example, GDW outperforms state-of-the-art methods by $2.56\%$ under the $60\%$ uniform noise setting in CIFAR10. Our code is available at https://github.com/GGchen1997/GDW-NIPS2021.