 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoost: A Unified and Scalable Diffusion Transformer for Bidirectional Virtual Try-On and Try-Off
Aug 06, 2025Virtual try-on aims to synthesize a realistic image of a person wearing a target garment, but accurately modeling garment-body correspondence remains a persistent challenge, especially under pose and appearance variation. In this paper, we propose Voost - a unified and scalable framework that jointly learns virtual try-on and try-off with a single diffusion transformer. By modeling both tasks jointly, Voost enables each garment-person pair to supervise both directions and supports flexible conditioning over generation direction and garment category, enhancing garment-body relational reasoning without task-specific networks, auxiliary losses, or additional labels. In addition, we introduce two inference-time techniques: attention temperature scaling for robustness to resolution or mask variation, and self-corrective sampling that leverages bidirectional consistency between tasks. Extensive experiments demonstrate that Voost achieves state-of-the-art results on both try-on and try-off benchmarks, consistently outperforming strong baselines in alignment accuracy, visual fidelity, and generalization.
Towards Multi-domain Face Landmark Detection with Synthetic Data from Diffusion model
Jan 24, 2024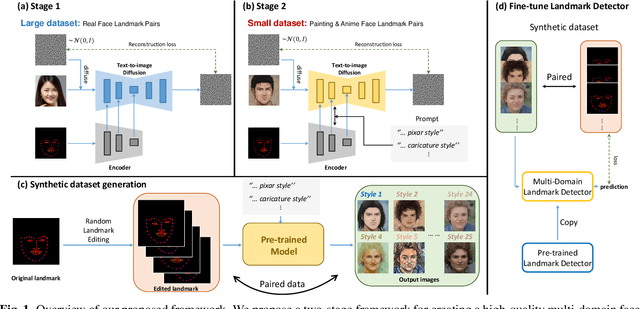
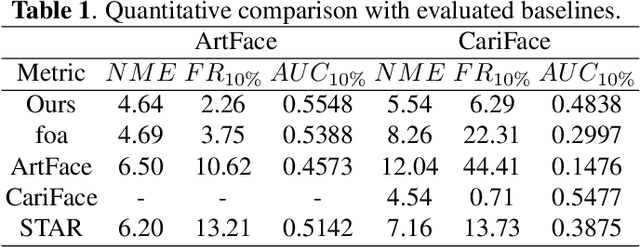

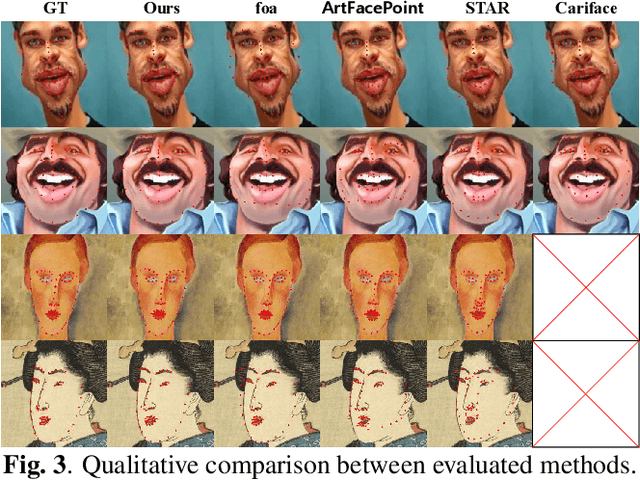
Recently, deep learning-based facial landmark detection for in-the-wild faces has achieved significant improvement. However, there are still challenges in face landmark detection in other domains (e.g. cartoon, caricature, etc). This is due to the scarcity of extensively annotated training data. To tackle this concern, we design a two-stage training approach that effectively leverages limited datasets and the pre-trained diffusion model to obtain aligned pairs of landmarks and face in multiple domains. In the first stage, we train a landmark-conditioned face generation model on a large dataset of real faces. In the second stage, we fine-tune the above model on a small dataset of image-landmark pairs with text prompts for controlling the domain. Our new designs enable our method to generate high-quality synthetic paired datasets from multiple domains while preserving the alignment between landmarks and facial features. Finally, we fine-tuned a pre-trained face landmark detection model on the synthetic dataset to achieve multi-domain face landmark detection. Our qualitative and quantitative results demonstrate that our method outperforms existing methods on multi-domain face landmark detection.
ViVid-1-to-3: Novel View Synthesis with Video Diffusion Models
Dec 03, 2023Generating novel views of an object from a single image is a challenging task. It requires an understanding of the underlying 3D structure of the object from an image and rendering high-quality, spatially consistent new views. While recent methods for view synthesis based on diffusion have shown great progress, achieving consistency among various view estimates and at the same time abiding by the desired camera pose remains a critical problem yet to be solved. In this work, we demonstrate a strikingly simple method, where we utilize a pre-trained video diffusion model to solve this problem. Our key idea is that synthesizing a novel view could be reformulated as synthesizing a video of a camera going around the object of interest -- a scanning video -- which then allows us to leverage the powerful priors that a video diffusion model would have learned. Thus, to perform novel-view synthesis, we create a smooth camera trajectory to the target view that we wish to render, and denoise using both a view-conditioned diffusion model and a video diffusion model. By doing so, we obtain a highly consistent novel view synthesis, outperforming the state of the art.
DIFAI: Diverse Facial Inpainting using StyleGAN Inversion
Jan 20, 2023Image inpainting is an old problem in computer vision that restores occluded regions and completes damaged images. In the case of facial image inpainting, most of the methods generate only one result for each masked image, even though there are other reasonable possibilities. To prevent any potential biases and unnatural constraints stemming from generating only one image, we propose a novel framework for diverse facial inpainting exploiting the embedding space of StyleGAN. Our framework employs pSp encoder and SeFa algorithm to identify semantic components of the StyleGAN embeddings and feed them into our proposed SPARN decoder that adopts region normalization for plausible inpainting. We demonstrate that our proposed method outperforms several state-of-the-art methods.
Controllable Face Manipulation and UV Map Generation by Self-supervised Learning
Sep 24, 2022

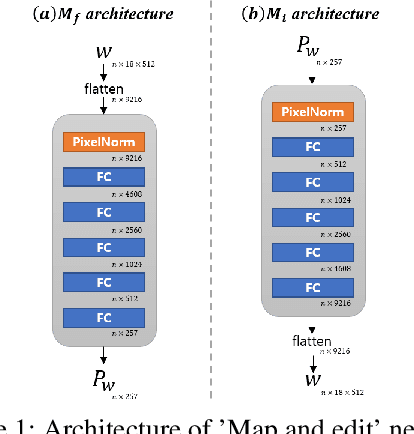
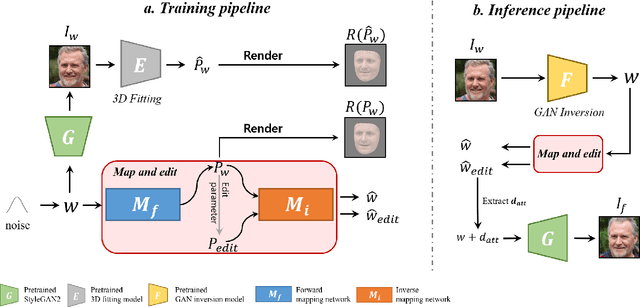
Although manipulating facial attributes by Generative Adversarial Networks (GANs) has been remarkably successful recently, there are still some challenges in explicit control of features such as pose, expression, lighting, etc. Recent methods achieve explicit control over 2D images by combining 2D generative model and 3DMM. However, due to the lack of realism and clarity in texture reconstruction by 3DMM, there is a domain gap between the synthetic image and the rendered image of 3DMM. Since rendered 3DMM images contain facial region only without the background, directly computing the loss between these two domains is not ideal and the resultant trained model will be biased. In this study, we propose to explicitly edit the latent space of the pretrained StyleGAN by controlling the parameters of the 3DMM. To address the domain gap problem, we propose a noval network called 'Map and edit' and a simple but effective attribute editing method to avoid direct loss computation between rendered and synthesized images. Furthermore, since our model can accurately generate multi-view face images while the identity remains unchanged. As a by-product, combined with visibility masks, our proposed model can also generate texture-rich and high-resolution UV facial textures. Our model relies on pretrained StyleGAN, and the proposed model is trained in a self-supervised manner without any manual annotations or datasets.
Injecting 3D Perception of Controllable NeRF-GAN into StyleGAN for Editable Portrait Image Synthesis
Jul 26, 2022

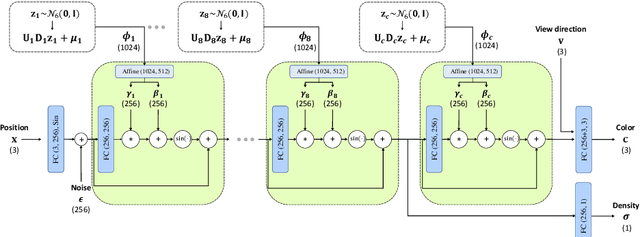
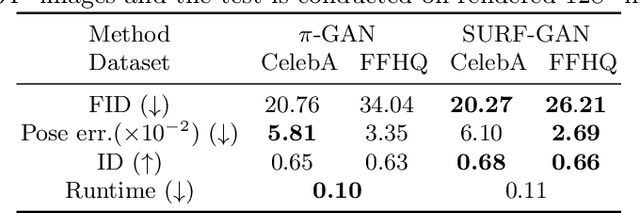
Over the years, 2D GANs have achieved great successes in photorealistic portrait generation. However, they lack 3D understanding in the generation process, thus they suffer from multi-view inconsistency problem. To alleviate the issue, many 3D-aware GANs have been proposed and shown notable results, but 3D GANs struggle with editing semantic attributes. The controllability and interpretability of 3D GANs have not been much explored. In this work, we propose two solutions to overcome these weaknesses of 2D GANs and 3D-aware GANs. We first introduce a novel 3D-aware GAN, SURF-GAN, which is capable of discovering semantic attributes during training and controlling them in an unsupervised manner. After that, we inject the prior of SURF-GAN into StyleGAN to obtain a high-fidelity 3D-controllable generator. Unlike existing latent-based methods allowing implicit pose control, the proposed 3D-controllable StyleGAN enables explicit pose control over portrait generation. This distillation allows direct compatibility between 3D control and many StyleGAN-based techniques (e.g., inversion and stylization), and also brings an advantage in terms of computational resources. Our codes are available at https://github.com/jgkwak95/SURF-GAN.
Generate and Edit Your Own Character in a Canonical View
May 06, 2022

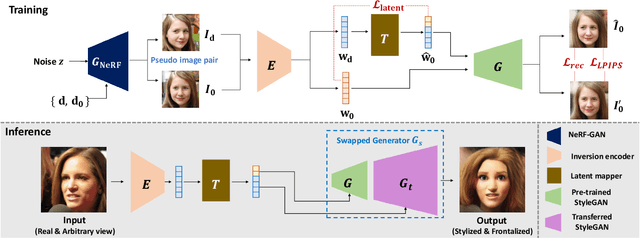

Recently, synthesizing personalized characters from a single user-given portrait has received remarkable attention as a drastic popularization of social media and the metaverse. The input image is not always in frontal view, thus it is important to acquire or predict canonical view for 3D modeling or other applications. Although the progress of generative models enables the stylization of a portrait, obtaining the stylized image in canonical view is still a challenging task. There have been several studies on face frontalization but their performance significantly decreases when input is not in the real image domain, e.g., cartoon or painting. Stylizing after frontalization also results in degenerated output. In this paper, we propose a novel and unified framework which generates stylized portraits in canonical view. With a proposed latent mapper, we analyze and discover frontalization mapping in a latent space of StyleGAN to stylize and frontalize at once. In addition, our model can be trained with unlabelled 2D image sets, without any 3D supervision. The effectiveness of our method is demonstrated by experimental results.
Efficient dynamic filter for robust and low computational feature extraction
May 03, 2022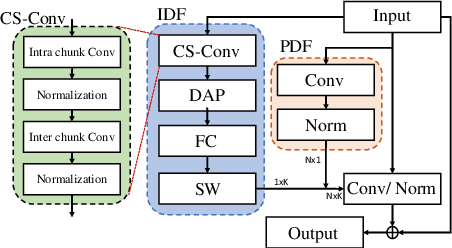
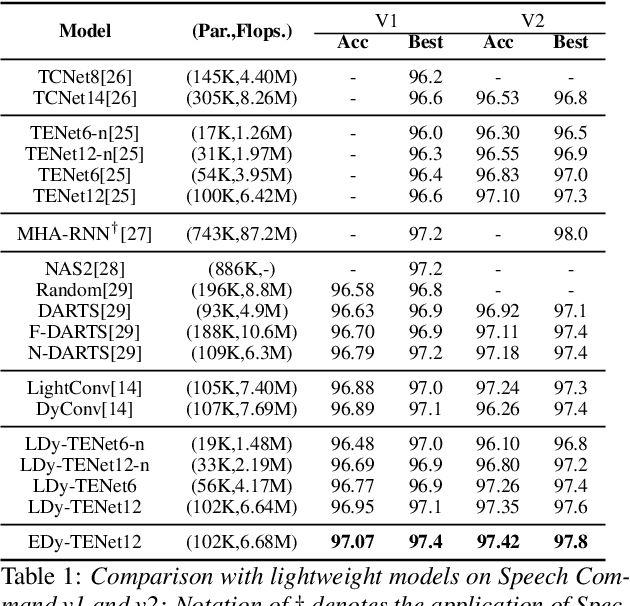
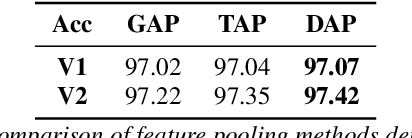
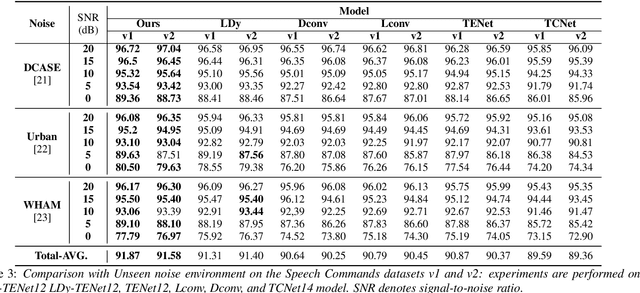
Unseen noise signal which is not considered in a model training process is difficult to anticipate and would lead to performance degradation. Various methods have been investigated to mitigate unseen noise. In our previous work, an Instance-level Dynamic Filter (IDF) and a Pixel Dynamic Filter (PDF) were proposed to extract noise-robust features. However, the performance of the dynamic filter might be degraded since simple feature pooling is used to reduce the computational resource in the IDF part. In this paper, we propose an efficient dynamic filter to enhance the performance of the dynamic filter. Instead of utilizing the simple feature mean, we separate Time-Frequency (T-F) features as non-overlapping chunks, and separable convolutions are carried out for each feature direction (inter chunks and intra chunks). Additionally, we propose Dynamic Attention Pooling that maps high dimensional features as low dimensional feature embeddings. These methods are applied to the IDF for keyword spotting and speaker verification tasks. We confirm that our proposed method performs better in unseen environments (unseen noise and unseen speakers) than state-of-the-art models.
Adverse Weather Image Translation with Asymmetric and Uncertainty-aware GAN
Dec 08, 2021
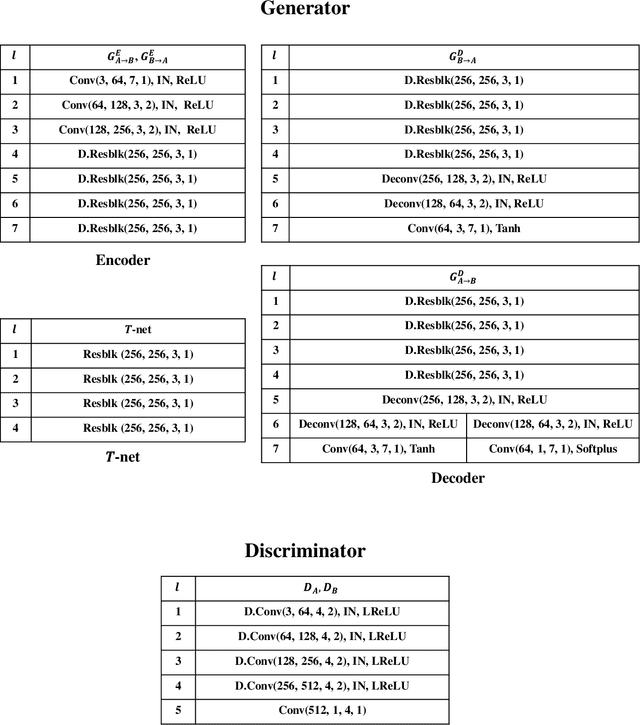


Adverse weather image translation belongs to the unsupervised image-to-image (I2I) translation task which aims to transfer adverse condition domain (eg, rainy night) to standard domain (eg, day). It is a challenging task because images from adverse domains have some artifacts and insufficient information. Recently, many studies employing Generative Adversarial Networks (GANs) have achieved notable success in I2I translation but there are still limitations in applying them to adverse weather enhancement. Symmetric architecture based on bidirectional cycle-consistency loss is adopted as a standard framework for unsupervised domain transfer methods. However, it can lead to inferior translation result if the two domains have imbalanced information. To address this issue, we propose a novel GAN model, i.e., AU-GAN, which has an asymmetric architecture for adverse domain translation. We insert a proposed feature transfer network (${T}$-net) in only a normal domain generator (i.e., rainy night-> day) to enhance encoded features of the adverse domain image. In addition, we introduce asymmetric feature matching for disentanglement of encoded features. Finally, we propose uncertainty-aware cycle-consistency loss to address the regional uncertainty of a cyclic reconstructed image. We demonstrate the effectiveness of our method by qualitative and quantitative comparisons with state-of-the-art models. Codes are available at https://github.com/jgkwak95/AU-GAN.
Lightweight dynamic filter for keyword spotting
Sep 27, 2021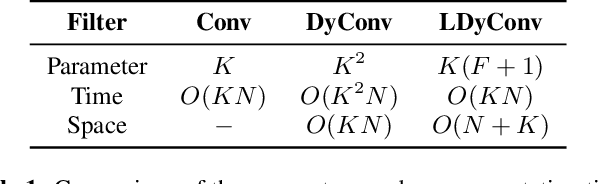
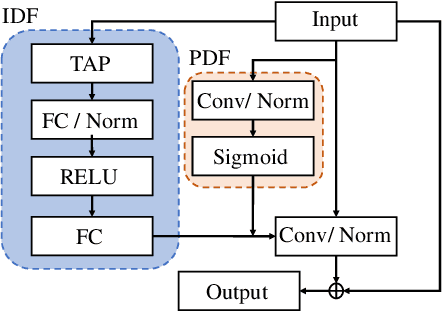
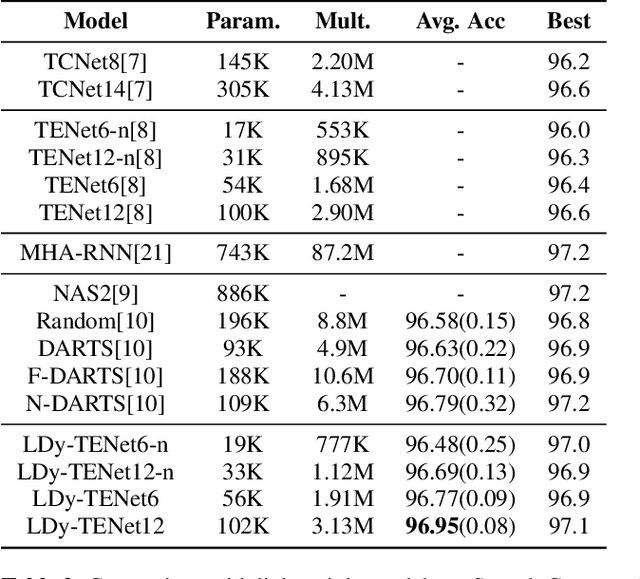
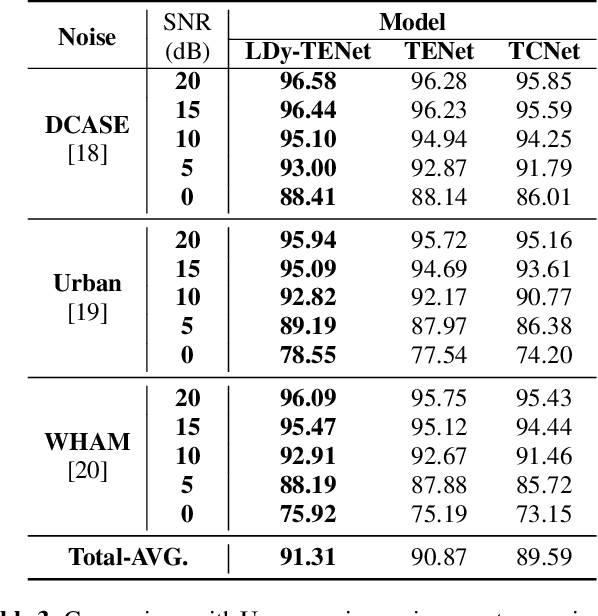
Keyword Spotting (KWS) from speech signal is widely applied for being fully hands free speech recognition. The KWS network is designed as a small footprint model to be constantly monitored. Recently, dynamic filter based models are applied in deep learning applications to enhance a system's robustness or accuracy. However, as a dynamic filter framework requires high computational cost, the usage is limited to the condition of the device. In this paper, we proposed a lightweight dynamic filter to improve the performance of KWS. Our proposed model divides dynamic filter as two branches to reduce the computational complexity. This lightweight dynamic filter is applied to the front-end of KWS to enhance the separability of the input data. The experiments show that our model is robustly working on unseen noise and small training data environment by using small computational resource.